前段时间,我们刚刚为大家带来了amd 锐龙7 9700x的首发评测。

除了“游戏专用u”,zen5也有更高端版本
平心而论,9700x很可能是amd近年来最有诚意的新品之一。这不仅仅是因为它有着比过去更低的首发上市价格,同时也因为其作为amd新架构(zen5)首批投向市场的产品之一,选择了“原生8核”这个更利于pc游戏玩家的设计。

再加上大幅改善的功耗和发热,以及明显增强的内存兼容性和a vx512性能,都使锐龙7 9700x的使用成本进一步下降,同时也照顾到了诸如超频、主机模拟器等更多样化pc玩家的“折腾”需求。

当然,大家都知道,amd这一代的桌面版zen5新品并不只有专供游戏的单ccd八核心款式,作为“传统艺能”,采用2ccd+1iod设计的十二核与十六核版本也会接踵而来。今天我们测试的对象,便是其中的十二核款式锐龙9 9900x。
产品解析:更大缓存、更低功耗,最重要是价格降了
众所周知,amd早在3000系锐龙里就已经开始提供12核版本,因此我们列出了从锐龙9 3900x到这一代锐龙9 9900x为止,四代12核产品的对比表。
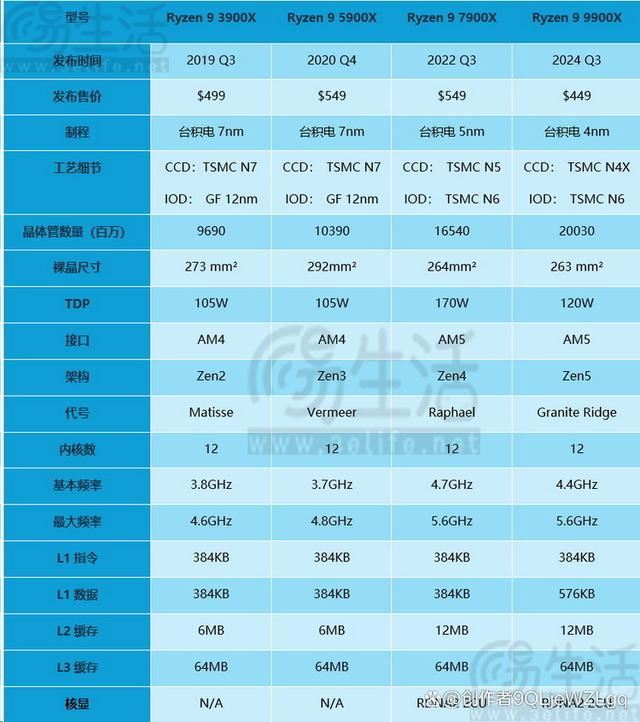
可以看到,与过去的几代产品相比,锐龙9 9900x最明显改变,一是它的价格进一步下探,其二是它的默认tdp和基准频率比上代都有着显著的下降,最后一点就是我们在9700x评测中已经提及,容量增大了50%、带宽翻倍的l1数据缓存。
其中,降低基准频率和默认tdp显然是最为值得关注的点。因为众所周知,如今cpu的睿频机制与过去已经大不相同,很多时候cpu会根据当前的散热、负载、供电状况,甚至是任务指令集的类型,综合调整当前的频率状态,以往那种“开个高性能模式、cpu就自动锁定最高主频”的时代也早已一去不复返。

正是在这种背景下,现在越来越多的cpu、特别是高端的多核cpu开始采用“低基准、高峰值”的频率设计。在实际使用中,cpu会在一个很大的范围内、不断地自动调整运行频率,从而达到一个更低的平均功耗水平。很显然,这一次的锐龙9 9900x、包括定位更高的9950x,都是这一设计思路下的产物。

当然,可能有的朋友还是会觉得,“我掏了钱,就应该全程cpu频率拉满才划算”。对于amd这一代的cpu来说,拉满频率本身其实很简单,基本上只需要在主板bios里开启pbo、把功耗上限解锁,只要散热器足够给力(amd为9900x建议的是使用240mm或更高规格水冷),就能看到cpu几乎全程跑到5.65ghz、甚至更高水准了。
更多解析:双ccd设计更偏生产力,打游戏需上“科技”
除了理论规格上的小“秘密”,锐龙9 9900x在实际使用中也存在一些窍门。
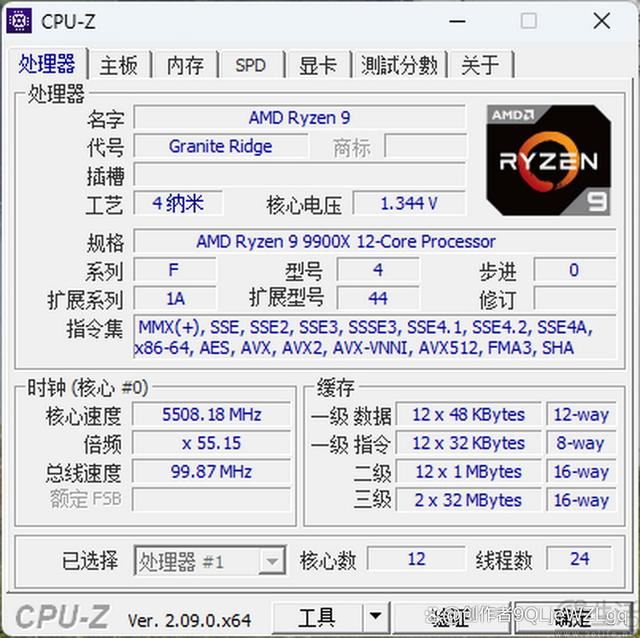
我们首先先用cpu-z来“验明正身”。可以看到,锐龙9 9900x的一级缓存和二级缓存明显是“绑定”每一个核心的。但是它的三级缓存则与过去一样,实际上是分成了两个区域,由两个ccd分别“享有”32mb。
很显然,这就会带来两个ccd之间的核心通讯延迟问题。特别是在对延迟敏感的游戏场景,如果有游戏被调度到了“仅有”4核心的ccd里,而它本身的优化又可以用到超过4核心的cpu资源,那么就可能发生单一程序跨ccd的cpu核心和l3缓存访问。此时突然增大的延迟,就可能会带来游戏帧率的波动,特别是对于1% low帧的影响会比较明显。
好在,游戏优化和性能监测软件《游戏加加》最近刚刚上线了新的进程核心分配工具。活用这一“黑科技”,玩家就可以指定游戏进程运行在“8大核”的那个ccd,或者是未来x3d版本具备更大缓存的ccd上,从而更好地优化游戏的瞬时流畅度。
基准测试:缓存和预测性能极高,架构设计很有特点
接下来,我们正式进入对锐龙9 9900x的测试环节。
此次测试使用的主板依旧是升级了最新bios的华硕rog strix x670e吹雪,内存则是两条共32gb的ddr5-7600mhz。
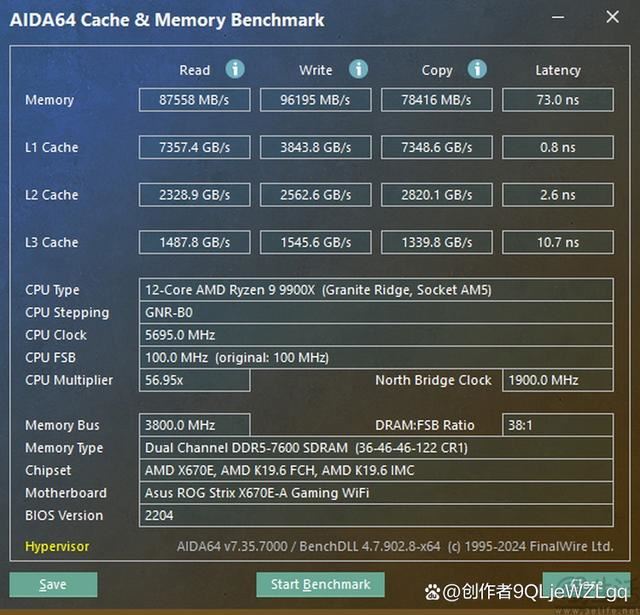
我们首先测试了锐龙9 9900x的内存和缓存性能。可以看到,与此前的锐龙7 9700x一样,9900x也将l1缓存的读写和复制带宽进行了翻倍。
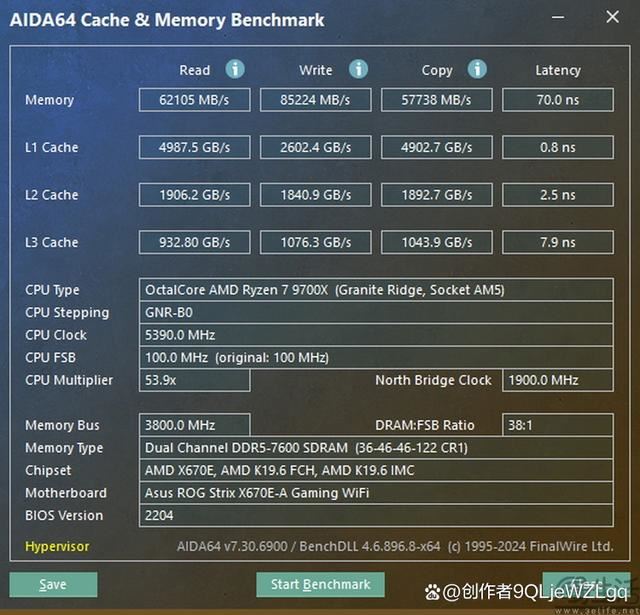
锐龙7 9700x的缓存测速成绩
但与9700x相比,9900x因为本身多了50%的核心,它的l1和l2缓存测速普遍比同架构的8核型号增长了50%左右。有意思的是,虽然9900x拥有“完整的”两组共64mb l3缓存,但它的l3缓存带宽并没有变成单ccd型号的两倍。这可能是因为缓存最终还是需要靠cpu核心去“调动”,所以多50%的核心也就意味着最多可以高50%的缓存吞吐量。
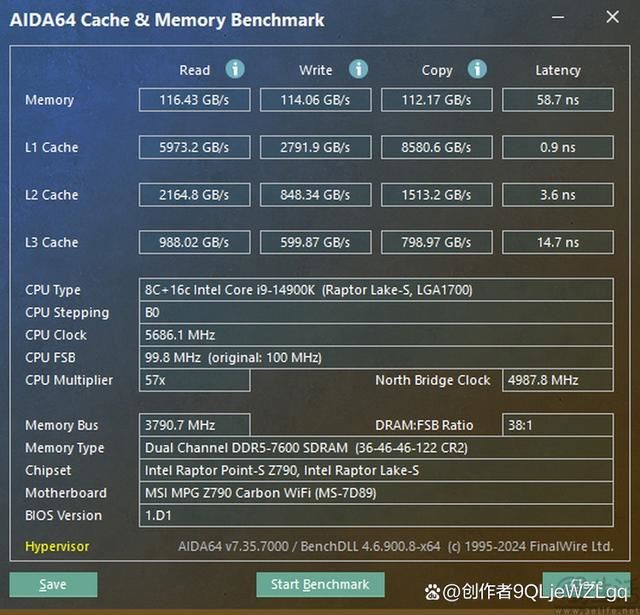
更有意思的是,我们还对比了使用相同内存配置下酷睿i9 14900k的内存和缓存性能。可以看到,amd与intel明显采用了截然不同的缓存设置策略。其中,前者的cpu内部缓存带宽更大、延迟更低,但因为将内存控制器集成在iod内,因此到cpu的延迟更大。后者则得益于更短的内存控制器到核心路径,外部内存带宽和延迟有优势,但本身较为落后的核心架构又导致核内缓存性能表现拉胯。
说实话,看到这样的内存和缓存测试数据不禁让我们产生了遐想,如果amd未来能更积极地采用先进片上互联封装,或许锐龙处理器的整个内存子系统就会迎来翻天覆地的改变。




发表评论