欢迎访问我的github
关于ollama
- ollama和llm(大型语言模型)的关系,类似于docker和镜像,可以在ollama服务中管理和运行各种llm,下面是ollama命令的参数,与docker管理镜像很类似,可以下载、删除、运行各种llm
available commands:
serve start ollama
create create a model from a modelfile
show show information for a model
run run a model
pull pull a model from a registry
push push a model to a registry
list list models
cp copy a model
rm remove a model
help help about any command
- 官网:https://ollama.com/
- 非常简洁
本篇概览
- 作为入门操作的笔记,本篇记录了部署和简单体验ollama的过程,并且通过docker部署了web-ui,尝试通过页面使用大模型
- 本次操作的环境如下
- 电脑:macbook pro m1,sonoma 14.4.1
- ollama:0.1.32
安装
- 在官网首页点击download即可下载,得到zip安装包,解压后就是应用程序了
- 会提示是否移动到应用程序目录,回车确认

- 打开后是个简单的页面
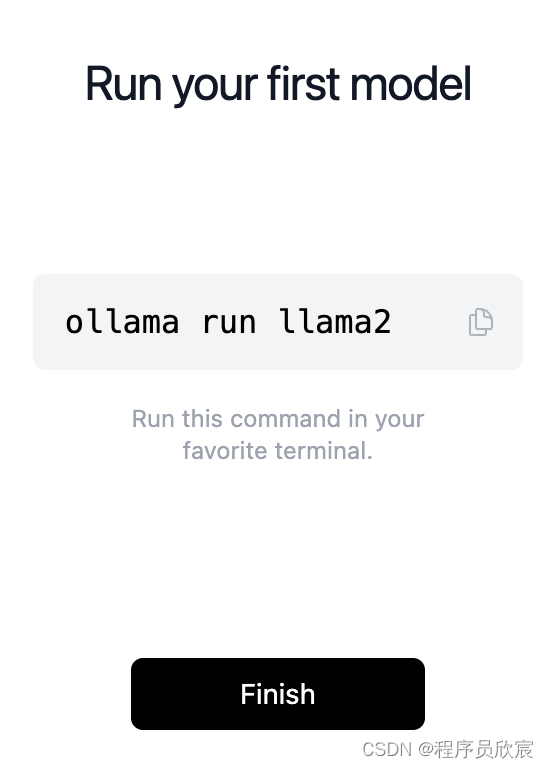
- 完成安装,会有一个提示,告诉你如何安装指定模型
关于模型
- ollama支持的全量模型在这里:https://ollama.com/library
- 官方给出的部分模型
| model | parameters | size | 下载命令 |
|---|---|---|---|
| llama 3 | 8b | 4.7gb | ollama run llama3 |
| llama 3 | 70b | 40gb | ollama run llama3:70b |
| phi-3 | 3.8b | 2.3gb | ollama run phi3 |
| mistral | 7b | 4.1gb | ollama run mistral |
| neural chat | 7b | 4.1gb | ollama run neural-chat |
| starling | 7b | 4.1gb | ollama run starling-lm |
| code llama | 7b | 3.8gb | ollama run codellama |
| llama 2 uncensored | 7b | 3.8gb | ollama run llama2-uncensored |
| llava | 7b | 4.5gb | ollama run llava |
| gemma | 2b | 1.4gb | ollama run gemma:2b |
| gemma | 7b | 4.8gb | ollama run gemma:7b |
| solar | 10.7b | 6.1gb | ollama run solar |
- 另外需要注意的是本地内存是否充足,7b参数的模型需要8g内存,13b需要16g内存,33b需要32g内存
运行8b的llama3
- 我的mac笔记本内存16g,所以打算运行8b的llama3,命令如下
ollama run llama3
- 第一次运行,因为没有模型文件,所以需要下载,等待下载中
 - 下载完毕后就可以问答了
- 下载完毕后就可以问答了
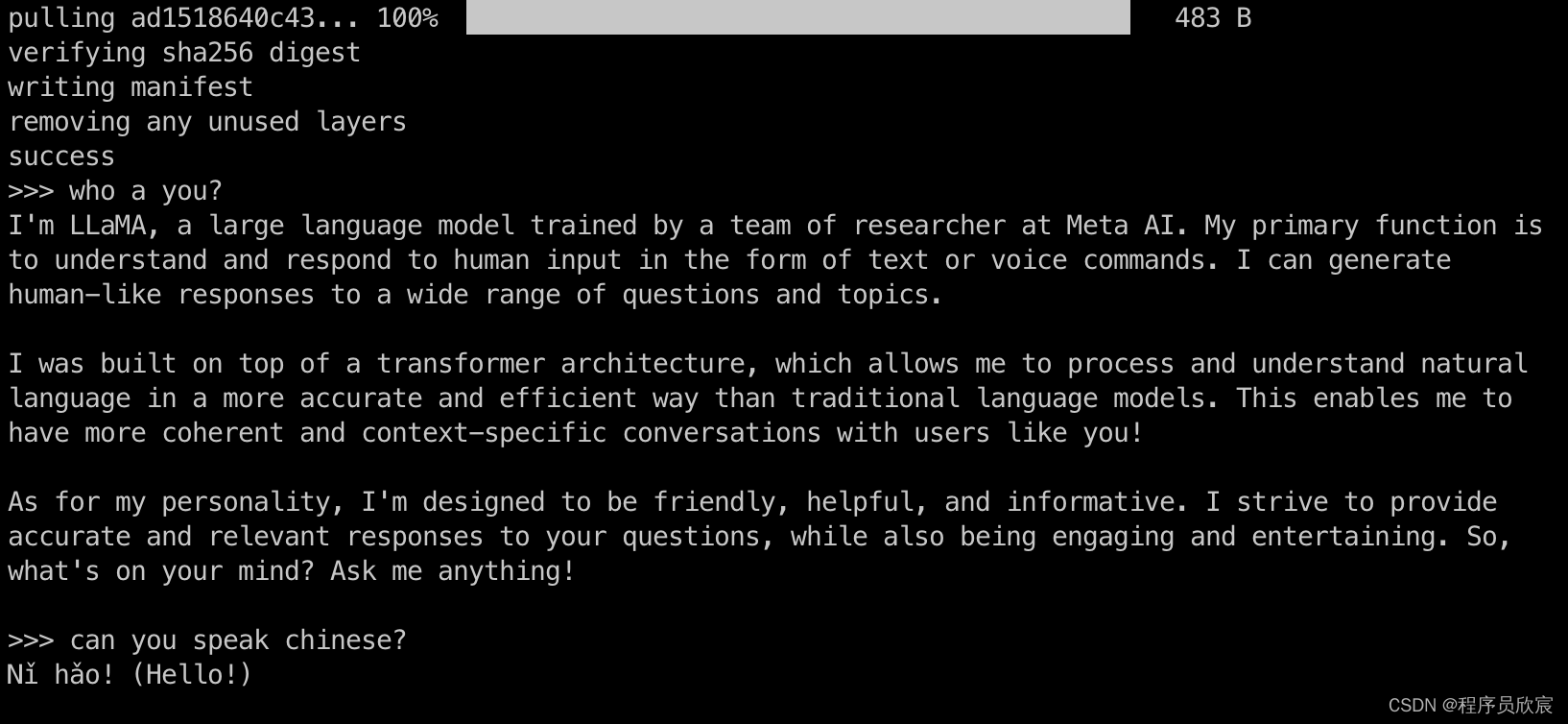
- 退出的方法是输入/bye
linux版本
- 如果操作系统是linux,安装命令如下
curl -fssl https://ollama.com/install.sh | sh
- 安装完成后还要启动
ollama serve
webui
- 如果电脑上装有docker,请执行以下命令来启动ollama的webui
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- 出现登录页面,需要点击右下角的sign up先注册
- 完成注册后,第一次登录会出现特性介绍
- 可以在这里修改系统语言
- 接下来试试聊天功能,先是选择模型,由于刚才已经下载过模型了,这里只要选择即可,如下图
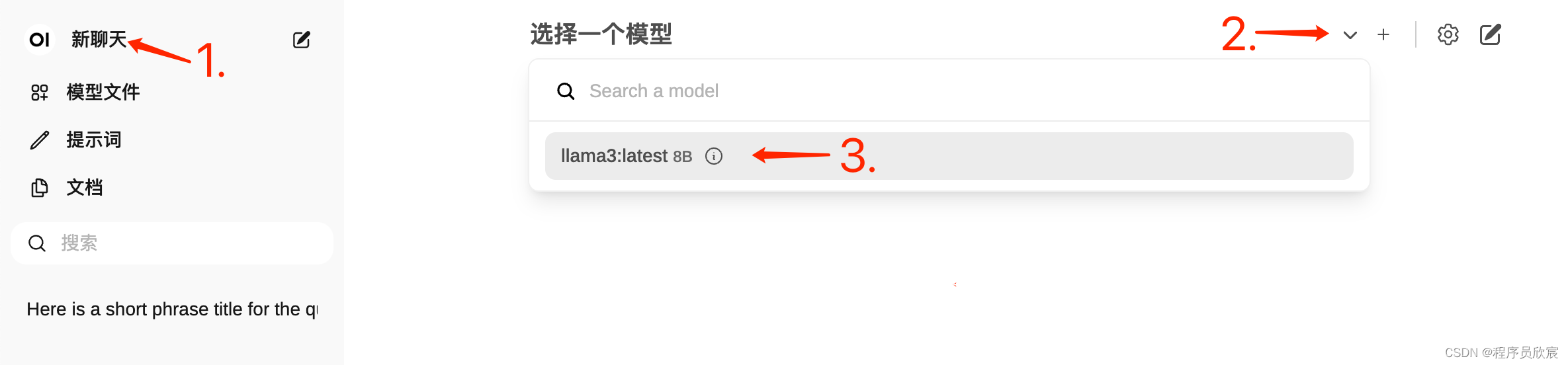
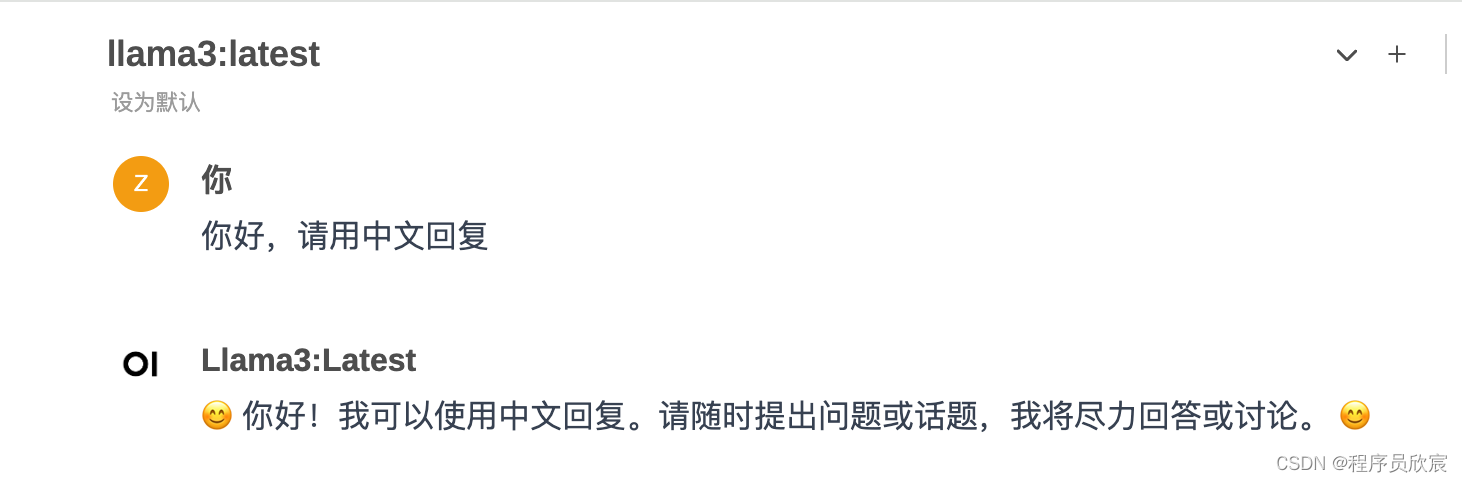
- 然后就可以对话了
- 在设置页面可以管理模型

- 至此,最基础的操作已经完成,如果您正处于初步尝试阶段,希望本文可以给您一些参考



发表评论