进行以下操作时别忘记先关闭hadoop集群
一. 没有secondarynode的解决方案
启动hadoop集群后没有secondarynode:
给hadoop集群配置环境变量时,在node1、node2、node3修改/etc/profile 忘记执行source /etc/profile生效
source /etc/profile
启动hadoop集群再jps检查进程
# 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh # 检查进程 jps
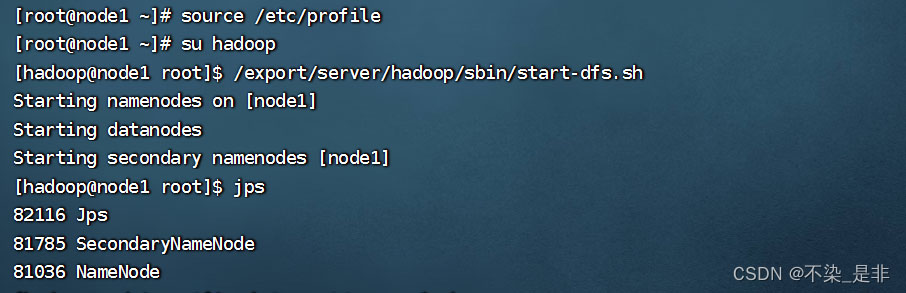
这样就有了secondarynode进程
二. 没有datanode的解决方案
启动hadoop集群后没有datanode:
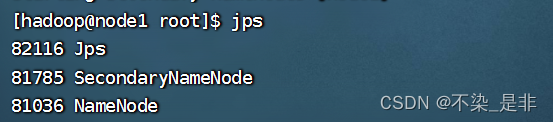
以root用户或权限 删除到hadoop安装目录下的logs下的所有文件
再删除data下的nn下的所有文件和data下的dn下的所有文件
rm -rf /export/server/hadoop/logs/* rm -rf /data/nn/* ; rm -rf /data/dn/*

删除完后记得回到hadoop用户(我是新建了个hadoop用户防止以root用户启动hadoop出现问题)格式化namenode再启动hadoop集群

# 格式化namenode hadoop namenode -format # 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh
如果不格式化namenode就会出现如下情况(namenode进程未启动)

三. 没有namenode的解决方案
启动hadoop集群后没有namenode:
格式化namenode再启动hadoop集群
# 格式化namenode hadoop namenode -format # 一键启动hdfs集群 start-dfs.sh # 一键关闭hdfs集群 stop-dfs.sh
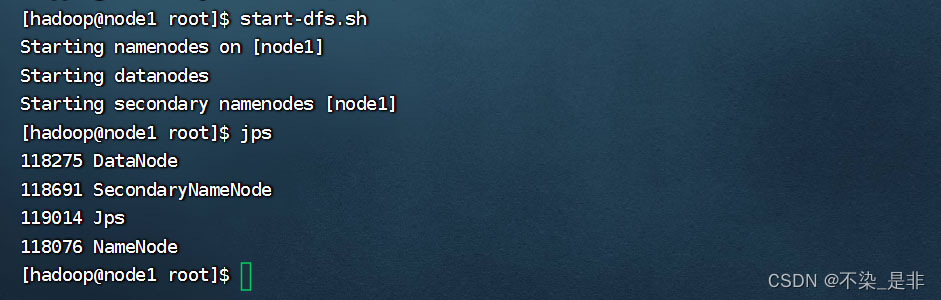
至此hadoop成功启动
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。
![解决遇到PermissionError:[Errno 13] Permission denied:XXXX错误的问题](/images/newimg/nimg3.png)


发表评论