引言
pdf文档因其跨平台的兼容性和格式稳定性而备受青睐。然而,随着文档在不同用户间的流转,累积的注释可能会变得杂乱无章,甚至包含敏感或过时的信息,这不仅影响了文档的清晰度和专业性,还可能引发隐私风险。因此,适时地移除pdf文档中的注释非常重要,特别是在准备发布最终版本或与外部伙伴共享文档之前。利用python的强大功能,我们可以自动化这一过程,确保文档既干净又安全。
本文将演示如何使用python来删除pdf文档页面的注释。
本文所使用的方法需要用到spire.pdf for python,pypi:pip install spire.pdf。
用python移除pdf指定页面的指定注释
使用pdfdocument.loadfromfile()方法载入pdf文档后,我们可以使用pdfdocument.pages.get_item()获取文档中的指定页面,然后使用pdfpagebase.annotationswidget.removeat()方法根据注释参数删除指定注释。
以下是详细操作步骤:
- 导入所需模块
pdfdocument。 - 创建
pdfdocument实例。 - 使用
pdfdocument.loadfromfile()载入pdf文档。 - 使用
pdfdocument.pages.get_item()获取指定页面。 - 使用
pdfpagebase.annotationswidget.removeat()方法删除指定注释。 - 使用
pdfdocument.savetofile()方法保存pdf文档。 - 释放资源。
代码示例
from spire.pdf import pdfdocument
# 创建pdfdocument实例
pdf = pdfdocument()
# 载入pdf文档
pdf.loadfromfile("示例.pdf")
# 获取指定页面
page = pdf.pages.get_item(0)
# 删除指定注释
page.annotationswidget.removeat(0)
# 保存文档
pdf.savetofile("output/删除指定pdf注释.pdf")
pdf.close()
结果
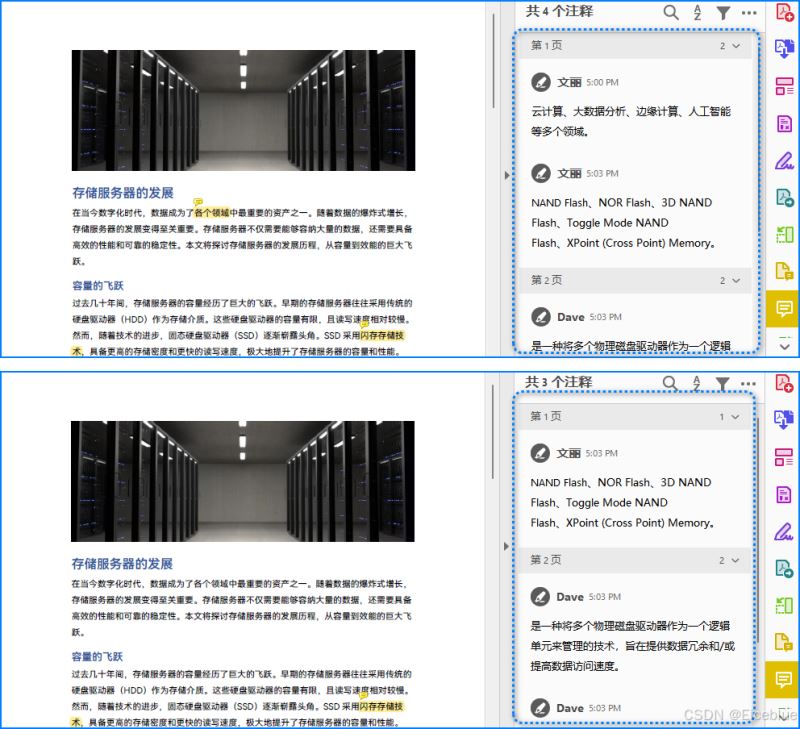
用python移除pdf文档中的所有注释
我们也可以使用相似的方法删除pdf文档中的所有注释,只需要遍历文档所有页面,使用pdfpagebase.annotationswidget.clear()方法删除页面的所有注释。
以下是详细操作步骤:
- 导入所需模块
pdfdocument。 - 创建
pdfdocument实例。 - 使用
pdfdocument.loadfromfile()载入pdf文档。 - 遍历文档中的页面:
- 使用
pdfdocument.pages.get_item()获取当前页面。 - 使用
pdfpagebase.annotationswidget.clear()方法删除页面的所有注释。
- 使用
- 使用
pdfdocument.savetofile()方法保存pdf文档。 - 释放资源。
代码示例
from spire.pdf import pdfdocument
# 创建pdfdocument实例
pdf = pdfdocument()
# 载入pdf文档
pdf.loadfromfile("示例.pdf")
# 循环pdf中的所有页面
for i in range(pdf.pages.count):
# 获取当前页面
page = pdf.pages.get_item(i)
# 删除当前页面的所有注释
page.annotationswidget.clear()
# 保存文档
pdf.savetofile("output/删除pdf所有注释.pdf")
pdf.close()
结果
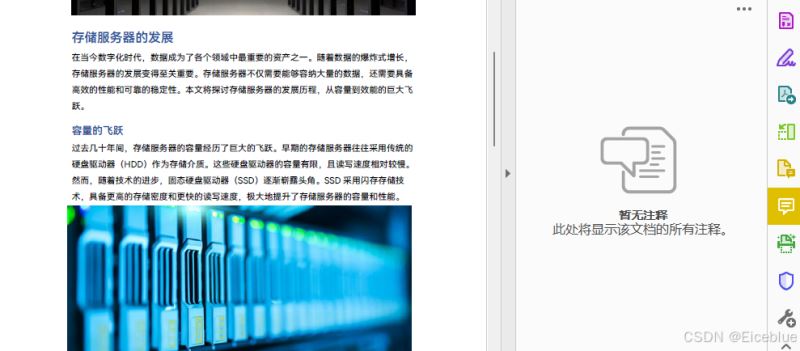
本文演示了如何使用python代码轻松删除pdf文档中的注释。
到此这篇关于使用python删除pdf文档页面注释的代码示例的文章就介绍到这了,更多相关python删除pdf注释内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论