opencv 入门系列:
本文主要内容:
- 如何训练 opencv 的人脸识别模型
- 如何在 windows 下利用 opencv 进行人脸识别
1、概述
人脸识别需要人脸模型(特征集合)的支持,人脸定位的速度与准确度取决于模型。
opencv 提供了已经训练好的模型,无论是 windows 版本还是 android 版本的 sdk,都在 etc 目录下提供了两种级联分类器模型:
“haarcascades” 和 “lbpcascades” 都是级联分类器模型,用于目标检测和识别,特别是在人脸检测领域中常被使用:
- haarcascades 基于 haar-like 特征(哈尔特征)的级联分类器。haar-like 特征是一种基于像素差值的特征描述方法,通过计算图像中不同区域的像素值之和的差异,来捕捉图像中的纹理和形状信息。haarcascades 模型使用了这些特征来构建级联分类器,以在图像中快速检测人脸或其他目标
- lbpcascades 使用的是局部二值模式(local binary patterns,lbp)特征的级联分类器。lbp 特征是一种描述图像纹理的方法,通过比较像素点与其邻域像素的灰度值,将其转化为二进制编码。lbpcascades 模型利用这些二进制编码来构建级联分类器,用于目标检测和识别,例如人脸检测
两个文件夹内都提供了多种模型用以识别物体,比如 lbpcascades 文件夹下的 lbpcascade_frontalface.xml 可以用于识别人脸,lbpcascade_frontalcatface.xml 用于识别猫脸:
windows 版本的 sdk 提供了文档与演示代码,在 opencv\sources\doc\tutorials 目录下,比如 objdetect 就是介绍物体识别的。比如 cascade_classifier.markdown 介绍级联分类器,traincascade.markdown 介绍如何训练模型。当然这些文档都是英文的,如果想查看中文文档,可以去 opencv 的中国 wiki 论坛提供的中文文档,比如级联分类器训练。此外演示代码在 opencv\sources\samples\ 目录下,android 相关的演示在 android 目录中。
除了使用 opencv 提供的级联分类器模型,我们也可以使用 opencv 提供的工具自己训练模型,具体的操作方法会在下一节介绍。
2、人脸模型训练
opencv 识别事务实际上就是对事物进行分类。给 opencv 各种样本去学习,使得 opencv 学习区分不同类别的事物。以人脸为例,给 opencv 的正样本全都是各种人脸,负样本全是与人脸无关的事物,那么 opencv 就能识别出什么人脸,什么不是。因此供 opencv 学习的样本越多越好。
opencv 提供的模型可以识别所有人脸,假如现在有个需求,就是只识别某一个人脸,其他的不识别,该如何实现呢?
这就需要自己训练模型了。假如要求只识别你的人脸,那么在采集图像时,保证摄像头内只有你的脸,通过 opencv 识别到人脸,然后将人脸部分转为 24 * 24 的灰度图保存到指定的目录内。用目录内的这些小图片通过 opencv 提供的工具进行训练,就可以训练出只识别你的脸的模型。
说到 opencv 的训练工具,这里要特别说明一下。我们写 demo 用的是 opencv 的 4.1.0 版本,但是在该版本中,训练工具被移除了。在 3.4.x 版本中,这个工具是存在的(如 3.4.6 或 3.4.16 等版本都行):
因此我们需要再下载一个包含训练工具的 opencv 版本,然后在 opencv\build\x64\vc15\bin 目录下找到 opencv_createsamples.exe 和 opencv_traincascade.exe 工具,可以将目录添加到环境变量中。
2.1 训练步骤
训练模型需要正样本和负样本:
- 正样本就是与目标模型相关性强的。比如训练只识别你的人脸的模型,那么前面收集的人脸灰度图就是正样本
- 负样本就是与目标模型相关性弱的,甚至没有相关性的。比如训练人脸识别模型,那么负样本就可以是风景图等等
我们将正样本存入 pos 目录,将负样本存入 neg 目录,然后再创建正样本和负样本的描述文件 positive.txt 和 neg.txt:
样本描述文件格式为文件名、人脸数量、每个人脸的起始坐标与宽高范围:
2 个人脸分别为 (100,200) 处为左上角,宽高为 50x50 的范围和 (50,30) 处为左上角,宽高为 25x25 的范围
pos/1.jpg 2 100 200 50 50 50 30 25 25
按照上述格式,我们的正样本可以写为:
pos/0.jpg 1 0 0 24 24
pos/1.jpg 1 0 0 24 24
pos/2.jpg 1 0 0 24 24
pos/3.jpg 1 0 0 24 24
pos/4.jpg 1 0 0 24 24
pos/5.jpg 1 0 0 24 24
pos/6.jpg 1 0 0 24 24
中间省略...
pos/61.jpg 1 0 0 24 24
负样本也是类似的操作。当然需要注意正负样本的比例最好是 1:3,比如正样本有 100 个,负样本最好就是 300 个。
接下来就使用 opencv 提供的工具训练模型:
-
首先运行 opencv_createsamples 命令创建正样本的向量文件:
# -info: 正样本描述文件 # -vec : 输出的正样本向量 # -num : 正样本数量 # -w -h: 输出样本的大小 c:\users\desktop\train>opencv_createsamples -info positive.txt -vec pos.vec -num 61 -w 24 -h 24如果运行成功则会如上图所示在当前目录下生成 pos.vec 文件,log 会输出:
create training samples from images collection... done. created 61 samples如果因为文件路径不匹配,则运行会报错:
create training samples from images collection... unable to open image: pos/pos/1.jpg opencv: terminate handler is called! the last opencv error is: opencv(3.4.16) error: assertion failed (0 <= roi.x && 0 <= roi.width && roi.x + roi.width <= m.cols && 0 <= roi.y && 0 <= roi.height && roi.y + roi.height <= m.rows) in cv::mat::mat, file c:\build\3_4_winpack-build-win64-vc15\opencv\modules\core\src\matrix.cpp, line 751 -
然后运行 opencv_traincascade 进行训练:
# -data : 需要手动创建,训练的模型作为结果会输出到这个目录 # -vec : 正样本 # -bg : 负样本 # -numpos :每级分类器训练时所用到的正样本数目 # -numneg :每级分类器训练时所用到的负样本数目,可以大于 -bg 数目 # -numstages:训练分类器的级数,如果层数多,分类器的误差就更小,但是检测速度慢。(15-20) # -featuretype: 采用 lbp 算法 # -w -h:负样本的宽高可以设置的随意些,只要起始点 + 宽高不超过图片像素范围即可 c:\users\desktop\train>opencv_traincascade -data data -vec pos.vec -bg neg.txt -numpos 61 -numneg 300 -numstages 15 -featuretype lbp -w 24 -h 24如果你没有手动创建 data 目录,运行上述命令会报错说无法打开 data/params.xml 文件:
===== training 0-stage ===== <begin pos count : consumed 61 : 61 neg count : acceptanceratio 300 : 1 precalculation time: 0.026 +----+---------+---------+ | n | hr | fa | +----+---------+---------+ | 1| 1| 0| +----+---------+---------+ end> parameters can not be written, because file data/params.xml can not be opened.创建 data 后再次运行可能会有如下结果之一:
# 1.训练成功 training until now has taken 0 days 0 hours 0 minutes 10 seconds. # 2.可以认为该训练阶段是成功的,达到了所需的叶子误报率,并且分支训练已经终止(样本太少,模型质量不行) required leaf false alarm rate achieved. branch training terminated. # 3.错误 bad argument < can not get new positive sample. the most possible reason is insufficient count of samples in given vec-file.
训练成功后会在 data 目录下得到如下文件:
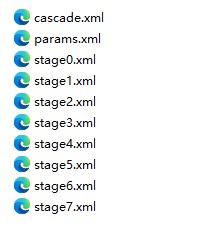
cascade.xml 就是我们训练出的库文件,将其拷贝到手机中,修改代码,用 cascade.xml 替代 opencv 提供的 lbpcascade_frontalface.xml:
// 初始化 opencv
val path = file(
environment.getexternalstoragedirectory(),
/*"lbpcascade_frontalface.xml"*/
"cascade.xml"
).absolutepath
mopencvjni.init(path)
使用 cascade.xml 模型去做人脸识别时,就只会识别训练样本中的人脸,而不会像 opencv 提供的 lbpcascade_frontalface.xml 识别所有人脸,这种识别特定人脸的需求与我们上班打卡的机器原理是类似的。
2.2 算法简介
lbp(local binary patterns,局部二值模式)是一种用于纹理分析和模式识别的图像特征描述算法。它于 1994 年由 ojala 等人提出,并被广泛应用于人脸识别、纹理分类、物体检测和图像检索等领域。
lbp 算法的基本思想是对图像中的每个像素点,根据其周围像素的灰度值进行编码,形成一个局部的二值模式。该编码方法具有旋转不变性和灰度不变性的特点,使得 lbp 特征适用于处理灰度图像。
lbp 算法的步骤如下:
-
对于图像中的每个像素点,选择一个固定大小的邻域窗口(通常为 3 × 3 或 5 × 5 的正方形)。
-
将邻域窗口中心像素的灰度值与邻域窗口中的其他像素逐一比较,若中心像素的灰度值大于或等于相邻像素的灰度值,则该像素点的位置被标记为 1,否则标记为 0。
-
将邻域窗口中的 8 个二值编码按顺时针或逆时针顺序排列,形成一个 8 位二进制数,即得到该像素点的 lbp 编码。
-
遍历图像中的所有像素点,重复步骤 2 和步骤 3,得到整幅图像的 lbp 编码图像。
-
统计 lbp 编码图像中不同 lbp 模式的出现频率,作为图像的 lbp 特征向量。
lbp 算法的主要优点是计算简单、特征表达能力强、对光照变化具有一定的不变性。然而,它也有一些不足之处,例如对噪声和旋转变化敏感。
3、windows 人脸识别
这一节现在 windows 上实现人脸识别,因为 windows 上查看中间结果(灰度图、直方图等等)比较方便。我们在 visual studio 中新建项目,驱动电脑的摄像头进行人脸识别。
3.1 代码实现
实现过程大致可分为三步:
- 加载 opencv 提供的级联分类器以具备人脸识别能力
- 打开摄像头
- 对摄像头采集到的数据进行灰度化、均衡化处理后进行人脸识别,在识别出人脸的位置画一个矩形
代码如下:
void detect() {
// 1.加载级联分类器
if (!face_cascadeclassifier.load("g:/tools/opencv/build/etc/haarcascades/haarcascade_frontalface_alt.xml")) {
cout << "级联分类器加载失败!" << endl;
}
// 2.开启摄像头进行录制
videocapture capture;
capture.open(0);
if (!capture.isopened())
{
cout << "opencv 打开摄像头失败!\n" << endl;
return;
}
// 3.处理采集到的图像
mat frame; // 摄像头彩色图像
mat gray; // 摄像头灰度图像
while (true)
{
// 采集到的图像存入 frame
capture >> frame;
if (frame.empty()) {
cout << "opencv 读取摄像头图像失败!" << endl;
return;
}
// 灰度化处理,注意 opencv 颜色排序为 bgr
cvtcolor(frame, gray, color_bgr2gray);
// 直方图均衡化,增强对比度
equalizehist(gray, gray);
// 一张图片可能包含多张人脸,因此保存结果的是一个集合
vector<rect> faces;
// 对灰度图进行人脸识别,识别结果保存在 faces 集合中
face_cascadeclassifier.detectmultiscale(gray, faces);
for each (rect face in faces)
{
// 在 frame 这张图片的 face 上画一个 bgr 颜色为 (0, 0, 255) 即红色的矩形
rectangle(frame, face, scalar(0, 0, 255));
// 这种方式来检测相机实时人脸图像非常卡顿!只适合静态图像的检测
}
// 显示图像
imshow("摄像头", frame);
// wait 30ms,如果按 esc 键就退出
if (waitkey(30) == 27)
{
break;
}
}
}
运行起来会发现虽然确实可以识别出人脸,在人脸位置画一个红色矩形,但是图像非常卡顿。这是因为不论是 opencv 还是 tensorflow,检测人脸都是很耗时的,检测一次大概需要 1 ~ 2 秒的时间。因此我们不能向上面这样,对每一帧视频图片都进行检测,而是先检测到人脸,后续采用人脸跟踪。
下面对上述代码进行改造。
3.2 代码优化
上面提到,优化视频画面卡顿的方法是检测第一帧,检测到后,对后续的帧进行人脸跟踪。那么在 opencv 中,人脸检测的任务交给主检测适配器,人脸跟踪的任务交给跟踪检测适配器。这两种适配器必须是 detectionbasedtracker::idetector 的子类。我们直接使用 opencv 提供的代码示例 opencv\sources\samples\android\face-detection\jni\detectionbasedtracker_jni.cpp 中定义的 cascadedetectoradapter 写入 opencv.h:
# pragma once
#include <iostream>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
cascadeclassifier face_cascadeclassifier;
cv::ptr<detectionbasedtracker> tracker;
class cascadedetectoradapter : public detectionbasedtracker::idetector
{
public:
cascadedetectoradapter(cv::ptr<cv::cascadeclassifier> detector) :
idetector(),
detector(detector)
{
cv_assert(detector);
}
// 每张 image 图片中都可能会有多张人脸 objects,因此可能会多次调用 detect 进行识别
void detect(const cv::mat& image, std::vector<cv::rect>& objects)
{
detector->detectmultiscale(image, objects, scalefactor, minneighbours, 0, minobjsize, maxobjsize);
}
virtual ~cascadedetectoradapter()
{
}
private:
cascadedetectoradapter();
cv::ptr<cv::cascadeclassifier> detector;
};
接下来我们通过宏定义的方式在原始代码上进行优化,加入使用跟随策略进行人脸检测的代码:
// 定义此宏则收集人脸图片数据保存到指定位置
#define collect_samples
// 收集的人脸图片编号
int i = 0;
// 一次识别,后续跟踪来解决只通过检测的方式的卡顿问题
void track() {
// 如果定义了 detect 宏,则每一帧都进行检测,否则只检测一帧,后续跟随,这里我们没有定义这个宏
#ifdef detect
// 1.加载级联分类器,注意路径一定是斜杠而不是反斜杠,否则会加载失败
if (!face_cascadeclassifier.load("g:/tools/opencv/build/etc/haarcascades/haarcascade_frontalface_alt.xml")) {
cout << "级联分类器加载失败!" << endl;
return;
}
#else
// 2.创建跟踪器并运行
// 2.1 创建主检测适配器
cv::ptr<cascadedetectoradapter> maindetector = makeptr<cascadedetectoradapter>(
makeptr<cascadeclassifier>("g:/tools/opencv/build/etc/haarcascades/haarcascade_frontalface_alt.xml"));
// 2.2 创建跟踪检测适配器
cv::ptr<cascadedetectoradapter> trackingdetector = makeptr<cascadedetectoradapter>(
makeptr<cascadeclassifier>("g:/tools/opencv/build/etc/haarcascades/haarcascade_frontalface_alt.xml"));
// 2.3 创建跟踪器
detectionbasedtracker::parameters detectorparams;
tracker = makeptr<detectionbasedtracker>(maindetector, trackingdetector, detectorparams);
// 2.4 开始检测
tracker->run();
#endif
// 3.开启摄像头进行录制
videocapture capture;
capture.open(0);
if (!capture.isopened())
{
cout << "opencv 打开摄像头失败!\n" << endl;
return ;
}
// 4.处理采集到的图像
mat frame; // 摄像头彩色图像
mat gray; // 摄像头灰度图像
while (true)
{
// 采集到的图像存入 frame
capture >> frame;
if (frame.empty()) {
cout << "opencv 读取摄像头图像失败!\n" << endl;
return ;
}
// 灰度化处理,注意 opencv 颜色排序为 bgr
cvtcolor(frame, gray, color_bgr2gray);
// 直方图均衡化,增强对比度
equalizehist(gray, gray);
// 一张图片可能包含多张人脸,因此要保存在 faces 集合中
vector<rect> faces;
// 如果每帧都识别,则通过 detectmultiscale,否则用 tracker 进行识别
#ifdef detect
face_cascadeclassifier.detectmultiscale(gray, faces);
#else
tracker->process(gray);
tracker->getobjects(faces);
#endif // detect
for each (rect face in faces)
{
// 在 frame 这张图片的 face 上画一个 bgr 颜色为 (0, 0, 255) 即红色的矩形
rectangle(frame, face, scalar(0, 0, 255));
// 这种方式来检测相机实时人脸图像非常卡顿!只适合静态图像的检测
#ifdef collect_samples
// 采集人脸样本,转换为 24 * 24 的灰度图保存到指定路径的文件中
mat sample;
frame(face).copyto(sample);
resize(sample, sample, size(24, 24));
cvtcolor(sample, sample, color_bgr2gray);
char p[100];
// 目录需要手动创建,否则不会自动生成
sprintf(p, "d:/opencv/train/face/pos/%d.jpg", i++);
//imread 读取文件图像
imwrite(p, sample);//将mat写入文件
#endif // collect_samples
}
// 显示图像
imshow("摄像头", frame);
// esc 键退出
if (waitkey(30) == 27)
{
break;
}
}
#ifndef detect
tracker->stop();
#endif // !detect
}
简要说明:
- 在第 2 步创建跟踪器时,使用了 opencv 的智能指针 ptr 模板类,它采用引用计数型的句柄类实现计数。自动管理对象的释放,ptr 中调用 release() 会将引用计数器减 1,如果计数器为 0 则会删除该对象。使用 ptr 声明的对象可以不用手动释放
- 创建的 maindetector 负责检测,trackingdetector 负责跟随,调用 tracker->run() 会开启一个线程,其内部有一个无限循环,当 tracker->process() 传入灰度图开始检测后,检测到的人脸数据可以通过 tracker->getobjects(faces) 获取,faces 是一个
vector<rect>类型的入参出参数据,保存着一张图片中的所有人脸 - 我们定义了 collect_samples 宏用来收集人脸数据,将采集到的人脸图像转成灰度图再把尺寸设置为 24 * 24 保存在指定目录中,这些图片可以帮助我们使用 2.1 节中介绍的方法训练自己的模型
应用以上代码后就可以流畅的识别出人脸了。


发表评论