@scheduled定时器使用注意事项
首先定时器可以固定执行时间使用cron表达式,也可以控制方法执行的间隔时间fixeddelay,这里使用的是cron,创建了schedule包,将定时任务放在了schedule包下,下面开始进入正题。
一般在程序中直接使用定时器,但是最好设置一下jvm的默认时区,因为jvm默认时区可能和本机时区不一样,不同操作系统默认时区可能不一样。
使用静态变量static声明的静态变量具有全局作用域,对全局造成影响,保证系统整个时区一致
如果只想针对某部分设置时区需要显示指定时区,不影响全局结果
package com.test.hello.task;
import com.test.hello.service.testentityservice;
import com.test.hello.service.testoneentityservice;
import com.test.hello.service.testtwoentityservice;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.scheduling.annotation.scheduled;
import org.springframework.stereotype.component;
import java.time.localdatetime;
import java.time.zoneid;
import java.time.format.datetimeformatter;
import java.util.timezone;
@slf4j
@component
public class testtask {
//全局修改时区,设置jvm的默认时区,影响整个 java 虚拟机中所有涉及日期和时间的操作所使用的时区。
//在java中,通过 timezone.setdefault() 方法可以实现对 jvm 默认时区的修改。
static {
timezone.setdefault(timezone.gettimezone("gmt+8"));
}
//显示指定时区,不影响全局
// 显式指定使用的时区为 gmt+8
zoneid zoneid = zoneid.of("gmt+8");
// 获取当前时间
localdatetime currenttime = localdatetime.now(zoneid);
// 格式化日期时间
datetimeformatter formatter = datetimeformatter.ofpattern("yyyy-mm-dd hh:mm:ss");
string formattedtime = currenttime.format(formatter);
@autowired
private testentityservice testentityservice;
@autowired
private testoneentityservice testoneentityservice;
@autowired
private testtwoentityservice testtwoentityservice;
/**
* 每天的00:00:00执行任务
*/
@scheduled(cron = "0 0 0 * * *")
public void scheduled() {
log.info("=====>>>>>使用cron {}", testentityservice.countsum());
}
@scheduled(cron = "0 0/1 * * * ?")
public void scheduledstatisticsonaboardnum() {
log.info("=====>>>>>统计: 使用cron {}", testentityservice.countsum());
log.info("=====>>>>>)统计: 使用cron {}", testoneentityservice.countsum());
log.info("=====>>>>>合计统计: 使用cron {}", testtwoentityservice.countsum());
}
}为了美观性,每个定时都单独放在一个类,类目以功能+schedule结尾,该类加上@component表示交给spring管理,定时器的表达式可以在nacos中声明,防止后期需要改定时任务的时候频繁修改代码,只需要修改nacos配置文件即可(nacos配置文件中声明定时器名字的时候不得以特殊字符开头,不然会报错踩坑)
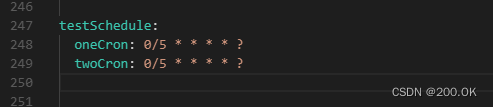
package com.test.stats.schedule;
import lombok.extern.slf4j.slf4j;
import org.apache.commons.lang.stringutils;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.value;
import org.springframework.scheduling.annotation.async;
import org.springframework.scheduling.annotation.scheduled;
import org.springframework.stereotype.component;
@component
@slf4j
public class testschedule {
//定时器表达式配置在nacos中
@scheduled(cron = "${testschedule.onecron}")
//单独配置线程池
@async("poolthread")
public void testscheduled() {
//定时器执行的逻辑代码
}
}以上代码使用到了 @async异步注解,这里我使用了一个线程池,可以根据自己的业务需求自行决定。
定义线程池的意义在与所有执行定时器都是副线程执行,不影响主线程。
使用线程池的情况
- 异步执行任务: 任务在后台异步执行,不阻塞当前线程或应用程序的其他部分时,使用线程池。例如,处理异步消息、发送电子邮件、执行后台计算等。
- 提高并发性: 程序需要同时处理多个并发任务时,线程池可以有效地管理和分配系统资源,提高系统的并发性和性能。这对于处理大量独立的任务或请求非常有用。
- 避免线程创建和销毁的开销: 线程的创建和销毁通常会带来较大的开销。通过使用线程池,可以避免频繁地创建和销毁线程,而是重用现有线程,减少资源开销。
- 限制资源使用: 使用线程池可以限制同时执行的任务数量,以控制系统资源的使用。这对于避免系统过度负载或资源耗尽非常重要。
- 任务队列管理: 线程池通常具有任务队列,可以将需要执行的任务添加到队列中。这使得任务按照预定的顺序执行,而无需手动管理线程的执行。
总结:
如果定时器执行的比较频繁,不想每次都new线程,而且内次都从线程池里取线程,用完线程池自己根据gc回收机制销毁,可以考虑编写线程池
线程池代码
package com.test.hello.config;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import org.springframework.scheduling.concurrent.threadpooltaskexecutor;
import java.util.concurrent.threadpoolexecutor;
@configuration
public class threadpooltaskconfig {
//这里的命名可以在报错的时候清楚是哪个线程报错了
@bean("poolthread")
public threadpooltaskexecutor threadpoolworktaskexecutor() {
threadpooltaskexecutor executor = new threadpooltaskexecutor();
//线程池创建的核心线程数,线程池维护线程的最少数量,即使没有任务需要执行,也会一直存活
executor.setcorepoolsize(8);
//如果设置allowcorethreadtimeout=true(默认false)时,核心线程会超时关闭
//executor.setallowcorethreadtimeout(true);
//阻塞队列 当核心线程数达到最大时,新任务会放在队列中排队等待执行
executor.setqueuecapacity(124);
//最大线程池数量,当线程数>=corepoolsize,且任务队列已满时。线程池会创建新线程来处理任
//任务队列已满时, 且当线程数=maxpoolsize,,线程池会拒绝处理任务而抛出异常
executor.setmaxpoolsize(64);
//当线程空闲时间达到keepalivetime时,线程会退出,直到线程数量=corepoolsize
//允许线程空闲时间30秒,当maxpoolsize的线程在空闲时间到达的时候销毁
//如果allowcorethreadtimeout=true,则会直到线程数量=0
executor.setkeepaliveseconds(30);
//spring 提供的 threadpooltaskexecutor 线程池,是有setthreadnameprefix() 方法的。
//jdk 提供的threadpoolexecutor 线程池是没有 setthreadnameprefix() 方法的
executor.setthreadnameprefix("poolthread");
// rejection-policy:拒绝策略:当线程数已经达到maxsize的时候,如何处理新任务
// callerrunspolicy():交由调用方线程运行,比如 main 线程;如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行
// abortpolicy():该策略是线程池的默认策略,如果线程池队列满了丢掉这个任务并且抛出rejectedexecutionexception异常。
// discardpolicy():如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常
// discardoldestpolicy():丢弃队列中最老的任务,队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列
executor.setrejectedexecutionhandler(new threadpoolexecutor.discardpolicy());
executor.initialize();
return executor;
}
}总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持代码网。




发表评论