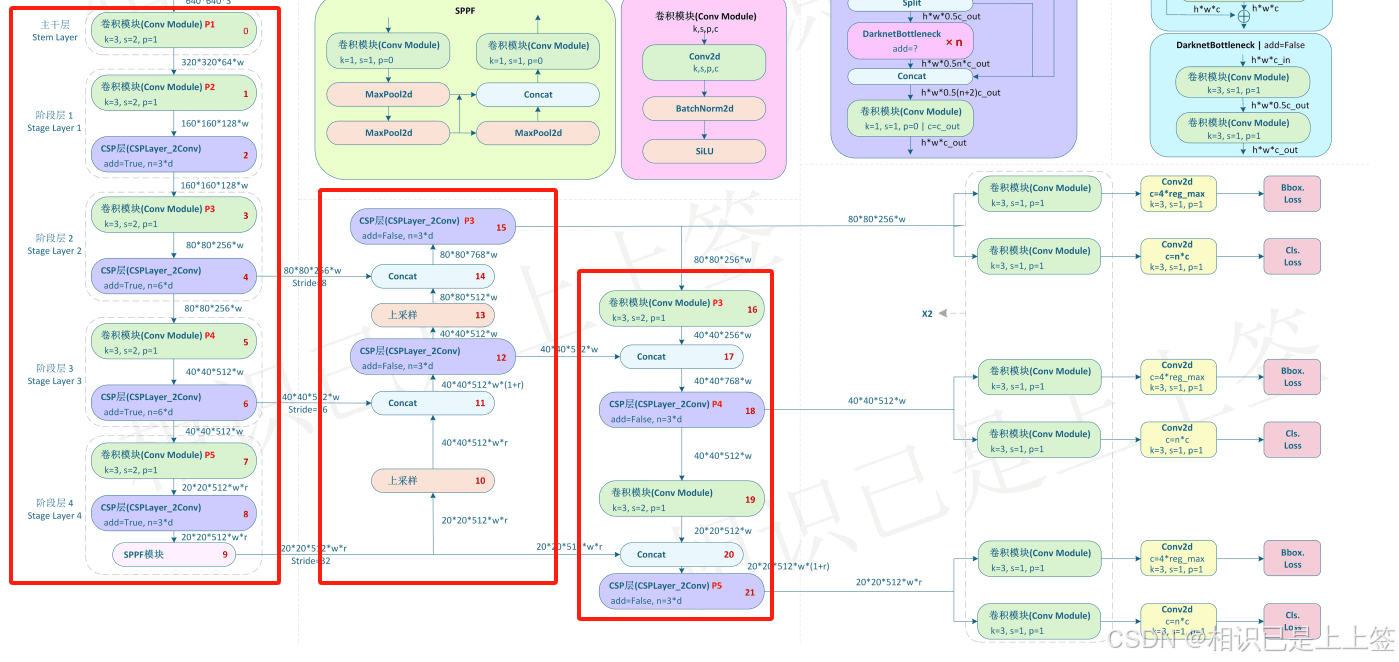
一、yolov8的pytorch网络结构
model detectionmodel(
(model): sequential(
(0): conv(
(conv): conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(1): conv(
(conv): conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(2): c2f(
(cv1): conv(
(conv): conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(3): conv(
(conv): conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(4): c2f(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-5): 6 x bottleneck(
(cv1): conv(
(conv): conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(5): conv(
(conv): conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(6): c2f(
(cv1): conv(
(conv): conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-5): 6 x bottleneck(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(7): conv(
(conv): conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(8): c2f(
(cv1): conv(
(conv): conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1280, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(9): sppf(
(cv1): conv(
(conv): conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): maxpool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=false)
)
(10): upsample(scale_factor=2.0, mode='nearest')
(11): concat()
(12): c2f(
(cv1): conv(
(conv): conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1280, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(13): upsample(scale_factor=2.0, mode='nearest')
(14): concat()
(15): c2f(
(cv1): conv(
(conv): conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(640, 256, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(16): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(17): concat()
(18): c2f(
(cv1): conv(
(conv): conv2d(768, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1280, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(19): conv(
(conv): conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): silu(inplace=true)
)
(20): concat()
(21): c2f(
(cv1): conv(
(conv): conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(1280, 512, kernel_size=(1, 1), stride=(1, 1))
(act): silu(inplace=true)
)
(m): modulelist(
(0-2): 3 x bottleneck(
(cv1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(cv2): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
)
)
)
(22): postdetect(
(cv2): modulelist(
(0): sequential(
(0): conv(
(conv): conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(1): conv(
(conv): conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(2): conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1-2): 2 x sequential(
(0): conv(
(conv): conv2d(512, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(1): conv(
(conv): conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(2): conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(cv3): modulelist(
(0): sequential(
(0): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(2): conv2d(256, 35, kernel_size=(1, 1), stride=(1, 1))
)
(1-2): 2 x sequential(
(0): conv(
(conv): conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(1): conv(
(conv): conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): silu(inplace=true)
)
(2): conv2d(256, 35, kernel_size=(1, 1), stride=(1, 1))
)
)
(dfl): dfl(
(conv): conv2d(16, 1, kernel_size=(1, 1), stride=(1, 1), bias=false)
)
)
)
)yolov8网络从1-21层与pt文件相对应是backbone和neck模块,22层是head模块。
二、转onnx步骤
2.1 yolov8官方
"""
代码解释
pt模型转为onnx格式
"""
import os
from ultralytics import yolo
model = yolo("weights/best.pt")
success = model.export(format="onnx")
print("导出成功!")
将pytorch转为onnx后,pytorch支持的一系列计算就会转为onnx所支持的算子,若没有相对应的就会使用其他方式进行替换(比如多个计算替换其单个)。比较常见是conv和silu合并成一个conv模块进行。
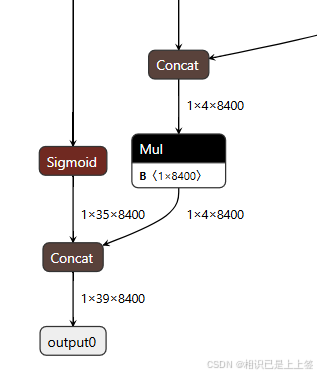
其中,1*4*8400表示每张图片预测 8400 个候选框,每个框有 4 个参数边界框坐标 (x,y,w,h)。 1*35*8400类同,1和4800代表意义相同,35是类别属性包含了其置信度概率值。
最后两个输出concat操作,得到1*39*8400。最后根据这个结果去进行后续操作。
2.2 自定义转换
所谓的自定义转换其实是在转onnx时,对1*39*8400多加了一系列自定义操作例如nms等。
2.2.1 加载权重并优化结构
yolov8 = yolo(args.weights) #替换为自己的权重 model = yolov8.model.fuse().eval()
2.2.2 后处理检测模块
def gen_anchors(feats: tensor,
strides: tensor,
grid_cell_offset: float = 0.5) -> tuple[tensor, tensor]:
"""
生成锚点,并计算每个锚点的步幅。
参数:
feats (tensor): 特征图,通常来自不同的网络层。
strides (tensor): 每个特征图的步幅(stride)。
grid_cell_offset (float): 网格单元的偏移量,默认为0.5。
返回:
tuple[tensor, tensor]: 锚点的坐标和对应的步幅张量。
"""
anchor_points, stride_tensor = [], []
assert feats is not none # 确保输入的特征图不为空
dtype, device = feats[0].dtype, feats[0].device # 获取特征图的数据类型和设备
# 遍历每个特征图,计算锚点
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape # 获取特征图的高(h)和宽(w)
sx = torch.arange(end=w, device=device,
dtype=dtype) + grid_cell_offset # 计算 x 轴上的锚点位置
sy = torch.arange(end=h, device=device,
dtype=dtype) + grid_cell_offset # 计算 y 轴上的锚点位置
sy, sx = torch.meshgrid(sy, sx) # 生成网格坐标
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2)) # 将 x 和 y 组合成坐标点
stride_tensor.append(
torch.full((h * w, 1), stride, dtype=dtype, device=device)) # 生成步幅张量
return torch.cat(anchor_points), torch.cat(stride_tensor) # 返回合并后的锚点和步幅
class customize_nms(torch.autograd.function):
"""
继承torch.autograd.function
用于tensorrt的非极大值抑制(nms)自定义函数。
"""
@staticmethod
def forward(
ctx: graph,
boxes: tensor,
scores: tensor,
iou_threshold: float = 0.65,
score_threshold: float = 0.25,
max_output_boxes: int = 100,
background_class: int = -1,
box_coding: int = 0,
plugin_version: str = '1',
score_activation: int = 0
) -> tuple[tensor, tensor, tensor, tensor]:
"""
正向计算nms输出,模拟真实的tensorrt nms过程。
参数:
boxes (tensor): 预测的边界框。
scores (tensor): 预测框的置信度分数。
其他参数同样为nms的超参数。
返回:
tuple[tensor, tensor, tensor, tensor]: 包含检测框数量、框坐标、置信度分数和类别标签。
"""
batch_size, num_boxes, num_classes = scores.shape # 获取批量大小、框数量和类别数
num_dets = torch.randint(0,
max_output_boxes, (batch_size, 1),
dtype=torch.int32) # 随机生成检测框数量(仅为模拟)
boxes = torch.randn(batch_size, max_output_boxes, 4) # 随机生成预测框
scores = torch.randn(batch_size, max_output_boxes) # 随机生成分数
labels = torch.randint(0,
num_classes, (batch_size, max_output_boxes),
dtype=torch.int32) # 随机生成类别标签
return num_dets, boxes, scores, labels # 返回模拟的结果
@staticmethod
def symbolic(
g,
boxes: value,
scores: value,
iou_threshold: float = 0.45,
score_threshold: float = 0.25,
max_output_boxes: int = 100,
background_class: int = -1,
box_coding: int = 0,
score_activation: int = 0,
plugin_version: str = '1') -> tuple[value, value, value, value]:
"""
计算图的符号函数,供tensorrt使用。
参数:
g: 计算图对象
boxes (value), scores (value): 传入的边界框和得分
其他参数是用于配置nms的参数。
返回:
经过nms处理的检测框、得分、类别标签及检测框数量。
"""
out = g.op('trt::efficientnms_trt',
boxes,
scores,
iou_threshold_f=iou_threshold,
score_threshold_f=score_threshold,
max_output_boxes_i=max_output_boxes,
background_class_i=background_class,
box_coding_i=box_coding,
plugin_version_s=plugin_version,
score_activation_i=score_activation,
outputs=4) # 使用tensorrt的efficientnms插件
nums_dets, boxes, scores, classes = out # 获取输出的检测框数量、框坐标、得分和类别
return nums_dets, boxes, scores, classes # 返回结果
class post_process_detect(nn.module):
"""
用于后处理的检测模块,执行检测后的非极大值抑制(nms)。
"""
export = true
shape = none
dynamic = false
iou_thres = 0.65 # 默认的iou阈值
conf_thres = 0.25 # 默认的置信度阈值
topk = 100 # 输出的最大检测框数量
def __init__(self, *args, **kwargs):
super().__init__()
def forward(self, x):
"""
执行后处理操作,提取预测框、置信度和类别。
参数:
x (tensor): 输入的特征图。
返回:
tuple[tensor, tensor, tensor]: 预测框、置信度和类别。
"""
shape = x[0].shape # 获取输入的形状
b, res, b_reg_num = shape[0], [], self.reg_max * 4
# b为特征列表第一个元素的批量大小,表示处理的样本数量,
# res声明一个空列表存储处理过的特征图
# b_reg_num为回归框的数量
#遍历特征层(self.nl表示特征层数),将每一层的框预测和分类预测拼接。
for i in range(self.nl):
res.append(torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)) # 特征拼接
# 调用
# make_anchors
# 生成锚点和步幅,用于还原边界框的绝对坐标。
if self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(
0, 1) for x in gen_anchors(x, self.stride, 0.5)) # 生成锚点和步幅
self.shape = shape # 更新输入的形状
x = [i.view(b, self.no, -1) for i in res] # 调整特征图形状
y = torch.cat(x, 2) # 拼接所有特征图
boxes, scores = y[:, :b_reg_num, ...], y[:, b_reg_num:, ...].sigmoid() # 提取框和分数
boxes = boxes.view(b, 4, self.reg_max, -1).permute(0, 1, 3, 2) # 变换框的形状
boxes = boxes.softmax(-1) @ torch.arange(self.reg_max).to(boxes) # 对框进行softmax处理
boxes0, boxes1 = -boxes[:, :2, ...], boxes[:, 2:, ...] # 分离框的不同部分
boxes = self.anchors.repeat(b, 2, 1) + torch.cat([boxes0, boxes1], 1) # 合并框坐标
boxes = boxes * self.strides # 乘以步幅
return customize_nms.apply(boxes.transpose(1, 2), scores.transpose(1, 2),
self.iou_thres, self.conf_thres, self.topk) # 执行nms
def optim(module: nn.module):
setattr(module, '__class__', post_process_detect)
for item in model.modules():
optim(item)
item.to(args.device) #输入cpu或者gpu的卡号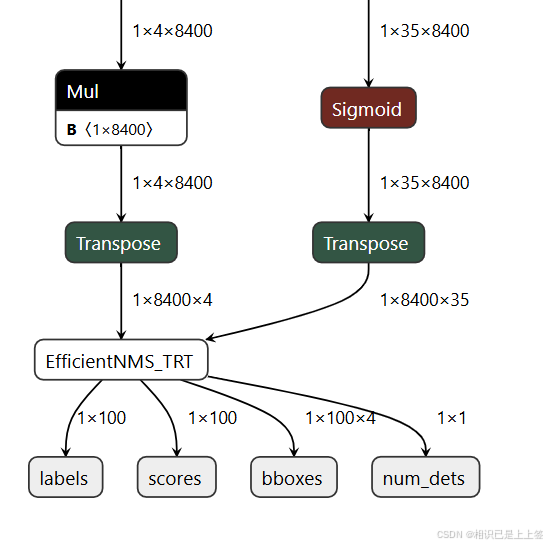
自定义这里是在yolo官方得到的1*4*8400和1*35*8400进行矩阵转换2<->3,最后引入efficientnms_trt插件后处理,可以有效加速nms处理。
2.2.3 efficientnms_trt插件
efficientnms_trt 是 tensorrt 中的一个高效非极大值抑制 (nms) 插件,用于快速过滤检测框。它通过优化的 cuda 实现来执行 nms 操作,特别适合于深度学习推理阶段中目标检测任务的后处理。支持在一个批次中对多个图像同时执行 nms。
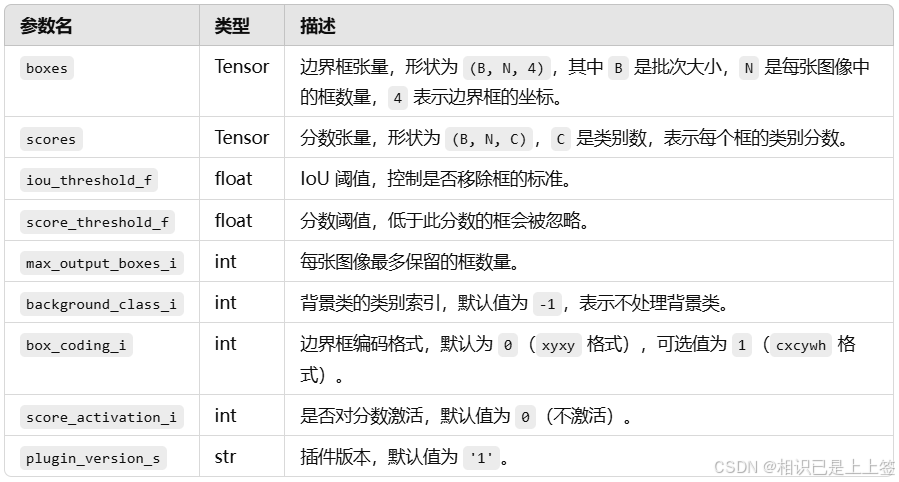
输出结果为num_dets, detection_boxes, detection_scores, detection_classes ,分别代表经过 nms 筛选后保留的边界框数,每张图片保留的检测框的坐标,每张图片中保留下来的检测框的分数(由高到低),每个保留下来的边界框的类别索引。
三、结语
到此这篇关于yolov8模型pytorch格式转为onnx格式的文章就介绍到这了,更多相关yolov8模型pytorch转onnx格式内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!



发表评论