semantic kernel简介
玩过大语言模型(llm)的都知道openai,然后微软azure也提供了openai的服务:azure openai,只需要申请到api key,就可以使用这些ai服务。使用方式可以是通过在线web页面直接与ai聊天,也可以调用ai的api服务,将ai的能力集成到自己的应用程序中。不过这些服务都是在线提供的,都会需要根据token计费,所以不仅需要依赖互联网,而且在使用上会有一定成本。于是,就出现了像ollama这样的本地大语言模型服务,只要你的电脑足够强悍,应用场景允许的情况下,使用本地大语言模型也是一个不错的选择。
既然有这么多ai服务可以选择,那如果在我的应用程序中需要能够很方便地对接不同的ai服务,应该怎么做呢?这就是semantic kernel的基本功能,它是一个基于大语言模型开发应用程序的框架,可以让你的应用程序更加方便地集成大语言模型。semantic kernel可用于轻松生成 ai 代理并将最新的 ai 模型集成到 c#、python 或 java 代码库中。因此,它虽然在.net ai生态中扮演着非常重要的角色,但它是支持多编程语言跨平台的应用开发套件。
semantic kernel主要包含以下这些核心概念:
- 连接(connection):与外部 ai 服务和数据源交互,比如在应用程序中实现open ai和ollama的无缝整合
- 插件(plugins):封装应用程序可以使用的功能,比如增强提示词功能,为大语言模型提供更多的上下文信息
- 规划器(planner):根据用户行为编排执行计划和策略
- 内存(memory):抽象并简化 ai 应用程序的上下文管理,比如文本向量(text embedding)的存储等
有关semantic kernel的具体介绍可以参考微软官方文档。
演练:通过semantic kernel使用microsoft azure openai service
话不多说,直接实操。这个演练的目的,就是使用部署在azure上的gpt-4o大语言模型来实现一个简单的问答系统。
微软于2024年10月21日终止面向个人用户的azure openai服务,企业用户仍能继续使用。参考:https://finance.sina.com.cn/roll/2024-10-18/doc-incsymyx4982064.shtml
在azure中部署大语言模型
登录azure portal,新建一个azure ai service,然后点击go to azure openai studio,进入openai studio:
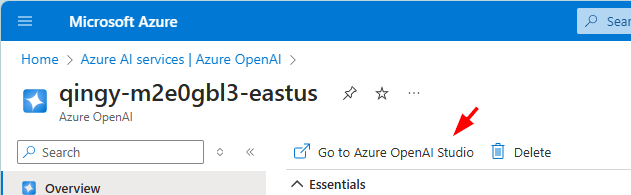
进入后,在左侧侧边栏的共享资源部分,选择部署标签页,然后在模型部署页面,点击部署模型按钮,在下拉的菜单中,选择部署基本模型:
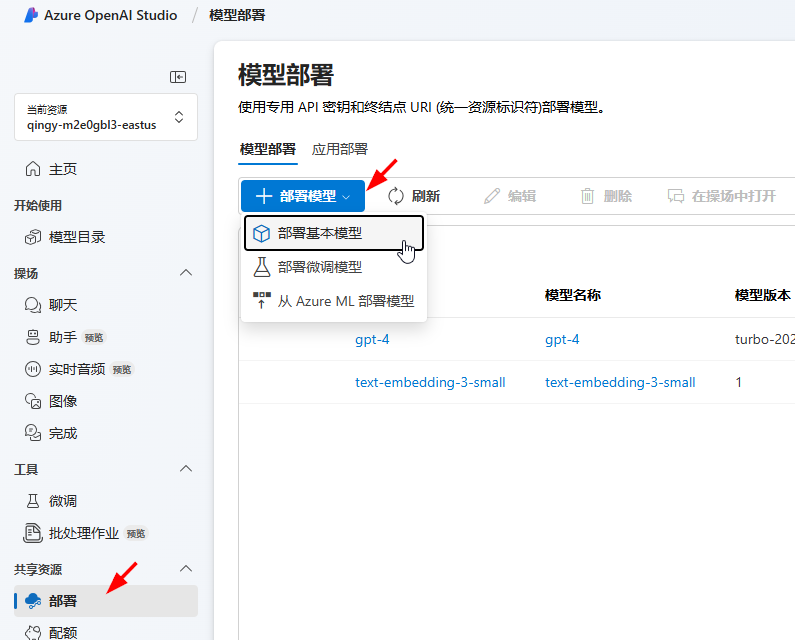
在选择模型对话框中,选择gpt-4o,然后点击确认按钮:
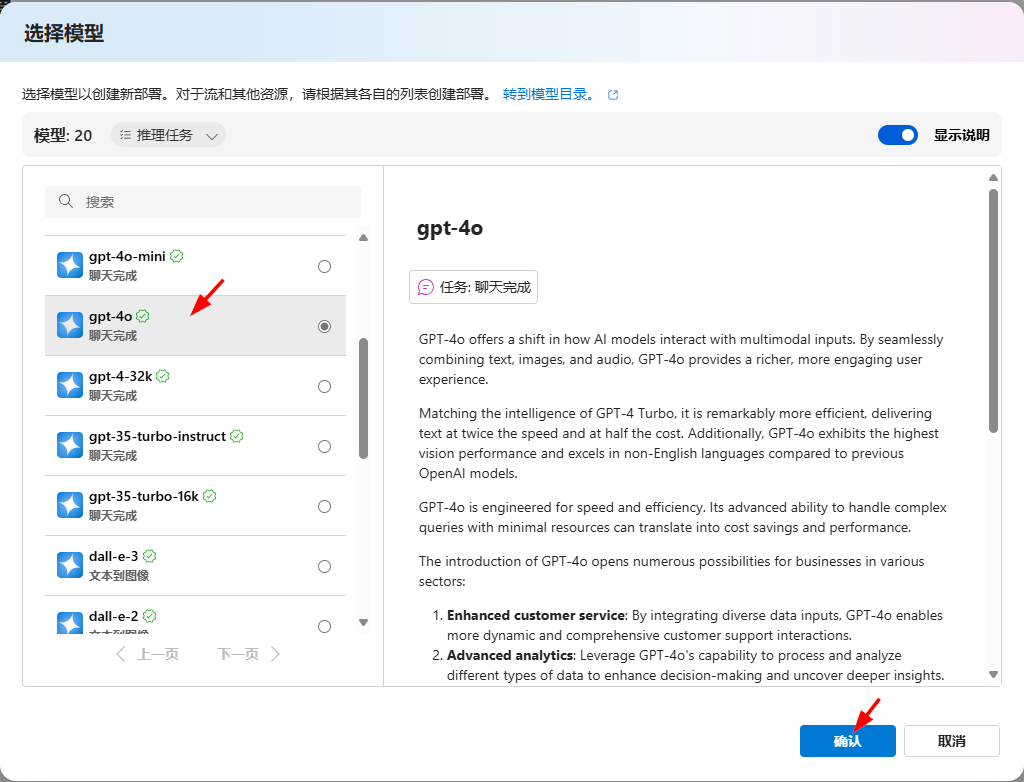
在弹出的对话框部署模型 gpt-4o中,给模型取个名字,然后直接点击部署按钮,如果希望对模型版本、安全性等做一些设置,也可以点击自定义按钮展开选项。
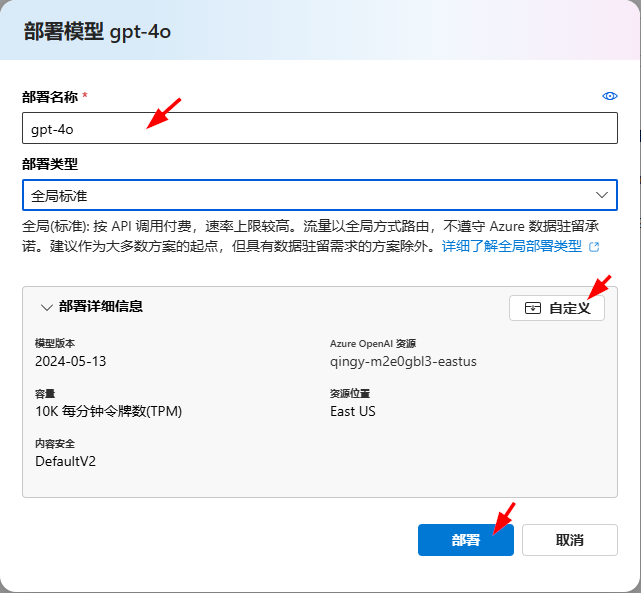
部署成功后,就可以在模型部署页面的列表中看到已部署模型的版本以及状态:
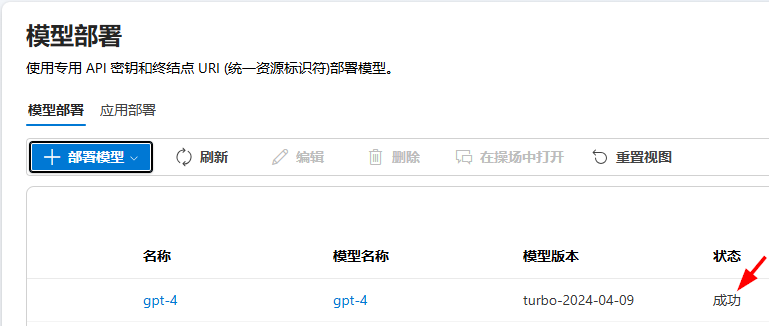
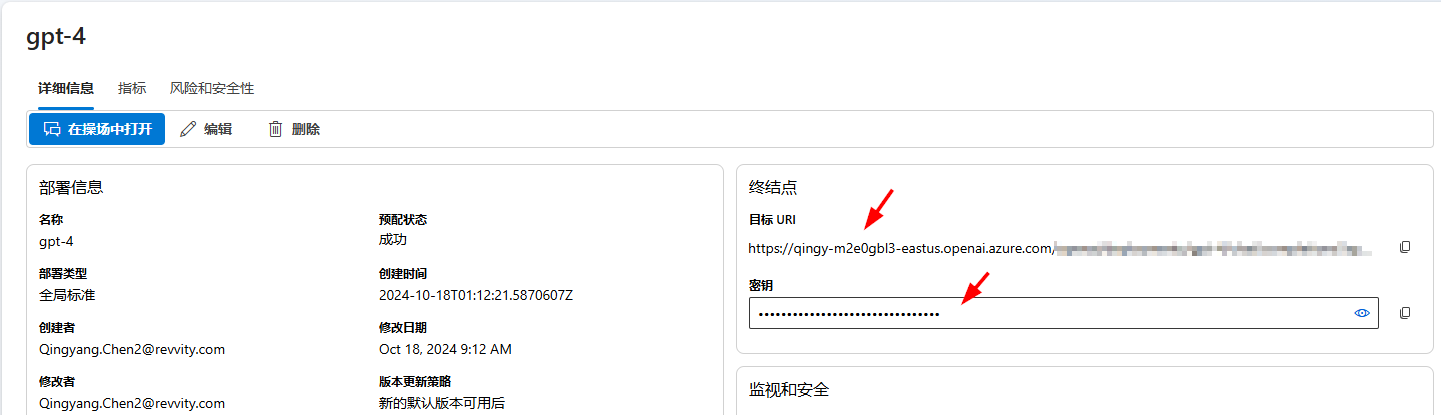
点击新部署的模型的名称,进入模型详细信息页面,在页面的终结点部分,把目标uri和密钥复制下来,待会要用。目标uri只需要复制主机名部分即可,比如https://qingy-m2e0gbl3-eastus.openai.azure.com这样:
在c#中使用semantic kernel实现问答应用
首先创建一个控制台应用程序,然后添加microsoft.semantickernel nuget包的引用:
$ dotnet new console --name chatapp $ dotnet add package microsoft.semantickernel
然后编辑program.cs文件,加入下面的代码:
using microsoft.semantickernel;
using microsoft.semantickernel.chatcompletion;
using system.text;
var apikey = environment.getenvironmentvariable("azureopenaiapikey")!;
// 初始化semantic kernel
var kernel = kernel.createbuilder()
.addazureopenaichatcompletion(
"gpt-4",
"https://qingy-m2e0gbl3-eastus.openai.azure.com",
apikey)
.build();
// 创建一个对话完成服务以及对话历史对象,用来保存对话历史,以便后续为大模型
// 提供对话上下文信息。
var chatcompletionservice = kernel.getrequiredservice<ichatcompletionservice>();
var chat = new chathistory("你是一个ai助手,帮助人们查找信息和回答问题");
stringbuilder chatresponse = new();
while (true)
{
console.write("请输入问题>> ");
// 将用户输入的问题添加到对话中
chat.addusermessage(console.readline()!);
chatresponse.clear();
// 获取大语言模型的反馈,并将结果逐字输出
await foreach (var message in
chatcompletionservice.getstreamingchatmessagecontentsasync(chat))
{
// 输出当前获取的结果字符串
console.write(message);
// 将输出内容添加到临时变量中
chatresponse.append(message.content);
}
console.writeline();
// 在进入下一次问答之前,将当前回答结果添加到对话历史中,为大语言模型提供问答上下文
chat.addassistantmessage(chatresponse.tostring());
console.writeline();
}
在上面的代码中,需要将你的api key和终结点uri配置进去,为了安全性,这里我使用环境变量保存api key,然后由程序读入。为了让大语言模型能够了解在一次对话中,我和它之间都讨论了什么内容,在代码中,使用一个stringbuilder临时保存了当前对话的应答结果,然后将这个结果又通过semantic kernel的addassistantmessage方法加回到对话中,以便在下一次对话中,大语言模型能够知道我们在聊什么话题。
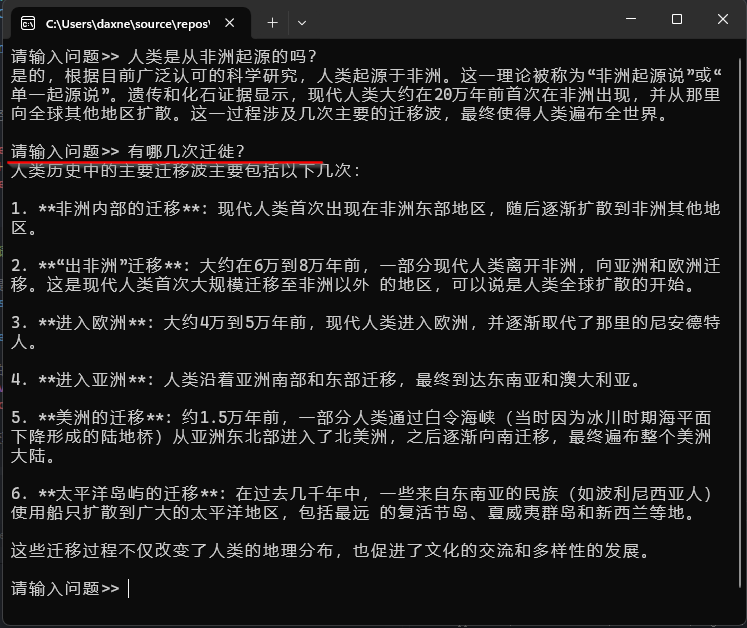
比如下面的例子中,在第二次提问时我问到“有那几次迁徙?”,ai能知道我是在说人类历史上的大迁徙,然后将我想要的答案列举出来:
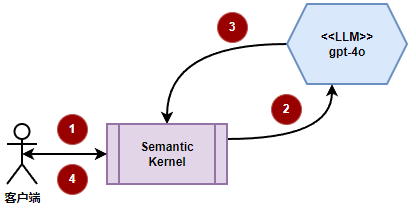
到这里,一个简单的基于gpt-4o的问答应用就完成了,它的工作流程大致如下:
ai能回答所有的问题吗?
由于这里使用的gpt-4o大语言模型是在今年5月份发布的,而大语言模型都是基于现有数据经过训练得到的,所以,它应该不会知道5月份以后的事情,遇到这样的问题,ai只能回答不知道,或者给出一个比较离谱的答案:
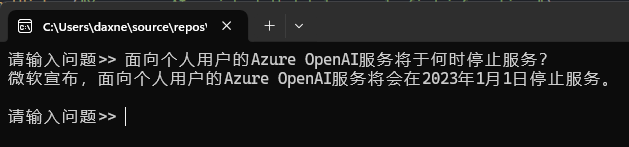
你或许会想,那我将这些知识或者新闻文章下载下来,然后基于上面的代码,将这些信息先添加到对话历史中,让大语言模型能够了解上下文,这样回答问题的时候准确率不是提高了吗?这个思路是对的,可以在进行问答之前,将新闻的文本信息添加到对话历史中:
using microsoft.semantickernel;
using microsoft.semantickernel.chatcompletion;
using system.text;
using microsoft.semantickernel.connectors.azureopenai;
using microsoft.semantickernel.memory;
using microsoft.semantickernel.text;
#pragma warning disable skexp0010, skexp0001, skexp0050
const string collectionname = "latestnews";
var apikey = environment.getenvironmentvariable("azureopenaiapikey")!;
// 初始化semantic kernel
var kernel = kernel.createbuilder()
.addazureopenaichatcompletion(
"gpt-4",
"https://qingy-m2e0gbl3-eastus.openai.azure.com",
apikey)
.build();
// 创建文本向量生成服务
var textembeddinggenerationservice = new azureopenaitextembeddinggenerationservice(
"text-embedding-3-small",
"https://qingy-m2e0gbl3-eastus.openai.azure.com",
apikey);
// 创建用于保存文本向量的内存向量数据库
var memory = new memorybuilder()
.withmemorystore(new volatilememorystore())
.withtextembeddinggeneration(textembeddinggenerationservice)
.build();
// 从外部文件以markdown格式读入内容,然后根据语义产生多个段落
var markdowncontent = await file.readalltextasync(@"input.md");
var paragraphs =
textchunker.splitmarkdownparagraphs(
textchunker.splitmarkdownlines(markdowncontent.replace("\r\n", " "), 128),
64);
// 将各个段落进行量化并保存到向量数据库
for (var i = 0; i < paragraphs.count; i++)
{
await memory.saveinformationasync(collectionname, paragraphs[i], $"paragraph{i}");
}
// 创建一个对话完成服务以及对话历史对象,用来保存对话历史,以便后续为大模型
// 提供对话上下文信息。
var chatcompletionservice = kernel.getrequiredservice<ichatcompletionservice>();
var chat = new chathistory("你是一个ai助手,帮助人们查找信息和回答问题");
stringbuilder additionalinfo = new();
stringbuilder chatresponse = new();
while (true)
{
console.write("请输入问题>> ");
var question = console.readline()!;
additionalinfo.clear();
// 从向量数据库中找到跟提问最为相近的3条信息,将其添加到对话历史中
await foreach (var hit in memory.searchasync(collectionname, question, limit: 3))
{
additionalinfo.appendline(hit.metadata.text);
}
var contextlinestoremove = -1;
if (additionalinfo.length != 0)
{
additionalinfo.insert(0, "以下是一些附加信息:");
contextlinestoremove = chat.count;
chat.addusermessage(additionalinfo.tostring());
}
// 将用户输入的问题添加到对话中
chat.addusermessage(question);
chatresponse.clear();
// 获取大语言模型的反馈,并将结果逐字输出
await foreach (var message in
chatcompletionservice.getstreamingchatmessagecontentsasync(chat))
{
// 输出当前获取的结果字符串
console.write(message);
// 将输出内容添加到临时变量中
chatresponse.append(message.content);
}
console.writeline();
// 在进入下一次问答之前,将当前回答结果添加到对话历史中,为大语言模型提供问答上下文
chat.addassistantmessage(chatresponse.tostring());
// 将当次问题相关的内容从对话历史中移除
if (contextlinestoremove >= 0) chat.removeat(contextlinestoremove);
console.writeline();
}但是这样做,会造成下面的异常信息:
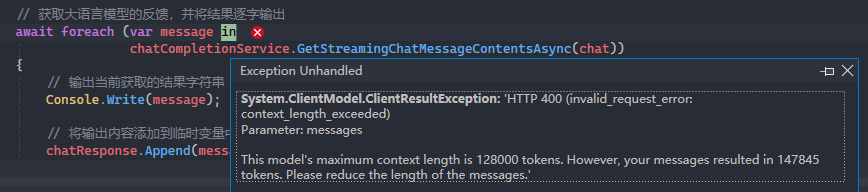
这个问题其实就跟大语言模型的context window有关。当今所有的大语言模型在一次数据处理上都有一定的限制,这个限制就是context window,在这个例子中,我们的模型一次最多处理12万8千个token(token是大语言模型的数据处理单元,它可以是一个词组,一个单词或者是一个字符),而我们却输入了147,845个token,于是就报错了。很明显,我们应该减少传入的数据量,但这样又没办法把完整的新闻文章信息发送给大语言模型。此时就要用到“检索增强生成(rag)”。
semantic kernel的检索增强生成(rag)实践
其实,并不一定非要把整篇新闻文章发给大语言模型,可以换个思路:只需要在新闻文章中摘出跟提问相关的内容发送给大语言模型就可以了,这样就可以大大减小需要发送到大语言模型的token数量。所以,这里就出现了额外的一些步骤:
- 对大量的文档进行预处理,将文本信息量化并保存下来(text embedding)
- 在提出新问题时,根据问题语义,从保存的文本量化信息(embeddings)中,找到与问题相关的信息
- 将这些信息发送给大语言模型,并从大语言模型获得应答
- 将结果反馈给调用方
流程大致如下:
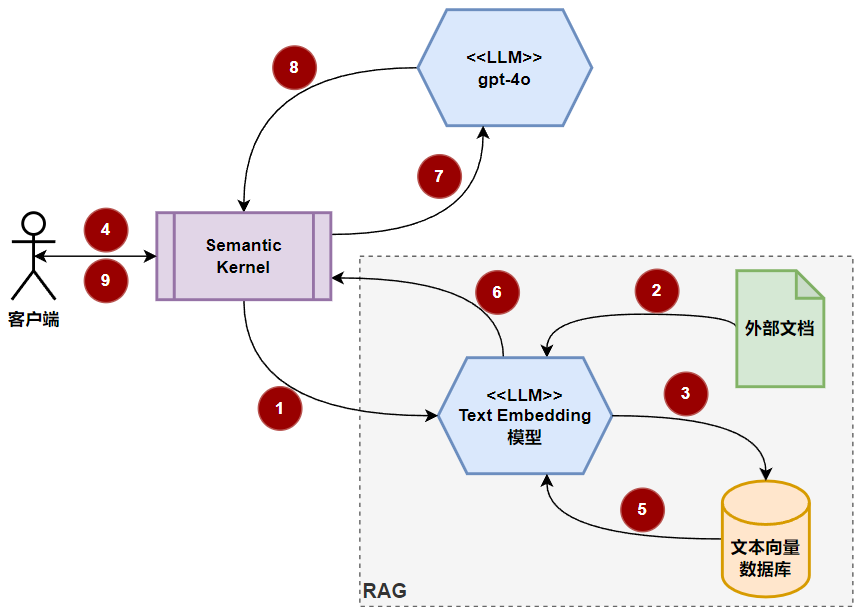
虚线灰色框中就是检索增强生成(rag)相关流程,这里就不针对每个标号一一说明了,能够理解上面所述的4个大的步骤,就很好理解这张图中的整体流程。下面我们直接使用semantic kernel,通过rag来增强模型应答。
首先,在azure openai studio中,按照上文的步骤,部署一个text-embedding-3-small的模型,同样将终结点uri和api key记录下来,然后,在项目中添加microsoft.semantickernel.plugins.memory nuget包的引用,因为我们打算先使用基于内存的文本向量数据库来运行我们的代码。semantic kernel支持多种向量数据库,比如sqlite,azure ai search,chroma,milvus,pinecone,qdrant,weaviate等等。在添加引用的时候,需要使用--prerelease参数,因为microsoft.semantickernel.plugins.memory包目前还处于alpha阶段。
将上面的代码改成下面的形式:
using microsoft.semantickernel;
using microsoft.semantickernel.chatcompletion;
using system.text;
using microsoft.semantickernel.connectors.azureopenai;
using microsoft.semantickernel.memory;
using microsoft.semantickernel.text;
#pragma warning disable skexp0010, skexp0001, skexp0050
const string collectionname = "latestnews";
var apikey = environment.getenvironmentvariable("azureopenaiapikey")!;
// 初始化semantic kernel
var kernel = kernel.createbuilder()
.addazureopenaichatcompletion(
"gpt-4",
"https://qingy-m2e0gbl3-eastus.openai.azure.com",
apikey)
.build();
// 创建文本向量生成服务
var textembeddinggenerationservice = new azureopenaitextembeddinggenerationservice(
"text-embedding-3-small",
"https://qingy-m2e0gbl3-eastus.openai.azure.com",
apikey);
// 创建用于保存文本向量的内存向量数据库
var memory = new memorybuilder()
.withmemorystore(new volatilememorystore())
.withtextembeddinggeneration(textembeddinggenerationservice)
.build();
// 从外部文件以markdown格式读入内容,然后根据语义产生多个段落
var markdowncontent = await file.readalltextasync(@"input.md");
var paragraphs =
textchunker.splitmarkdownparagraphs(
textchunker.splitmarkdownlines(markdowncontent.replace("\r\n", " "), 128),
64);
// 将各个段落进行量化并保存到向量数据库
for (var i = 0; i < paragraphs.count; i++)
{
await memory.saveinformationasync(collectionname, paragraphs[i], $"paragraph{i}");
}
// 创建一个对话完成服务以及对话历史对象,用来保存对话历史,以便后续为大模型
// 提供对话上下文信息。
var chatcompletionservice = kernel.getrequiredservice<ichatcompletionservice>();
var chat = new chathistory("你是一个ai助手,帮助人们查找信息和回答问题");
stringbuilder additionalinfo = new();
stringbuilder chatresponse = new();
while (true)
{
console.write("请输入问题>> ");
var question = console.readline()!;
additionalinfo.clear();
// 从向量数据库中找到跟提问最为相近的3条信息,将其添加到对话历史中
await foreach (var hit in memory.searchasync(collectionname, question, limit: 3))
{
additionalinfo.appendline(hit.metadata.text);
}
var contextlinestoremove = -1;
if (additionalinfo.length != 0)
{
additionalinfo.insert(0, "以下是一些附加信息:");
contextlinestoremove = chat.count;
chat.addusermessage(additionalinfo.tostring());
}
// 将用户输入的问题添加到对话中
chat.addusermessage(question);
chatresponse.clear();
// 获取大语言模型的反馈,并将结果逐字输出
await foreach (var message in
chatcompletionservice.getstreamingchatmessagecontentsasync(chat))
{
// 输出当前获取的结果字符串
console.write(message);
// 将输出内容添加到临时变量中
chatresponse.append(message.content);
}
console.writeline();
// 在进入下一次问答之前,将当前回答结果添加到对话历史中,为大语言模型提供问答上下文
chat.addassistantmessage(chatresponse.tostring());
// 将当次问题相关的内容从对话历史中移除
if (contextlinestoremove >= 0) chat.removeat(contextlinestoremove);
console.writeline();
}重新运行程序,然后提出同样的问题,可以看到,现在的答案就正确了:
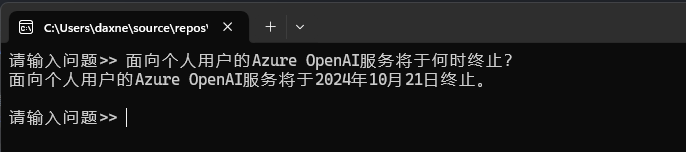
现在看看向量数据库中到底有什么。新添加一个对microsoft.semantickernel.connectors.sqlite nuget包的引用,然后,将上面代码的:
.withmemorystore(new volatilememorystore())
改为:
.withmemorystore(await sqlitememorystore.connectasync("vectors.db"))重新运行程序,执行成功后,在bin\debug\net8.0目录下,可以找到vectors.db文件,用sqlite查看工具(我用的是sqlitestudio)打开数据库文件,可以看到下面的表和数据:
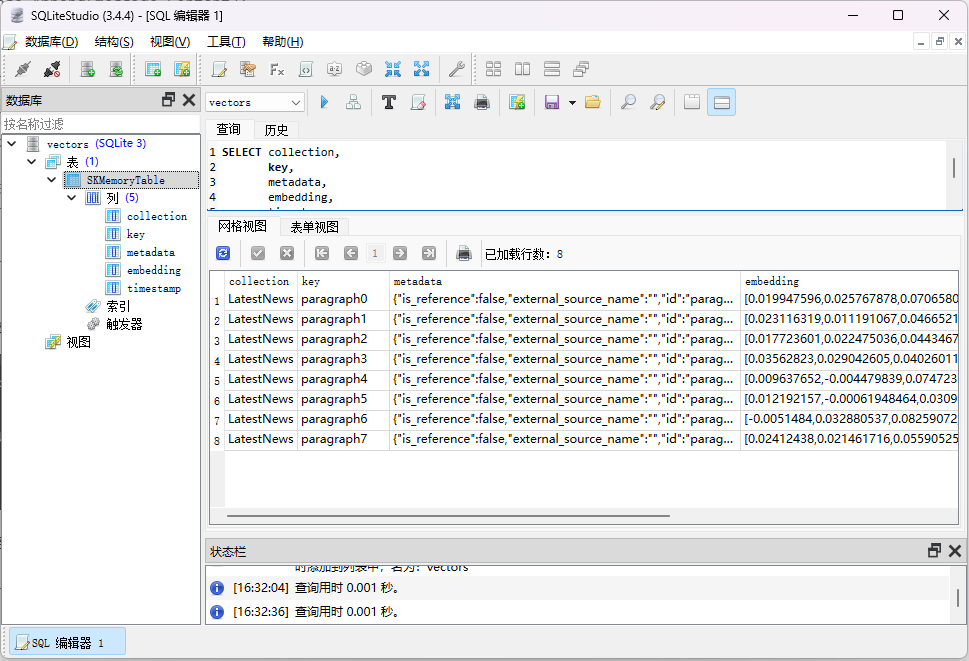
metadata字段保存的就是每个段落的原始数据信息,而embedding字段则是文本向量,其实它就是一系列的浮点值,代表着文本之间在语义上的距离。
使用基于ollama的本地大语言模型
semantic kernel现在已经可以支持ollama本地大语言模型了,虽然它目前也还是预览版。可以在项目中通过添加microsoft.semantickernel.connectors.ollama nuget包来体验。建议安装最新版本的ollama,然后,下载两个大语言模型,一个是chat completion类型的,另一个是text embedding类型的。我选择了llama3.2:3b和mxbai-embed-large这两个模型:

代码上只需要将azure openai替换为ollama即可:
// 初始化semantic kernel
var kernel = kernel.createbuilder()
.addollamachatcompletion(
"llama3.2:3b",
new uri("http://localhost:11434"))
.build();
// 创建文本向量生成服务
var textembeddinggenerationservice = new ollamatextembeddinggenerationservice(
"mxbai-embed-large:latest",
new uri("http://localhost:11434"));总结
通过本文的介绍,应该可以对semantic kernel、rag以及在c#中的应用有一定的了解,虽然没有涉及原理性的内容,但基本已经可以在应用层面上提供一定的参考价值。semantic kernel虽然有些plugins还处于预览阶段,但通过本文的介绍,我们已经可以看到它的强大功能,比如,允许我们很方便地接入各种流行的向量数据库,也允许我们很方便地切换到不同的ai大语言模型服务,在ai的应用集成上,semantic kernel发挥着重要的作用。
参考
本文部分内容参考了微软官方文档《demystifying retrieval augmented generation with .net》,代码也部分参考了文中内容。文章介绍得更为详细,建议有兴趣的读者移步阅读。
到此这篇关于在c#中基于semantic kernel的检索增强生成(rag)实践的文章就介绍到这了,更多相关c#检索增强生成内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论