docker部署sql server 2017 always on集群
1.docker部署always on集群
sql server在2016年开始支持linux。随着2017和2019版本的发布,它开始支持linux和容器平台上的ha/dr、kubernetes和大数据集群解决方案。
在本文中,我们将在3个机器的docker容器上安装sql server 2017,并创建alwayson可用性组。
2.前提工作
注意: 所有机器操作
2.1安装docker
安装docker就不介绍了,自行安装即可.
2.2配置时间同步
crontab -e #增加 * * * * * /usr/sbin/ntpdate time.windows.com && /usr/sbin/hwclock -w >/dev/null 2>&1
3.架构
| 主机名 | ip | 端口 | 角色 |
|---|---|---|---|
| sql01 | 192.168.1.30 | 1433:14335022:5022 | 主 |
| sql02 | 192.168.1.31 | 1433:14335022:5022 | 副本 |
| sql03 | 192.168.1.32 | 1433:14335022:5022 | 副本 |
端口表示:外网端口:内网端口
4.准备相关容器镜像
注意: 所有机器操作
拉取数据库的docker镜像,如下
4.1sql server 2017
docker pull mcr.microsoft.com/mssql/server:2017-latest
可通过docker images来查看已下载的镜像信息。
镜像地址:https://hub.docker.com/_/microsoft-mssql-server
5.开始配置-容器
环境准备完毕后,开始正式的配置安装。
5.1创建dockerfile
注意: 所有机器操作
创建目录用于存放dockerfile、docker-compose.yml等文件。
vi dockerfile
- dockerfile内容如下
from mcr.microsoft.com/mssql/server:2017-latest run /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1 run /opt/mssql/bin/mssql-conf set sqlagent.enabled true
说明:
- from:表示基于什么镜像进行安装的
- run:在镜像中进行的操作
5.2编译镜像
注意: 所有机器操作
通过dockerfile来编译镜像,用于后面的安装,命令:
docker build -t mcr.microsoft.com/mssql/server:2017-ty .
其中mcr.microsoft.com/mssql/server为镜像名称,2017-ty是镜像标签,.表示在当前目录下编译,因为dockerfile就在当前目录下。
最后出现successfully表示编译成功,否则根据错误信息进行解决。
5.3创建master容器
在sql01执行:
docker run --name sql01 \ --hostname sql01 \ -p 1433:1433 \ -p 5022:5022 \ -e 'accept_eula=y' \ -e 'sa_password=p@ssw0rd02' \ -e "mssql_agent_enabled=true" \ -e "mssql_pid=developer" \ -d mcr.microsoft.com/mssql/server:2017-ty
5.4创建slave容器
在sql02执行:
docker run --name sql02 \ --hostname sql02 \ -p 1433:1433 \ -p 5022:5022 \ -e 'accept_eula=y' \ -e 'sa_password=p@ssw0rd02' \ -e "mssql_agent_enabled=true" \ -e "mssql_pid=developer" \ -d mcr.microsoft.com/mssql/server:2017-ty
在sql03执行:
docker run --name sql03 \ --hostname sql03 \ -p 1433:1433 \ -p 5022:5022 \ -e 'accept_eula=y' \ -e 'sa_password=p@ssw0rd02' \ -e "mssql_agent_enabled=true" \ -e "mssql_pid=developer" \ -d mcr.microsoft.com/mssql/server:2017-ty
至此容器已经启动完成,下面通过ssms连接数据库进行相关检查和配置alwayson。
5.5ssms连接mssql
通过宿主机的外网ip+端口连接相应的数据库,如下:
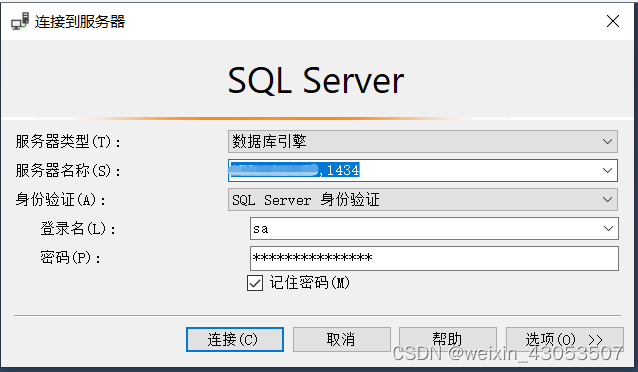
注意:ip和端口之间是逗号
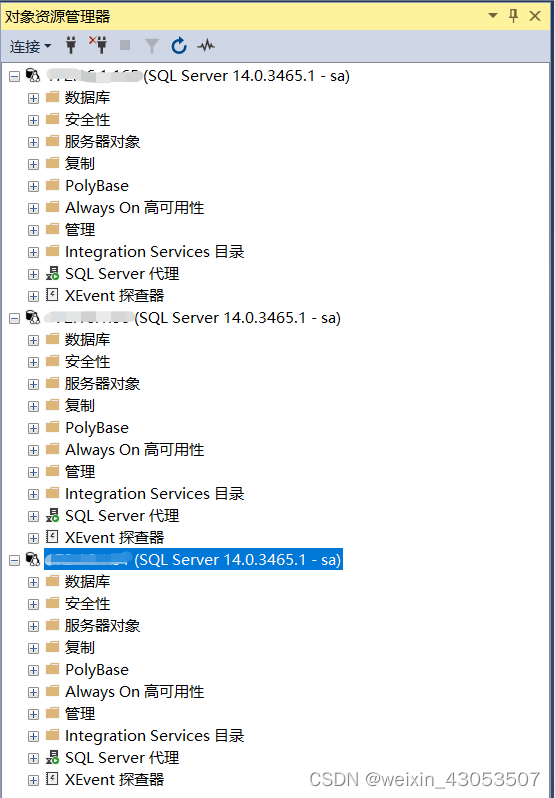
可以看到数据库的图标也是linux的图标。
6.配置-数据库
这部分就是在数据库中进行相关配置,如:创建key加密文件,管理用户、可用组等。
6.1连接主库-sql01
主库也就是节点1,端口是1433,连接方法如上图。
我们将证书和私钥提取到/tmp/dbm_certificate.cer和/tmp/dbm_certificate.pvk文件中。
我们将这些文件复制到其他节点,并根据以下文件创建主密钥和证书:执行以下脚本
use master
go
create login dbm_login with password = 'test@13579';
create user dbm_user for login dbm_login;
go
create master key encryption by password = 'test@13579';
go
create certificate dbm_certificate with subject = 'dbm';
backup certificate dbm_certificate
to file = '/tmp/dbm_certificate.cer'
with private key (
file = '/tmp/dbm_certificate.pvk',
encryption by password = 'test@13579'
);
go将文件拷贝到其他两个节点:
#sql01操作 docker cp sql01:/tmp/dbm_certificate.cer ./ docker cp sql01:/tmp/dbm_certificate.pvk ./ scp dbm_certificate.* 192.168.1.31:/data/ty/ scp dbm_certificate.* 192.168.1.32:/data/ty/ #sql02操作 docker cp dbm_certificate.cer sql02:/tmp/ docker cp dbm_certificate.pvk sql02:/tmp/ #sql03操作 docker cp dbm_certificate.cer sql03:/tmp/ docker cp dbm_certificate.pvk sql03:/tmp/
6.2连接从库-sql02和sql03
两个从库的端口分别是:1502和1503.然后重复主库执行的操作,如下:
create login dbm_login with password = 'test@13579';
create user dbm_user for login dbm_login;
go
create master key encryption by password = 'test@13579';
go
create certificate dbm_certificate
authorization dbm_user
from file = '/tmp/dbm_certificate.cer'
with private key (
file = '/tmp/dbm_certificate.pvk',
decryption by password = 'test@13579'
);
go6.3所有节点
在所有节点上执行以下命令
create endpoint [hadr_endpoint]
as tcp (listener_ip = (0.0.0.0), listener_port = 5022)
for data_mirroring (
role = all,
authentication = certificate dbm_certificate,
encryption = required algorithm aes
);
alter endpoint [hadr_endpoint] state = started;
grant connect on endpoint::[hadr_endpoint] to [dbm_login];
go启用开机自启动alwayon,在所有节点执行以下命令
alter event session alwayson_health on server with (startup_state=on); go
6.4创建高可用组
可以用ssms工具和t-sql两种方式,下面以t-sql为例:
运行以下脚本在主节点中创建一个可用性组。 请注意,选择cluster_type = none选项是因为它是在没有诸如pacemaker或windows server故障转移群集之类的群集管理平台的情况下安装的。
如果要在linux上安装alwayson ag,则应为pacemaker选择cluster_type = external:
create availability group [ag1]
with (cluster_type = none)
for replica on
n'sql01'
with (
endpoint_url = n'tcp://192.168.1.30:5022',
availability_mode = asynchronous_commit,
seeding_mode = automatic,
failover_mode = manual,
secondary_role (allow_connections = all)
),
n'sql02'
with (
endpoint_url = n'tcp://192.168.1.31:5022',
availability_mode = asynchronous_commit,
seeding_mode = automatic,
failover_mode = manual,
secondary_role (allow_connections = all)
),
n'sql03'
with (
endpoint_url = n'tcp://192.168.1.32:5022',
availability_mode = asynchronous_commit,
seeding_mode = automatic,
failover_mode = manual,
secondary_role (allow_connections = all)
);
go在从库中执行以下命令,将从库加入到ag组中
alter availability group [ag1] join with (cluster_type = none); alter availability group [ag1] grant create any database; go
至此在docker容器中安装sql server alwayson集群已经完成了!
注意:当指定cluster_type = none创建可用组时,在执行故障转移时需执行以下命令
-- 将主角色转移到可用性组中的某个备份副本 alter availability group [ag1] force_failover_allow_data_loss; -- 尝试进行优雅的故障转移,如果不能完成,则允许丢失数据 -- alter availability group [ag1] failover;
6.5测试
在主库上创建一个数据库,并加入到可用组ag中。
--创建数据库
create database agtestdb;
go
alter database agtestdb set recovery full;
go
backup database agtestdb to disk = '/var/opt/mssql/data/agtestdb.bak';
go
alter availability group [ag1] add database [agtestdb];
go
-- 创建表
use agtestdb
create table exampletable (
id int primary key,
name nvarchar(50),
description nvarchar(100)
);
-- 插入数据
declare @counter int = 1;
while @counter <= 100
begin
insert into exampletable (id, name, description)
values (@counter, 'name ' + cast(@counter as nvarchar(10)), 'description for ' + cast(@counter as nvarchar(10)));
set @counter = @counter + 1;
end;
go通过ssms查看同步状态是否正常.
6.6监控 ag 状态
通过以下这些视图可以监控 ag 中各个部分的状态。
group的监控
select * from sys.availability_groups; select * from sys.availability_groups_cluster; select * from sys.dm_hadr_availability_group_states;
replica 的监控
select * from sys.availability_replicas; select * from sys.dm_hadr_availability_replica_states; select * from sys.dm_hadr_availability_replica_cluster_nodes; select * from sys.dm_hadr_availability_replica_cluster_states;
在 ag 中的 database 的监控
select * from sys.availability_databases_cluster; select * from sys.dm_hadr_database_replica_states; select * from sys.dm_hadr_database_replica_cluster_states; select name,database_id,replica_id,group_database_id from sys.databases;
6.7故障转移读取缩放ag上的主要副本
每个可用性组仅有一个主要副本。 主要副本允许读取和写入操作。 若要更改哪个副本为主要副本,可进行故障转移。 在典型的可用性组中,群集管理器自动执行故障转移过程。 在群集类型为 none 的可用性组中,需手动执行故障转移过程。
在群集类型为 none 的可用性组中,有两种对主要副本进行故障转移的方法:
- 手动故障转移(无数据丢失)
- 强制手动故障转移(会丢失数据)
手动故障转移(无数据丢失)
主要副本可用时使用此方法,但你需要暂时或永久更改托管主要副本的实例。 若要避免潜在的数据丢失,发出手动故障转移前,确保目标次要副本为最新版本。
手动故障转移(无数据丢失):
- 1.将当前的主要副本和目标次要副本设置为 synchronous_commit。
alter availability group [agrscale] modify replica on n'<node2>' with (availability_mode = synchronous_commit);
- 2.若要确定已将活动事务提交到主要副本和至少一个同步次要副本,请运行以下查询:
select ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number from sys.dm_hadr_database_replica_states drs, sys.availability_groups ag where drs.group_id = ag.group_id;
当 synchronization_state_desc 为 synchronized 时,会同步次要副本。
- 3.将 required_synchronized_secondaries_to_commit 更新为 1。以下脚本在名为 ag1 的可用性组上将required_synchronized_secondaries_to_commit 设置为 1。 运行以下脚本前,将ag1 替换为可用性组的名称:
alter availability group [agrscale] set (required_synchronized_secondaries_to_commit = 1);
此设置可确保将每个活动事务提交到主要副本和至少一个同步次要副本。
备注
此设置并非特定于故障转移,应根据环境要求进行设置。
- 4.将主要副本和不参与故障转移的次要副本设置为脱机,以便为角色更改做好准备:
alter availability group [agrscale] offline
- 5.将目标次要副本升级为主要副本。
alter availability group agrscale force_failover_allow_data_loss;
- 6.将旧的主要和其他次要副本的角色更新为 secondary,在托管旧的主要副本的 sql server 实例上运行以下命令:
alter availability group [agrscale] set (role = secondary);
备注
若要删除可用性组,请使用删除可用性组。 对于使用群集类型为 none 或external 创建的可用性组,请对可用性组的所有副本执行该命令。
- 7.恢复数据移动,为托管主要副本的 sql server(主要和次要副本) 实例上的可用性组中的每个数据库运行以下命令:
alter database [db1] set hadr resume
- 8.重新创建出于读取缩放目的创建且不受群集管理器管理的所有侦听器。 如果原始侦听器指向旧的主要副本,请将其删除,然后将其重新创建为指向新的主要副本。
强制手动故障转移(会丢失数据)
如果主要副本不可用且无法立即恢复,则需要强制执行向次要副本的故障转移(存在数据丢失)。 但是,如果原始主要副本在故障转移后恢复,它将承担主要角色。 若要避免每个副本处于不同的状态,在存在数据丢失的情况下进行强制故障转移后,从可用性组中删除原始主要副本。 原始主要副本重新联机后,从该副本完全删除该可用性组。
若要强制执行从主要副本 n1 到次要副本 n2 的手动故障转移(存在数据丢失),请执行以下步骤:
- 1.在次要副本 (n2) 上,启动强制故障转移:
alter availability group [agrscale] force_failover_allow_data_loss;
- 2.在新的主要副本 (n2) 上,删除原始主要副本 (n1):
alter availability group [agrscale] remove replica on n'n1';
- 3.验证所有的应用程序流量均指向侦听器和/或新的主要副本。
- 4.如果原始主要副本 (n1) 进入联机状态,则立即在原始主要副本 (n1) 上使可用性组agrscale 脱机:
alter availability group [agrscale] offline
- 5.如果存在数据或未同步的更改,则通过备份或其他可满足业务需求的数据复制选项来保存这些数据。
- 6.接下来,从原始主要副本 (n1) 中删除可用性组:
drop availability group [agrscale];
- 7.删除原始主要副本 (n1) 上的可用性组数据库:
use [master] go drop database [agdbrscale] go
- 8.(可选)如果需要,现可将 n1 作为新的次要副本添加回可用性组 agrscale 中。
在主库中执行以下命令,将从库加入到ag组中
use master
alter availability group ag1 add replica on 'sql01'
with (
endpoint_url = 'tcp://192.168.30:5022',
availability_mode = asynchronous_commit,
seeding_mode = automatic,
failover_mode = manual,
secondary_role (allow_connections = all)
);
go在从库中执行以下命令,将从库加入到ag组中
alter availability group [ag1] join with (cluster_type = none); alter availability group [ag1] grant create any database; go
7.参考连接
- https://docs.microsoft.com/en-us/sql/linux/quickstart-install-connect-docker?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/linux/quickstart-install-connect-ubuntu?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-create-availability-group?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-configure-mssql-conf?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-configure-environment-variables?view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/linux/sql-server-linux-availability-group-cluster-ubuntu?view=sql-server-linux-ver15
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。


发表评论