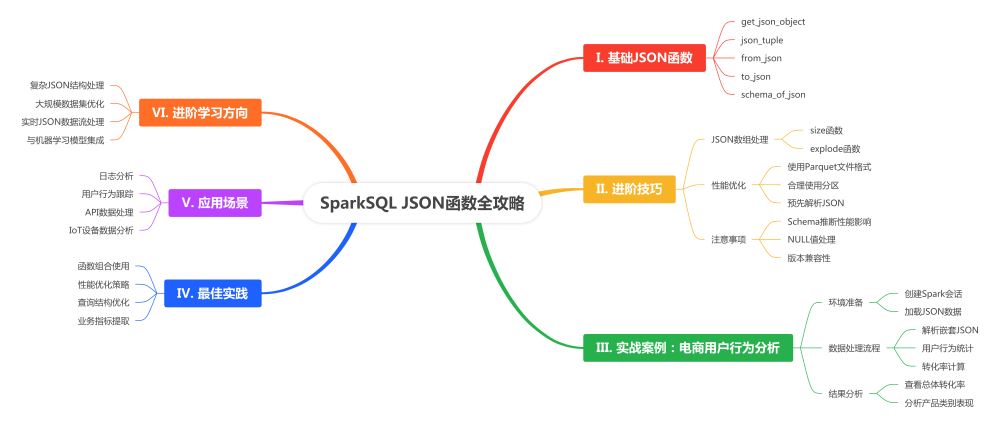
sparksql中的json函数快速入门

你是否曾经为处理json数据而头疼?sparksql为我们提供了强大的内置json函数,让json处理变得轻而易举。本文将带你深入了解这些函数,助你成为json处理高手!
为什么需要json函数?

在大数据处理中,json格式数据随处可见。无论是web日志、api响应还是iot设备数据,都可能以json形式存在。高效处理json数据成为每个数据工程师的必备技能。
sparksql json函数概览

sparksql提供了丰富的json处理函数,主要包括:
get_json_object: 提取json字段json_tuple: 同时提取多个json字段from_json: json字符串转结构化数据to_json: 结构化数据转json字符串schema_of_json: 推断json schema
接下来,我们将逐一深入探讨这些函数的使用方法和技巧。
get_json_object: json字段提取利器

get_json_object函数允许我们使用jsonpath表达式从json字符串中提取特定字段。
语法:
get_json_object(json_str, path)
示例:
select get_json_object('{"name":"john", "age":30}', '$.name') as name;
-- 输出: john这个函数特别适合从复杂json中提取单个字段。
json_tuple: 多字段提取神器
当需要同时提取多个json字段时,json_tuple函数是你的最佳选择。
语法:
json_tuple(json_str, key1, key2, ...)
示例:
select json_tuple('{"name":"john", "age":30, "city":"new york"}', 'name', 'age') as (name, age);
-- 输出: john, 30json_tuple能显著提高多字段提取的效率,减少重复解析。
from_json: json转结构化数据的桥梁
from_json函数将json字符串转换为结构化的spark数据类型,便于后续处理。

语法:
from_json(json_str, schema[, options])
示例:
select from_json('{"name":"john", "age":30}', 'struct<name:string, age:int>') as parsed_data;这个函数在处理嵌套json数据时特别有用。
to_json: 结构化数据转json的便捷工具

与from_json相反,to_json函数将结构化数据转换回json字符串。
语法:
to_json(expr[, options])
示例:
select to_json(struct("john" as name, 30 as age)) as json_data;
-- 输出: {"name":"john","age":30}在数据导出或api响应生成时,这个函数尤为实用。
schema_of_json: json schema推断神器

schema_of_json函数能自动推断json字符串的schema,省去手动定义的麻烦。
语法:
schema_of_json(json_str)
示例:
select schema_of_json('{"name":"john", "age":30, "scores":[85, 90, 92]}') as json_schema;这个函数在处理未知结构的json数据时特别有价值。
非常好,我们来继续深入探讨sparksql中的json函数,为读者提供更多实用的知识和技巧。
sparksql json函数进阶:性能优化与实战技巧
在上一篇文章中,我们介绍了sparksql中的基本json函数。今天,我们将更进一步,探讨如何优化这些函数的使用,以及在实际场景中的应用技巧。
json数组处理:size和explode函数
处理json数组是一个常见需求,sparksql为此提供了强大的支持。

size函数:获取数组长度
size函数可以用来获取json数组的长度。
语法:
size(json_array)
示例:
select size(from_json('{"scores":[85, 90, 92]}', 'struct<scores:array<int>>').scores) as array_size;
-- 输出: 3explode函数:展开json数组
explode函数能将json数组展开为多行,方便进行后续分析。
语法:
explode(array)
示例:
select explode(from_json('{"scores":[85, 90, 92]}', 'struct<scores:array<int>>').scores) as score;
-- 输出:
-- 85
-- 90
-- 92性能优化技巧

1. 使用parquet文件格式
将json数据转换为parquet格式可以显著提高查询性能。parquet是一种列式存储格式,特别适合于大数据分析。
-- 将json数据保存为parquet格式 create table parquet_table using parquet as select * from json_table;
2. 合理使用分区
对于大型json数据集,合理使用分区可以提高查询效率。
-- 按日期分区存储json数据 create table partitioned_json_table ( id int, data string, date string ) using json partitioned by (date);
3. 预先解析json
如果某些json字段经常被查询,可以考虑在etl阶段预先解析这些字段,避免重复解析。
create table parsed_json_table as select id, get_json_object(data, '$.name') as name, get_json_object(data, '$.age') as age, data from json_table;
实战案例:日志分析

假设我们有一个包含用户行为日志的json数据集,格式如下:
{
"user_id": 1001,
"timestamp": "2024-08-01t10:30:00z",
"actions": [
{"type": "click", "target": "button1"},
{"type": "view", "target": "page2"}
]
}我们要分析每个用户的点击次数。以下是实现这一需求的sparksql查询:
with parsed_logs as (
select
get_json_object(log, '$.user_id') as user_id,
explode(from_json(get_json_object(log, '$.actions'), 'array<struct<type:string,target:string>>')) as action
from log_table
)
select
user_id,
count(*) as click_count
from parsed_logs
where action.type = 'click'
group by user_id
order by click_count desc
limit 10;这个查询展示了如何结合使用get_json_object、from_json和explode函数来处理复杂的嵌套json数据。
注意事项
- schema推断: 虽然
schema_of_json很方便,但在处理大数据集时可能影响性能。对于已知结构的数据,最好手动定义schema。 - null值处理: json函数在处理null值时可能产生意外结果。始终做好null值检查和处理。
- 版本兼容性: sparksql的json函数在不同版本间可能有细微差异。升级spark版本时要注意测试兼容性。
结语
掌握这些高级技巧后,你将能够更加高效地处理sparksql中的json数据。记住,性能优化是一个持续的过程,要根据实际数据和查询模式不断调整你的策略。
现在,是时候将这些知识应用到你的实际项目中了。你会发现,即使是最复杂的json数据处理任务,也变得轻而易举!
当然,让我们通过一个详细的示例来展示如何在实际场景中运用sparksql的json函数。这个例子将涵盖数据加载、处理和分析的整个流程。
sparksql json函数实战:电商用户行为分析
假设我们是一家电商平台的数据分析师,需要分析用户的购物行为。我们有一个包含用户行为日志的json数据集,记录了用户的浏览、加入购物车和购买行为。
数据样例
{
"user_id": 1001,
"session_id": "a1b2c3d4",
"timestamp": "2024-08-01t10:30:00z",
"events": [
{"type": "view", "product_id": "p001", "category": "electronics"},
{"type": "add_to_cart", "product_id": "p001", "quantity": 1},
{"type": "purchase", "product_id": "p001", "price": 599.99}
]
}步骤1: 创建spark会话
首先,我们需要创建一个spark会话:
from pyspark.sql import sparksession
spark = sparksession.builder \
.appname("e-commerce user behavior analysis") \
.getorcreate()步骤2: 加载json数据
接下来,我们加载json数据并创建一个临时视图:
df = spark.read.json("path/to/user_logs.json")
df.createorreplacetempview("user_logs")步骤3: 数据处理和分析
现在,让我们使用sparksql的json函数来分析这些数据:
-- 1. 提取用户id和会话id
with parsed_logs as (
select
get_json_object(value, '$.user_id') as user_id,
get_json_object(value, '$.session_id') as session_id,
get_json_object(value, '$.timestamp') as event_time,
explode(from_json(get_json_object(value, '$.events'), 'array<struct<type:string,product_id:string,category:string,quantity:int,price:double>>')) as event
from user_logs
),
-- 2. 分析用户行为
user_behavior as (
select
user_id,
session_id,
count(case when event.type = 'view' then 1 end) as view_count,
count(case when event.type = 'add_to_cart' then 1 end) as cart_add_count,
count(case when event.type = 'purchase' then 1 end) as purchase_count,
sum(case when event.type = 'purchase' then event.price else 0 end) as total_purchase_amount
from parsed_logs
group by user_id, session_id
),
-- 3. 计算转化率
conversion_rates as (
select
count(distinct case when view_count > 0 then user_id end) as users_with_views,
count(distinct case when cart_add_count > 0 then user_id end) as users_with_cart_adds,
count(distinct case when purchase_count > 0 then user_id end) as users_with_purchases
from user_behavior
)
-- 4. 输出分析结果
select
users_with_views as total_active_users,
users_with_cart_adds as users_adding_to_cart,
users_with_purchases as users_making_purchase,
round(users_with_cart_adds / users_with_views * 100, 2) as view_to_cart_rate,
round(users_with_purchases / users_with_cart_adds * 100, 2) as cart_to_purchase_rate,
round(users_with_purchases / users_with_views * 100, 2) as overall_conversion_rate
from conversion_rates;让我们逐步解释这个查询:
parsed_logs: 使用get_json_object提取顶层字段,并用explode和from_json展开嵌套的事件数组。user_behavior: 统计每个用户会话的各类行为次数和总购买金额。conversion_rates: 计算不同行为的用户数量。最后计算并输出各种转化率。
步骤4: 执行查询并查看结果
result = spark.sql("""
-- 在这里粘贴上面的sql查询
""")
result.show()输出可能如下所示:
+------------------+---------------------+----------------------+-----------------+----------------------+------------------------+
|total_active_users|users_adding_to_cart|users_making_purchase|view_to_cart_rate|cart_to_purchase_rate|overall_conversion_rate|
+------------------+---------------------+----------------------+-----------------+----------------------+------------------------+
| 10000| 6000| 3000| 60.00| 50.00| 30.00|
+------------------+---------------------+----------------------+-----------------+----------------------+------------------------+
步骤5: 进一步分析
我们还可以深入分析最受欢迎的产品类别:
select event.category, count(*) as view_count, sum(case when event.type = 'purchase' then 1 else 0 end) as purchase_count, round(sum(case when event.type = 'purchase' then 1 else 0 end) / count(*) * 100, 2) as conversion_rate from parsed_logs where event.category is not null group by event.category order by view_count desc limit 5;
结语
通过这个实例,我们展示了如何使用sparksql的json函数来处理复杂的嵌套json数据,并进行有意义的商业分析。这种方法可以轻松扩展到处理更大规模的数据集,帮助我们从海量的用户行为数据中提取有价值的洞察。
记住,在处理大规模数据时,可能需要进一步优化查询性能,例如使用适当的分区策略,或者预先解析和存储常用的json字段。
总结 sparksql json函数从基础到实战
在大数据时代,json 格式因其灵活性和广泛应用而成为数据处理的重要一环。sparksql 提供了强大的内置 json 函数,让我们能够高效地处理复杂的 json 数据。本文全面总结了这些函数的使用方法、优化技巧及实战应用。
核心 json 函数概览
get_json_object: 提取单个 json 字段json_tuple: 同时提取多个 json 字段from_json: json 字符串转结构化数据to_json: 结构化数据转 json 字符串schema_of_json: 推断 json schema
进阶技巧
- json 数组处理
size: 获取数组长度
explode: 展开 json 数组为多行
- 性能优化
- 使用 parquet 文件格式
- 合理设置分区
- 预先解析常用 json 字段
- 注意事项
- schema 推断可能影响性能
- 注意 null 值处理
- 关注版本兼容性
实战案例:电商用户行为分析
我们通过一个电商平台用户行为分析的案例,展示了如何在实际场景中应用这些 json 函数:
- 创建 spark 会话
- 加载 json 数据
- 使用 sql 查询处理数据
- 解析嵌套 json 结构
- 统计用户行为
- 计算转化率
- 执行查询并分析结果
关键代码片段:
with parsed_logs as (
select
get_json_object(value, '$.user_id') as user_id,
get_json_object(value, '$.session_id') as session_id,
explode(from_json(get_json_object(value, '$.events'), 'array<struct<type:string,...>>')) as event
from user_logs
),
-- 后续数据处理和分析...核心要点
- 灵活运用函数组合:如
get_json_object与explode配合使用 - 性能优先:合理使用 schema 定义,避免过度依赖自动推断
- 数据层次化处理:使用 cte (common table expression) 使查询更清晰
- 商业洞察导向:从原始数据中提取有价值的业务指标
通过掌握这些 sparksql json 函数及其应用技巧,数据工程师和分析师可以更加高效地处理复杂的 json 数据,从海量信息中挖掘有价值的商业洞察。
记住,实践是掌握这些技能的关键。不断在实际项目中应用这些知识,你将成为 json 数据处理的专家!
到此这篇关于sparksql中的json内置函数全解析的文章就介绍到这了,更多相关sparksql中json内置函数内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论