redis的mget命令是一种高效的批量读取操作,可以显著提高读取性能,减少网络往返的次数,本文从mget命令的机制实现、底层原理、应用场景及性能优化等多个维度,深入解析redis中的mget命令的工作方式,并对它与其他批量操作命令的对比进行了详细介绍。
redis 是一种广泛应用于分布式系统中的内存数据库,以其高效的存储和访问方式著称。而在高并发的应用场景中,redis 提供了多种数据获取方式,其中 mget 是用于一次获取多个键值对的命令。与 get 一次获取一个键值不同,mget 可以在一次请求中返回多个键的值,显著提高了读取性能,减少了网络往返的次数。
本文将从 mget 命令的机制实现、底层原理、应用场景及性能优化等多个维度,深入解析 redis 中的 mget 命令的工作方式,帮助读者更好地理解这一重要命令在大规模应用中的优势及注意事项。

1. mget 命令的基本功能与用法
1.1 mget 命令简介
mget 是 redis 的批量读取命令,允许用户一次性获取多个键对应的值。其语法如下:
mget key1 key2 key3 ... keyn
其中,key1 至 keyn 是多个 redis 键,命令将返回这些键的值组成的数组。如果某个键不存在,则相应的返回值为 nil。
1.2 mget 的基本示例
我们可以通过以下代码片段直观了解 mget 的工作方式:
set key1 "value1" set key2 "value2" set key3 "value3" mget key1 key2 key3 # 返回结果: # 1) "value1" # 2) "value2" # 3) "value3"
可以看到,mget 能够同时返回多个键的值。如果某个键不存在,它会返回 nil:
mget key1 key4 # 返回结果: # 1) "value1" # 2) (nil)
通过这种方式,mget 可以显著减少客户端与服务器之间的通信次数,在需要获取大量键值的情况下尤其适用。
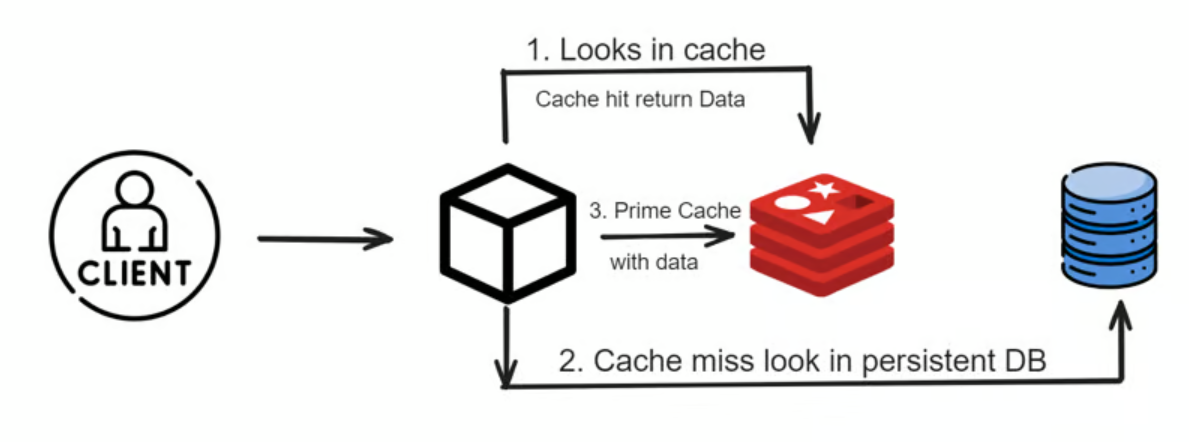
2. mget 实现的底层机制
2.1 单键读取(get)的机制
要理解 mget 的底层实现,首先要了解 get 命令是如何工作的。在 redis 中,get 操作的本质是从 redis 数据库中查找指定键对应的值,这个过程包括以下步骤:
- redis 接收到客户端的 get 请求,解析并识别出请求的键。
- redis 在对应的数据库中查找这个键是否存在。
- 如果键存在,redis 返回键对应的值;如果不存在,返回 nil。
redis 使用哈希表(dict)来存储键值对,这使得查找操作的平均时间复杂度为 o(1)。因此,get 操作本身是非常高效的。
2.2 mget 的批量读取机制
mget 的工作原理与 get 类似,但在实现上做了批量优化。具体来说,mget 并不是一次性读取所有键值后再统一返回,而是逐个遍历请求的键并依次执行 get 操作,然后将所有结果合并返回。redis 内部会按照以下流程处理 mget 请求:
- redis 接收到客户端的 mget 请求,解析出所有的键。
- 对每个键执行与 get 相同的查找操作。
- 将每个查找结果(值或 nil)放入结果数组中。
- 最终将整个结果数组返回给客户端。
虽然 mget 是批量操作,但每个键值的读取操作仍然是独立完成的,因此每个键值的查找时间复杂度仍然是 o(1),总体时间复杂度与键的数量成线性关系,即 o(n),其中 n 是请求中的键的数量。
2.3 mget 执行的优化
尽管 mget 的底层操作是逐个键执行查找,但 redis 通过将这些操作打包成一次请求来减少网络往返的次数,从而显著提高了批量读取的性能。这种优化特别适用于高并发、低延迟的场景,因为网络通信往返的时间往往比数据查找的时间更加消耗性能。
此外,redis 的高效内存管理和使用数据结构的优化(如哈希表和压缩列表)也为 mget 提供了性能保障。

3. mget 的应用场景及优势
3.1 大规模读取场景
在需要一次性读取大量键值对的场景中,mget 能够显著提高性能。常见的场景包括:
- 缓存系统:在缓存系统中,多个关联的数据可能存储在不同的键中,使用 mget 可以一次性获取这些键的所有值,减少通信延迟。
- 推荐系统:推荐算法往往需要从 redis 中获取大量用户行为数据或推荐结果,mget 可以有效提升数据获取的效率。
- 实时数据分析:在一些实时数据分析场景中,数据分析引擎可能需要从 redis 中批量获取大量指标值,mget 能够在此类场景中大大降低延迟。
3.2 减少网络开销
redis 是一个基于客户端-服务器架构的系统,客户端与服务器之间的通信需要经过网络传输。每次通信的过程包括请求的发送和响应的接收,网络延迟在高并发的场景下可能成为瓶颈。通过使用 mget,可以将多个键值的读取操作合并为一次请求,显著减少网络往返的次数,从而提高系统的吞吐量。
3.3 对比 get 的性能
为了更清晰地理解 mget 的性能优势,我们可以通过以下代码来进行简单的性能对比测试。
使用 get:
import time
import redis
r = redis.redis()
start_time = time.time()
# 模拟多次 get 操作
for i in range(1000):
r.get(f"key{i}")
end_time = time.time()
print(f"get 批量操作耗时: {end_time - start_time} 秒")使用 mget:
import time
import redis
r = redis.redis()
start_time = time.time()
# 使用 mget 一次性获取多个键的值
keys = [f"key{i}" for i in range(1000)]
r.mget(keys)
end_time = time.time()
print(f"mget 批量操作耗时: {end_time - start_time} 秒")在高并发场景下,mget 的效率明显优于多次 get,因为它显著减少了网络通信的开销。
4. mget 的性能瓶颈与优化
虽然 mget 提供了高效的批量读取方式,但在某些情况下,性能仍然可能受到限制。以下是一些可能导致 mget 性能瓶颈的因素及相应的优化方法。
4.1 大量不存在的键
在 mget 请求中,如果存在大量的键在 redis 中并不存在,redis 需要为每个不存在的键返回 nil,这在大量键的场景下可能会增加不必要的处理开销。为了减少这种开销,开发者可以在请求之前通过其他机制(如数据库或缓存的元数据)筛选出存在的键,从而减少 mget 的无效操作。
4.2 键的分布问题
在 redis 集群模式下,mget 涉及到多个键的读取操作,而这些键可能存储在不同的分片中。如果请求中的键被分布在多个分片上,redis 集群需要协调多个分片之间的数据传输,这可能增加延迟。为了解决这一问题,可以通过合理设计键的命名规则(如使用相同的哈希槽)将相关的键分配到同一分片上,从而减少跨分片的通信开销。
4.3 内存管理的影响
在高负载场景下,redis 的内存管理机制可能成为性能瓶颈。例如,当 redis 处于高内存使用率时,频繁的内存分配和释放操作可能影响系统的响应时间。为了缓解这一问题,开发者可以使用内存优化策略(如适当的内存淘汰机制和合理的内存分配配置),从而提高 mget 的整体性能。
config set maxmemory-policy allkeys-lru
通过设置 redis 的内存淘汰策略,可以确保在高负载时仍能高效处理 mget 请求。
5. mget 与其他批量操作的比较
在 redis 中,除了 mget 外,其他批量操作命令(如 mset 和 hmget)也提供了对多个键值的操作。了解这些命令的区别,可以帮助开发者在不同的应用场景中选择合适的批量操作方式。
5.1 mget 与 mset
mget 用于批量获取键值,而 mset 则是用于批量设置键值。两者的功能可以看作是对称的操作:
- mget:从 redis 中读取多个键的值,语法为 mget key1 key2 key3 ... keyn。
- mset:将多个键值对同时写入 redis,语法为 mset key1 value1 key2 value2 ... keyn valuen。
两者的底层实现类似,都依赖 redis 高效的键值查找和写入机制。mget 可以减少多次 get 的网络开销,而 mset 则可以减少多次 set 的网络开销,适用于批量读取和写入操作。
5.2 mget 与 hmget
hmget 是 redis 中哈希类型(hash)数据结构的批量读取命令,与 mget 类似,但作用于哈希表中的字段。其语法为:
hmget hashkey field1 field2 field3 ... fieldn
hmget 返回的是哈希表中指定字段的值,适用于复杂数据结构的批量读取操作。与 mget 的区别在于,mget 作用于多个 redis 键,而 hmget 作用于单个 redis 键中的多个字段。对于某些需要存储关联数据的场景,哈希表提供了更高效的方式。
5.3 mget 与 pipelining
redis 支持 pipelining,这是一种在客户端发送多个请求,而无需等待每个请求的响应的机制。mget 是通过批量获取键值来减少网络往返,而 pipelining 则是通过并行发送多个 get 请求来优化性能。
举个例子,使用 pipelining 可以达到类似 mget 的效果:
import redis
r = redis.redis()
pipeline = r.pipeline()
for i in range(1000):
pipeline.get(f"key{i}")
results = pipeline.execute()pipelining 的优点在于可以并行处理大量请求,但每个请求仍然是独立的,因此在某些场景中,mget 可能会提供更好的性能,尤其是在需要获取大量键的场景下。pipelining 适用于需要更多控制的操作场景,例如需要执行多种 redis 命令组合。
6. mget 命令的性能优化与注意事项
尽管 mget 在批量读取场景中具有显著的性能优势,但为了在高并发和大规模使用中发挥最佳性能,开发者仍需关注以下几个关键点,并采取相应的优化措施。
6.1 合理设置 redis 实例配置
redis 的性能很大程度上依赖于配置的优化,特别是在高并发、大数据量的场景中。以下是一些常见的优化设置:
- 最大内存配置:通过设置 maxmemory 选项,限制 redis 使用的内存总量,以防止由于内存不足导致的性能下降或 oom(out of memory)错误。
config set maxmemory 2gb
- 内存淘汰策略:当 redis 达到最大内存限制时,可以配置适当的内存淘汰策略。例如使用 allkeys-lru 策略,基于最近最少使用算法淘汰键,以确保在内存紧张时仍能高效处理读写请求。
config set maxmemory-policy allkeys-lru
- 持久化与快照:在高并发场景中,频繁的持久化操作可能会影响 redis 的性能。开发者可以通过调整持久化策略(如 rdb 或 aof),减少性能开销。
6.2 数据分片与集群模式
对于大规模应用,redis 的单实例可能无法满足所有的数据存储和访问需求。这时,使用 redis 集群可以将数据分片存储在不同的实例中,从而实现负载均衡和扩展。
然而,在集群模式下,mget 的性能会受到键分布的影响。如果批量读取的键分布在多个分片中,redis 需要协调多个实例来获取数据,这可能导致较高的延迟。因此,为了优化 mget 在集群中的性能,开发者可以通过以下方式进行优化:
- 哈希槽优化:将相关联的键分配到相同的哈希槽中,以确保它们存储在同一分片上,从而减少跨分片的数据传输开销。
- 合理设计键的分布:使用合理的键命名规则和分片策略,将热数据均匀分布到不同的实例中,避免单个实例的过载。
6.3 使用缓存与批处理策略
在需要频繁使用 mget 命令的场景下,可以通过增加缓存层或使用批处理策略来进一步提升性能:
- 缓存层:在应用程序中引入本地缓存(如使用 guava 或 caffeine),将经常访问的键值对缓存起来,减少对 redis 的直接请求。
- 批处理请求:在业务层通过批处理技术,尽量将多个小批量的 mget 请求合并为一个大批量请求,减少网络开销。
7. redis mget 命令的实际案例分析
为了更好地理解 mget 的使用场景和性能优化,下面通过一个实际案例来分析 mget 在高并发场景中的应用。
7.1 案例背景
某电商平台使用 redis 存储商品的库存数据。每次用户浏览商品详情页时,系统需要从 redis 中读取该商品的库存、价格、促销信息等多个数据。由于用户量大、请求频繁,系统需要尽量减少对 redis 的读取请求,以降低延迟和提升并发处理能力。
7.2 mget 的应用
在此场景中,开发者可以通过 mget 命令一次性读取与商品相关的所有数据,避免多次单独的 get 请求。以下是一个简单的代码示例:
import redis
r = redis.redis()
# 获取商品的库存、价格和促销信息
keys = ['product:stock:1001', 'product:price:1001', 'product:promotion:1001']
results = r.mget(keys)
print(f"库存: {results[0]}")
print(f"价格: {results[1]}")
print(f"促销信息: {results[2]}")7.3 性能优化
通过使用 mget,平台可以显著减少 redis 的请求次数,从而降低网络延迟,提升页面的加载速度。在此基础上,开发者还可以进一步优化系统性能:
- 使用缓存:对于高频访问的商品信息,可以将其缓存在应用服务器的本地内存中,避免每次都访问 redis。
- 集群分片:如果商品数量庞大,平台可以使用 redis 集群,将商品信息按类别或区域分片存储,以实现负载均衡。
8. 结论
redis mget 命令通过批量读取多个键的值,提供了高效的数据访问方式,尤其适用于需要减少网络往返的高并发场景。本文详细介绍了 mget 的实现机制、应用场景、性能优化方法以及与其他批量操作命令的对比。
开发者在实际应用中,可以结合具体的业务需求和系统架构,灵活使用 mget 命令,并通过合理的系统配置、缓存策略和集群架构设计,最大限度地提升 redis 的性能。
到此这篇关于redis mget命令深度解析的文章就介绍到这了,更多相关redis mget实现机制解析内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论