集成es到django restful服务端项目
如果直接在django项目直接编写代码作为elasticsearch的客户端,比较复杂,所以借助第三方包haystack来对接elasticsearch的客户端。而且使用了haystack后,以后你换其他的全文搜索服务器时,也不用修改django项目已经写好的代码。
安装haystack
haystack ,django ,elasticsearch 三者之间的关系是:
- haystack 作为 django 的一个插件,提供了一个 django 应用接口来实现搜索功能。
- elasticsearch 作为 haystack 支持的搜索引擎之一,可以被 haystack 用来作为后端搜索引擎来存储和检索数据。
- 当你在 django 项目中使用 haystack 并选择 elasticsearch 作为搜索引擎时,haystack 会作为中间层,让你能够通过 django 的视图和模板来操作 elasticsearch,实现全文搜索的功能。
简单来说,haystack 为 django 提供了搜索功能的抽象层,而 elasticsearch 是这个抽象层背后的具体实现之一。通过 haystack,你可以在 django 项目中轻松地实现强大的搜索功能。
haystack是django的开源搜索框架,能够结合目前市面上大部分的搜索引擎用于实现自定义搜索功能,特别是全文搜索。
haystack支持多种搜索引擎,不仅仅是 jieba ,whoosh,使用solr、elasticsearch等搜索,也可通过haystack,而且直接切换引擎即可,甚至无需修改搜索代码。中文分词最好的就是jieba和elasticsearch+ik。
github: https://github.com/rhblind/drf-haystack
# python操作elasticsearch的模块,注意对应版本,类似pymysql pip install -u elasticsearch==7.13.4 # django开发的haystack的模块,务必先安装drf`-haystack,接着才安装django-haystack。因为drf-haystack不支持es7 pip install -u drf-haystack pip install -u django-haystack
基本使用
安装配置
文档:https://drf-haystack.readthedocs.io/en/latest/01_intro.html#examples
installed_apps = [
# 必须在自己创建的子应用前面
'haystack',
# 自己创建的子应用
]
# haystack连接elasticsearch的配置信息
haystack_connections = {
'default': {
# haystack操作es的核心模块
'engine': 'haystack.backends.elasticsearch7_backend.elasticsearch7searchengine',
# es服务端地址
'url': 'http://127.0.0.1:9200/',
# es索引仓库
'index_name': 'haystack',
},
}
# 当mysqlorm操作数据库改变时,自动更新es的索引,否则es的索引会找不到新增的数据
haystack_signal_processor = 'haystack.signals.realtimesignalprocessor'索引模型
在courses子应用下创建search_indexes.py,用于设置es的索引模型。注意,索引模型的文件名必须是search_indexes。
- 类名必须为需要检索的model_name+index
- 每个索引里面必须有且只能有一个字段为 document=true,这代表haystack 和搜索引擎将使用此字段的内容作为索引进行检索(primary field)。其他的字段只是附属的属性,方便调用,并不作为检索数据。
- 如果使用一个字段设置了document=true,则一般约定此字段名为text,这是在searchindex类里面一贯的命名,以防止后台混乱,当然名字你也可以随便改,不过不建议改。
- haystack提供了use_template=true在text字段,这样就允许我们使用数据模板去建立搜索引擎索引的文件,说得通俗点就是索引里面需要存放一些什么东西
- text字段用于构造索引,只不过具体构造索引的值写在另一个文件内。
- id、title、digest、content、image_url等字段用于以索引查询到的返回内容。
- get_model方法用于指明建立索引的对应模型。
- index_queryset方法用于返回建立索引的数据查询集。
from haystack import indexes
from .models import course
class courseindex(indexes.searchindex, indexes.indexable):
# 全文索引[可以根据配置,可以包括多个字段索引]
# document=true 表示当前字段为全文索引
# use_template=true 表示接下来haystack需要加载一个固定路径的html模板文件,让text与其他索引字段绑定映射关系
text = indexes.charfield(document=true, use_template=true)
# 普通索引[单字段,只能提供单个字段值的搜索,所以此处的声明更主要是为了提供给上面的text全文索引使用的]
# es索引名 = indexes.索引数据类型(model_attr="orm中的字段名")
id = indexes.integerfield(model_attr="id")
name = indexes.charfield(model_attr="name")
description = indexes.charfield(model_attr="description")
teacher = indexes.charfield(model_attr="teacher__name")
course_cover = indexes.charfield(model_attr="course_cover")
get_level_display=indexes.charfield(model_attr="get_level_display")
students=indexes.integerfield(model_attr="students")
get_status_display=indexes.charfield(model_attr="get_status_display")
lessons=indexes.integerfield(model_attr="lessons")
pub_lessons=indexes.integerfield(model_attr="pub_lessons")
price=indexes.decimalfield(model_attr="price")
discount=indexes.charfield(model_attr="discount_json")
orders=indexes.integerfield(model_attr="orders")
# 指定与当前es索引模型对接的mysql的orm模型
def get_model(self):
return course
# 当用户搜索es索引时,对应的提供的mysql数据集有哪些?
def index_queryset(self, using=none):
return self.get_model().objects.filter(is_deleted=false,is_show=true)orm模型中新增discount_json字段方法
courses.models,代码:
import json
class course(basemodel):
course_type = (
(0, '付费购买'),
(1, '会员专享'),
(2, '学位课程'),
)
level_choices = (
(0, '初级'),
(1, '中级'),
(2, '高级'),
)
status_choices = (
(0, '上线'),
(1, '下线'),
(2, '预上线'),
)
# course_cover = models.imagefield(upload_to="course/cover", max_length=255, verbose_name="封面图片", blank=true, null=true)
course_cover = stdimagefield(variations={
'thumb_1080x608': (1080, 608), # 高清图
'thumb_540x304': (540, 304), # 中等比例,
'thumb_108x61': (108, 61, true), # 小图(第三个参数表示保持图片质量),
}, max_length=255, delete_orphans=true, upload_to="course/cover", null=true, verbose_name="封面图片",blank=true)
course_video = models.filefield(upload_to="course/video", max_length=255, verbose_name="封面视频", blank=true, null=true)
course_type = models.smallintegerfield(choices=course_type,default=0, verbose_name="付费类型")
level = models.smallintegerfield(choices=level_choices, default=1, verbose_name="难度等级")
description = richtextuploadingfield(null=true, blank=true, verbose_name="详情介绍")
pub_date = models.datefield(auto_now_add=true, verbose_name="发布日期")
period = models.integerfield(default=7, verbose_name="建议学习周期(day)")
attachment_path = models.filefield(max_length=1000, blank=true, null=true, verbose_name="课件路径")
attachment_link = models.charfield(max_length=1000, blank=true, null=true, verbose_name="课件链接")
status = models.smallintegerfield(choices=status_choices, default=0, verbose_name="课程状态")
students = models.integerfield(default=0, verbose_name="学习人数")
lessons = models.integerfield(default=0, verbose_name="总课时数量")
pub_lessons = models.integerfield(default=0, verbose_name="已更新课时数量")
price = models.decimalfield(max_digits=10,decimal_places=2, verbose_name="课程原价",default=0)
recomment_home_hot = models.booleanfield(default=false, verbose_name="是否推荐到首页新课栏目")
recomment_home_top = models.booleanfield(default=false, verbose_name="是否推荐到首页必学栏目")
direction = models.foreignkey("coursedirection", related_name="course_list", on_delete=models.do_nothing, null=true, blank=true, db_constraint=false, verbose_name="学习方向")
category = models.foreignkey("coursecategory", related_name="course_list", on_delete=models.do_nothing, null=true, blank=true, db_constraint=false, verbose_name="课程分类")
teacher = models.foreignkey("teacher", related_name="course_list", on_delete=models.do_nothing, null=true, blank=true, db_constraint=false, verbose_name="授课老师")
class meta:
db_table = "fg_course_info"
verbose_name = "课程信息"
verbose_name_plural = verbose_name
def __str__(self):
return "%s" % self.name
def course_cover_small(self):
if self.course_cover:
return mark_safe(f'<img style="border-radius: 0%;" src="{self.course_cover.thumb_108x61.url}">')
return ""
course_cover_small.short_description = "封面图片(108x61)"
course_cover_small.allow_tags = true
course_cover_small.admin_order_field = "course_cover"
def course_cover_medium(self):
if self.course_cover:
return mark_safe(f'<img style="border-radius: 0%;" src="{self.course_cover.thumb_540x304.url}">')
return ""
course_cover_medium.short_description = "封面图片(540x304)"
course_cover_medium.allow_tags = true
course_cover_medium.admin_order_field = "course_cover"
def course_cover_large(self):
if self.course_cover:
return mark_safe(f'<img style="border-radius: 0%;" src="{self.course_cover.thumb_1080x608.url}">')
return ""
course_cover_large.short_description = "封面图片(1080x608)"
course_cover_large.allow_tags = true
course_cover_large.admin_order_field = "course_cover"
@property
def discount(self):
# todo 将来通过计算获取当前课程的折扣优惠相关的信息
import random
return {
"type": ["限时优惠","限时减免"].pop(random.randint(0,1)), # 优惠类型
"expire": random.randint(100000, 1200000), # 优惠倒计时
"price": float(self.price - random.randint(1,10) * 10), # 优惠价格
}
def discount_json(self):
# 必须转成字符串才能保存到es中。所以该方法提供给es使用的。
return json.dumps(self.discount)全文索引字段模板
全文索引模板必须先配置django项目中的templates模板引擎路径,而且全文索引模板的路径必须是模板目录下的search/indexes/子应用目录名/模型类名_text.txt。否则报错。settings.dev,代码:
templates = [
{
'backend': 'django.template.backends.django.djangotemplates',
'dirs': [
base_dir / "templates", # base_dir 是apps的父级目录,是主应用目录,templates需要手动创建
],
'app_dirs': true,
'options': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]创建全文索引字段的html模板,在html模板中采用django的模板语法,绑定text与其他es单字段索引的映射关系。
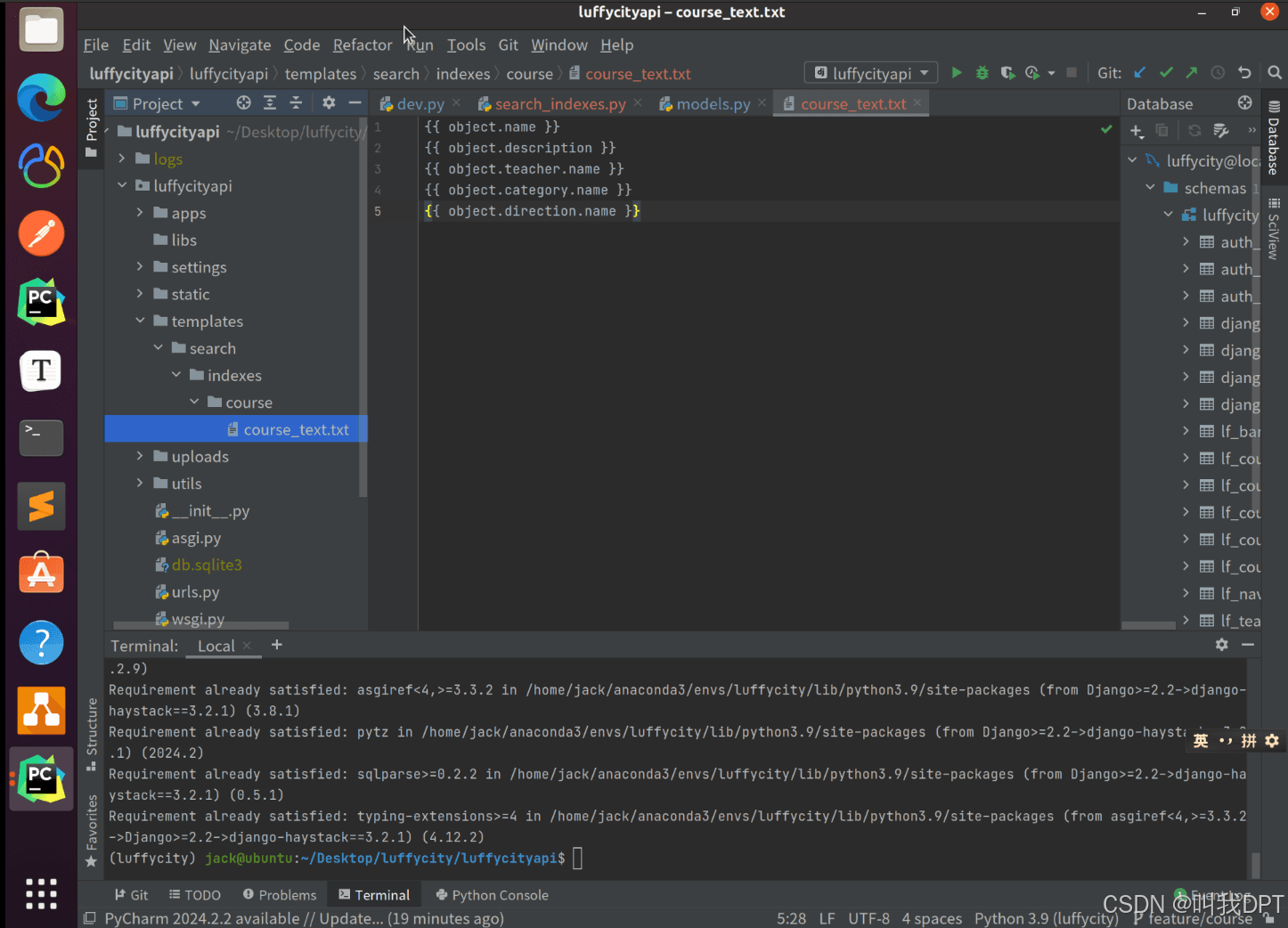
注意:course_text.txt 中course就是orm模型类名小写,text就是es索引模型类中的全文索引字段名。
templates/search/indexes/courses/course_text.txt。代码:
{{ object.name }}
{{ object.description }}
{{ object.teacher.name }}
{{ object.category.name }}
{{ object.diretion.name }}object表示当前orm的模型对应。
索引序列化器
courses.serializers,代码:
from drf_haystack.serializers import haystackserializer
from .search_indexes import courseindex
from django.conf import settings
class courseindexhaystackserializer(haystackserializer):
"""课程搜索的序列化器"""
class meta:
index_classes = [courseindex]
fields = ["text", "id", "name", "course_cover", "get_level_display", "students", "get_status_display", "pub_lessons", "price", "discount", "orders"]
def to_representation(self, instance):
"""用于指定返回数据的字段的"""
# 课程的图片,在这里通过elasticsearch提供的,所以不会提供图片地址左边的域名的。因此在这里手动拼接
instance.course_cover = f'//{settings.oss_bucket_name}.{settings.oss_endpoint}/uploads/{instance.course_cover}'
return super().to_representation(instance)全文搜索的索引视图
from drf_haystack.viewsets import haystackviewset
from drf_haystack.filters import haystackfilter
from .serializers import courseindexhaystackserializer
from .models import course
class coursesearchviewset(haystackviewset):
"""课程信息全文搜索视图类"""
# 指定本次搜索的最终真实数据的保存模型
index_models = [course]
serializer_class = courseindexhaystackserializer
filter_backends = [orderingfilter, haystackfilter]
ordering_fields = ('id', 'students', 'orders')
pagination_class = courselistpagenumberpagination路由
from django.urls import path,re_path
from . import views
from rest_framework import routers
router = routers.defaultrouter()
# 注册全文搜索到视图集中生成url路由信息
router.register("search", views.coursesearchviewset, basename="course-search")
urlpatterns = [
path("directions/", views.coursedirectionlistapiview.as_view()),
re_path("^categories/(?p<direction>\d+)/$", views.coursecategorylistapiview.as_view()),
re_path("^(?p<direction>\d+)/(?p<category>\d+)/$", views.courselistapiview.as_view()),
] + router.urls手动构建es索引
因为此前mysql中已经有了部分的数据,而这部分数据在es中是没有创建索引。所以需要先把之前的数据同步生成全文索引。在终端下执行以下命令
# 重建索引 python manage.py rebuild_index # 更新索引 # python manage.py update_index --age=<num_hours> # 删除索引 # python manage.py clear_index
访问
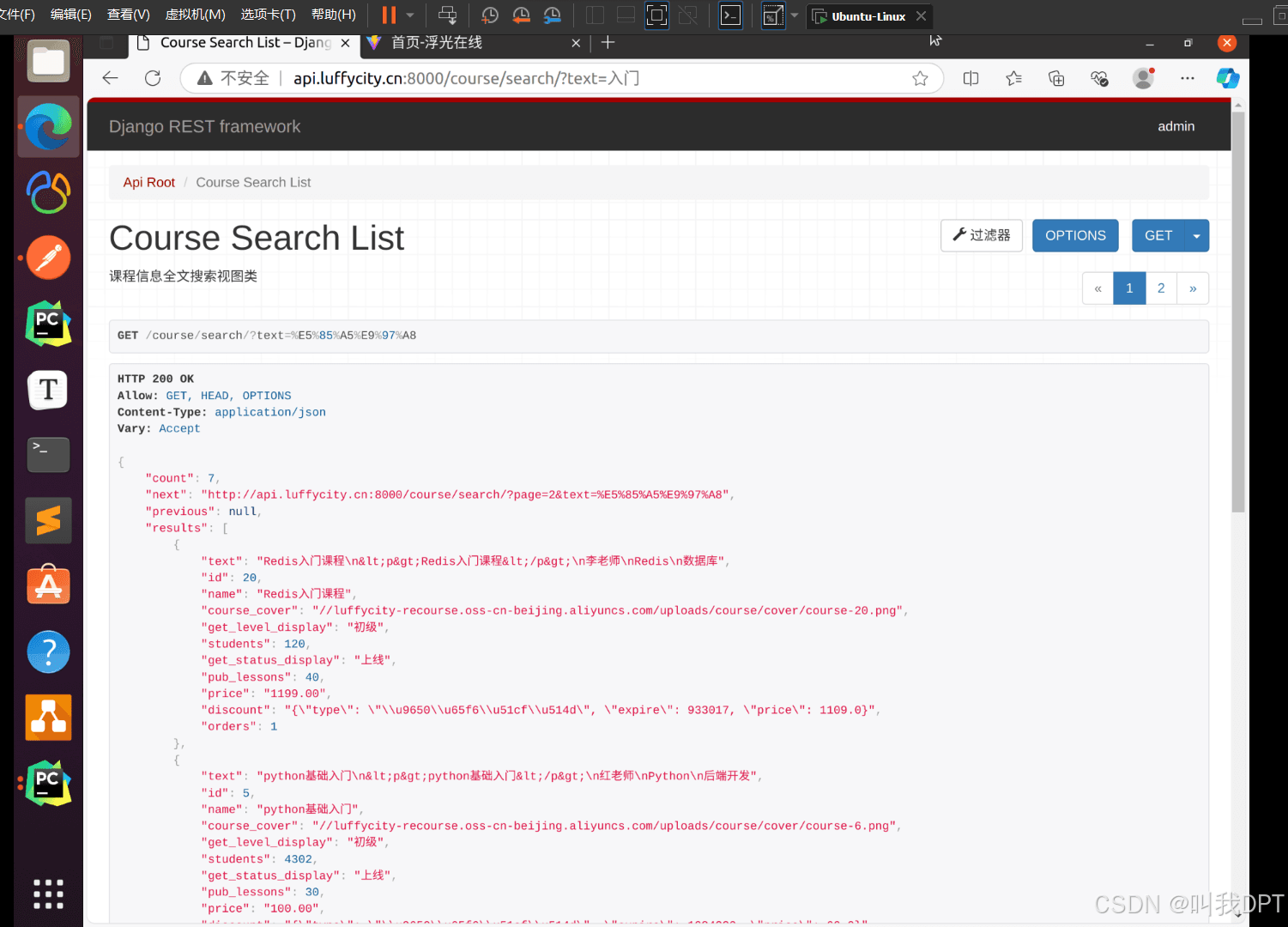
http://api.fuguang.cn:8000/courses/search/?text=入门
http://api.fuguang.cn:8000/courses/search/?text=李老师
到此这篇关于集成elasticsearch到django restful的文章就介绍到这了,更多相关elasticsearch集成django restful内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论