【6d位姿估计】【深度学习】windows10下gen6d代码pytorch实现
文章目录
前言
gen6d是由港大&浙大的liu, yuan等人在《gen6d: generalizable model-free 6-dof object pose estimation from rgb images【eccv2022】》【论文地址】一文中提出了不需要cad模型或者可渲染模型就可以泛化到新物体的位姿估计算法。之前的算法每次都只能针对某个特定的物体(例如pvnet/aae)或者某个特定的物体类别(例如nocs)进行位姿估计,而不能泛化到没见过的物体,论文提出的算法只需利用最容易获得的rgb图片,而不需要额外的物体mask或者深度相机得到的深度,就可以泛化到新物体的位姿估计算法。
在详细解析gen6d网络之前,首要任务是搭建gen6d【pytorch-demo地址】所需的运行环境,并完成模型训练和测试工作,展开后续工作才有意义。
下载源码并安装环境
在,方便搭建专用于gen6d模型的虚拟环境。
# 创建虚拟环境
conda create -y -n gen6d python=3.8
# 查看新环境是否安装成功
conda env list
# 激活环境
activate gen6d
# 下载githup源代码到合适文件夹,并cd到代码文件夹内(科学上网)
git clone https://github.com/liuyuan-pal/gen6d.git
cd gen6d
# 安装pytorch包
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# 安装其他依赖包(需要删除关于pytorch的部分)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# 查看所有安装的包
pip list
conda list
最终的安装的所有包:
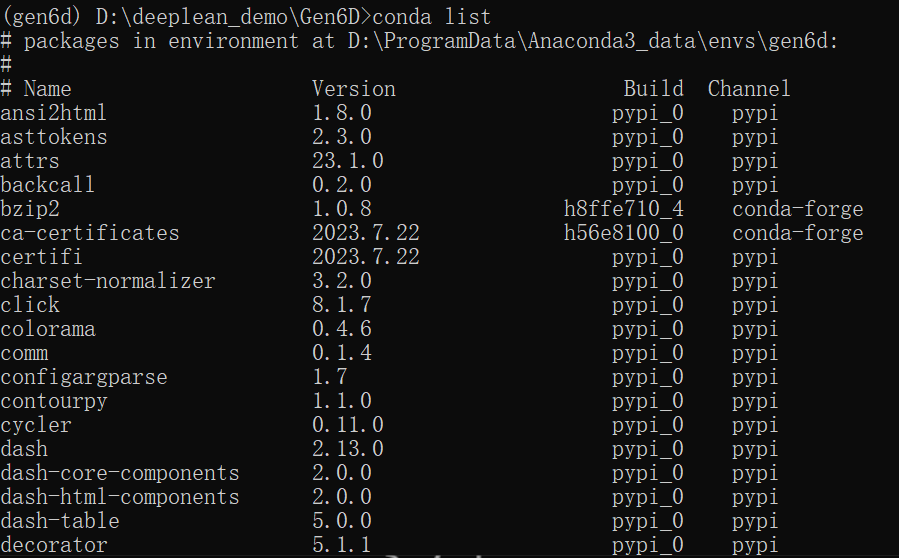
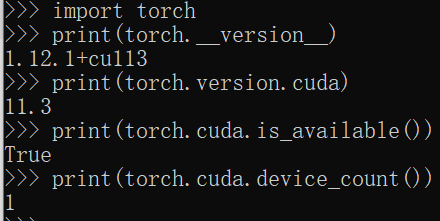
检查torch版,已经安装torch-gpu版本
# 查看pytorch版本
import torch
print(torch.__version__)
# 查看cuda版本
print(torch.version.cuda)
# 查看cuda是否可用
print(torch.cuda.is_available())
# 查看可用cuda数量
print(torch.cuda.device_count())
安装 pytorch3d
安装pytorch3d参考
1.安装必要依赖库
# 这里可能需要anaconda的默认源安装
conda install -c conda-forge -c fvcore -c iopath -c bottler fvcore iopath
2.cub安装配置: 查询对照表:
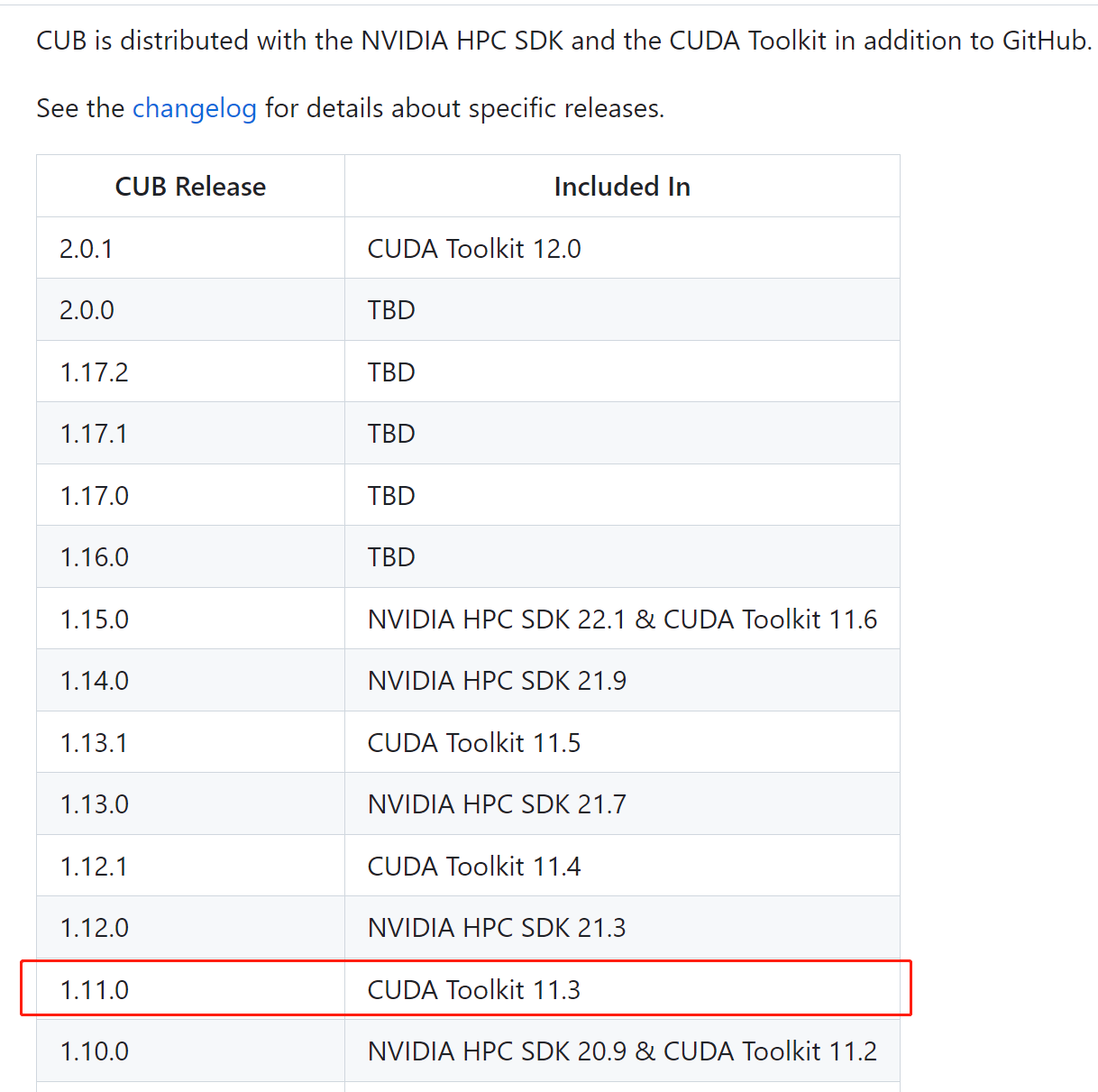
根据自己的cuda 版本选择对应的cub realase版本下载,对应cub 1.11.0 (cuda toolkit 11.3):

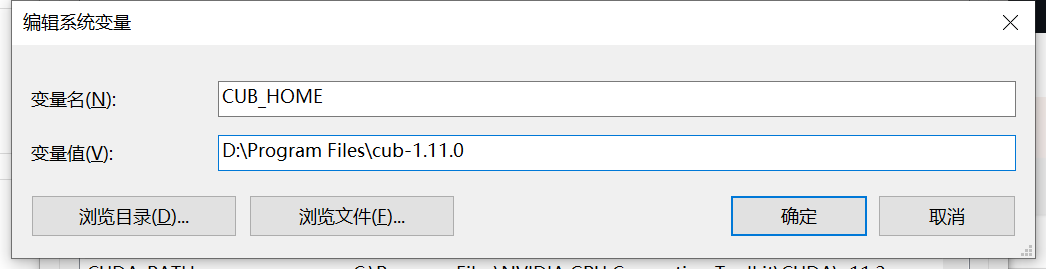
下载解压后,在环境变量中添加cub的文件的路径(cub_home):
3.安装pytorch3d: 下载解压pytorch3d源码,注意版本要与pytorch对应,每个版本下有注明其适用的pytorch版本。
# 创建文件夹,将下载好的pytorch3d放到该目录下(重命名)
mkdir -p external
下载0.7.1版本的pytorch3d版本,并解压到gen6d工程的external/目录下(博主将文件重命名为pytorch3d):

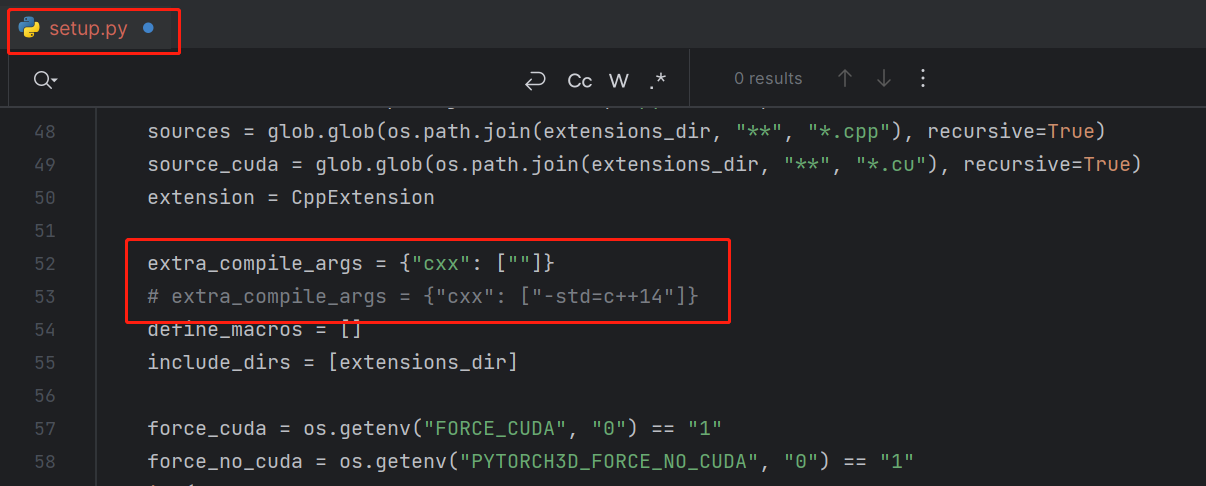
修改extra_compile_args = {“cxx”: [“-std=c++14”]}为extra_compile_args = {“cxx”: [“”]}:
安装 visual studio 2019,管理员身份打开 x64 native tools command prompt for vs 2019,依次输入:
activate gen6d
# 进入到pytorch3d目录下
cd external/pytorch3d
set distutils_use_sdk=1
set pytorch3d_no_ninja=1
# 开始安装
python setup.py install

安装完成:

查看pytorch3d版本:
import pytorch3d
print(pytorch3d.__version__)

数据集
官方数据集下载
包括:预训练模型(gen6d_pretrain.tar.gz)、genmop数据集(genmop.tar.gz)、处理后的linemod数据集(linemod.tar.gz)、co3d数据集(co3d.tar.gz)、google扫描物体数据(google_scanned_objects.tar.gz)和shapenet渲染图(shapenet.tar.gz)。
数据集和预训练网络权重在gen6d目录下的组织结构在具体的章节会详细讲解。
评估genmop/linemod数据集
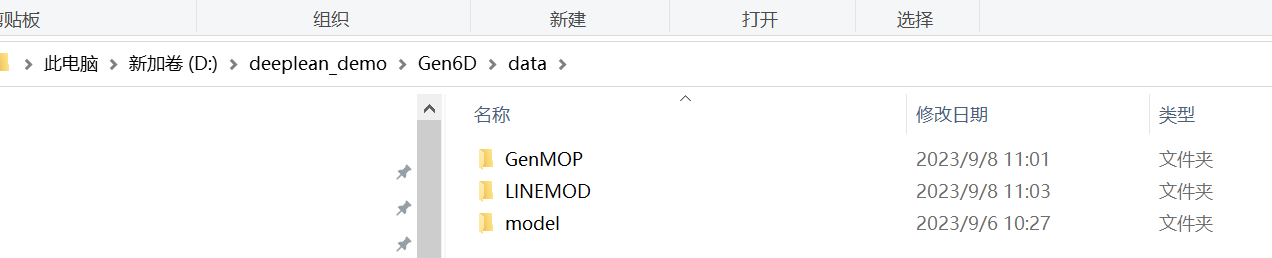
在gen6d目录下新建data文件夹,用于放置数据集和预训练权重。
将gen6d_pretrain.tar.gz、genmop.tar.gz和linemod.tar.gz)解压后按以下组织结构放置:
gen6d
|-- data
|-- model
|-- detector_pretrain
|-- model_best.pth
|-- selector_pretrain
|-- model_best.pth
|-- refiner_pretrain
|-- model_best.pth
|-- genmop
|-- chair
...
|-- linemod
|-- cat
...
测试genmop
# 测试genmop数据集中的tformer
python eval.py --cfg configs/gen6d_pretrain.yaml --object_name genmop/xxx
# eg: python eval.py --cfg configs/gen6d_pretrain.yaml --object_name genmop/cup
在data/vis_final/gen6d_pretrain/genmop/xxx中保存估计姿势的3d边界框的结果:

在data/vis_inter/gen6d_pretrain/genmop/xxx中保存有关检测、视点选择和姿势细化的中间结果:

测试linemod
# 测试linemod数据集中的benchvise
python eval.py --cfg configs/gen6d_pretrain.yaml --object_name linemod/xxx
# eg:python eval.py --cfg configs/gen6d_pretrain.yaml --object_name linemod/benchvise
在data/vis_final/gen6d_pretrain/linemod/xxx中保存估计姿势的3d边界框的结果:

在data/vis_inter/gen6d_pretrain/genmop/xxx中保存有关检测、视点选择和姿势细化的中间结果:

测试个人数据集
个人数据集的制作参考:和官方教程。
获得以下文件:

需要安装ffmpeg:参考教程
在data目录下新建custom文件夹,用于放置个人测试数据集,按照以下组织结构放置:
gen6d
|-- data
|-- model
|-- genmop
|-- linemod
|-- custom
|-- people
...
# 假如没有添加环境变量就需要ffmpeg.exe的完整路径
# --transpose 解决图片颠倒
python predict.py --cfg configs/gen6d_pretrain.yaml --database custom/xxx --video data/custom/video/xxx.mp4 --resolution 960 --transpose --output data/custom/xxx/test --ffmpeg ffmpeg.exe
# eg: python predict.py --cfg configs/gen6d_pretrain.yaml --database custom/people --video data/custom/video/people.mp4 --resolution 960 --output data/custom/people/test --ffmpeg ffmpeg.exe
在data/custom/xxx/test中保存估计姿势结果(视频转了gif):

训练网络
训练部分时长太久了,等出效果在更新。
总结
尽可能简单、详细的介绍gen6d的安装流程以及解决了安装过程中可能存在的问题。后续会根据自己学到的知识结合个人理解讲解gen6d的原理和代码。

发表评论