
前言
机器学习是一项快速发展的领域,其中k-最近邻算法(k-nearest neighbors,简称knn)是一个经典且常用的算法,可以用于分类和回归问题。在本文中,我们将介绍如何使用knn算法来实现鸢尾花种类的预测。
一、k最近邻(knn)介绍
二、鸢尾花数据集介绍
iris数据集是常用的分类实验数据集,由fisher, 1936收集整理。iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
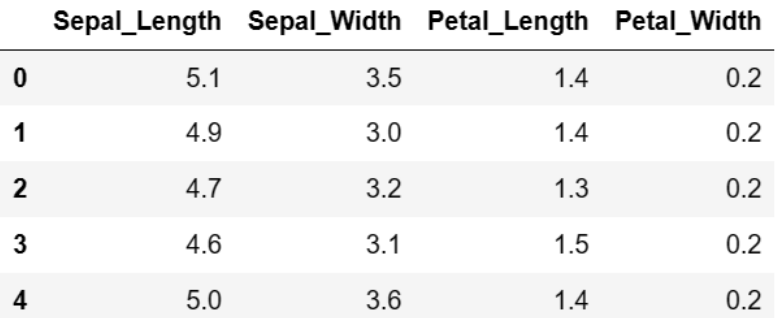
数据集介绍:

数据集样例:
三、鸢尾花数据集可视化
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
def iris_plot(data, x_col, y_col):
sns.lmplot(x=x_col, y=y_col, data=data, hue="target", fit_reg=false)
plt.title("鸢尾花数据显示")
plt.show()
# 设置字体为中文黑体
plt.rcparams['font.sans-serif'] = ['simhei']
# 加载数据集
iris = load_iris()
# 创建数据框
iris_df = pd.dataframe(data=iris.data, columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
iris_df["target"] = iris.target
# 绘制图表
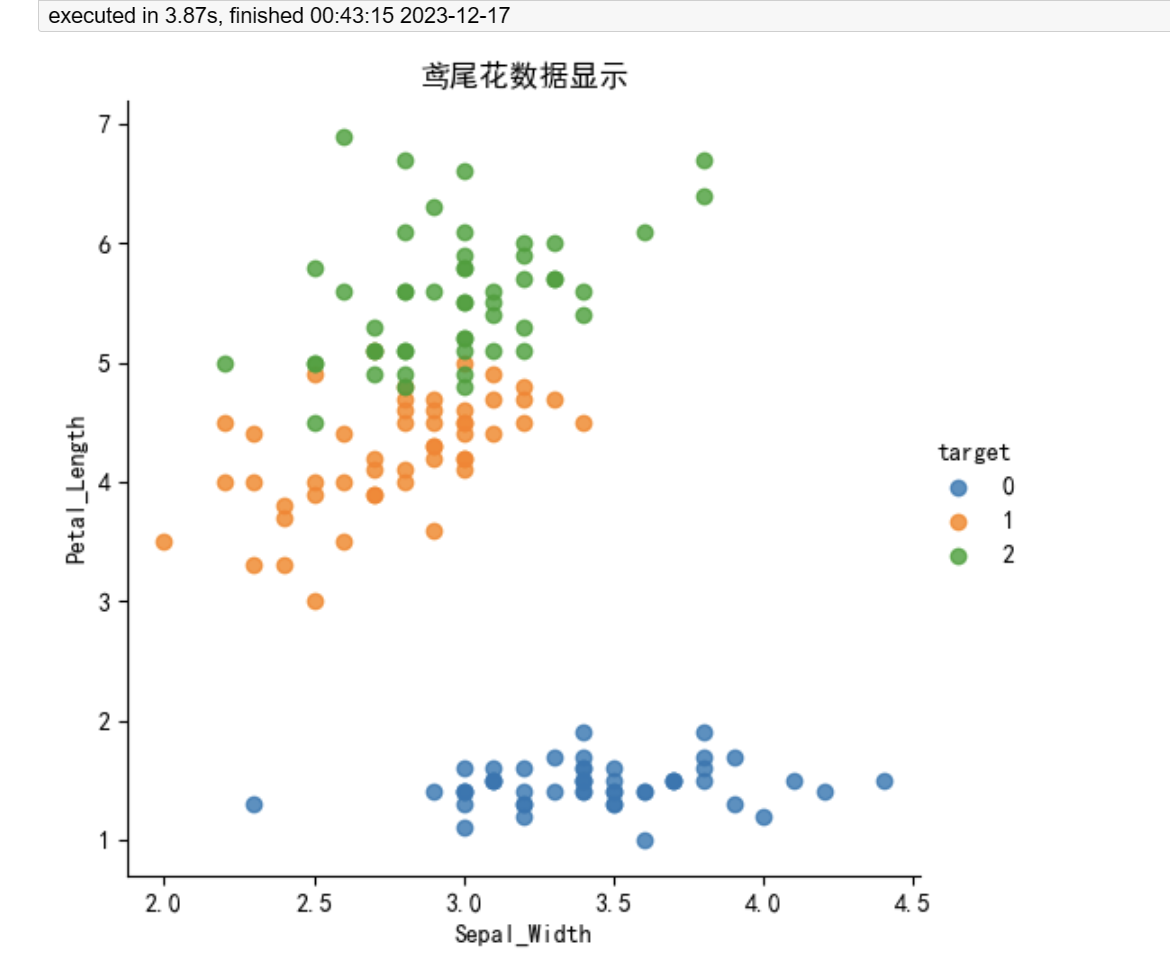
iris_plot(iris_df, 'sepal_width', 'petal_length')我们使用了 seaborn 库和 matplotlib 库进行绘制。在绘制之前,先加载了鸢尾花数据集,并将其转换为数据框格式。然后定义了一个 iris_plot 函数,用于绘制散点图。最后调用该函数,以花萼宽度和花瓣长度作为 x 轴和 y 轴绘制。也就是将数据集中的样本点按照花瓣长度和花萼宽度两个指标在二维坐标系上进行了展示,并且以不同颜色对应不同类型的鸢尾花。
四、鸢尾花数据分析
import pandas as pd
import joblib
import os
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, gridsearchcv
from sklearn.neighbors import kneighborsclassifier
from sklearn.preprocessing import standardscaler
iris = load_iris()
x = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
scaler = standardscaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
param_grid = {"n_neighbors": [1, 3, 5, 7]}
estimator = kneighborsclassifier()
grid_search = gridsearchcv(estimator, param_grid=param_grid, cv=5)
grid_search.fit(x_train, y_train)
estimator = grid_search.best_estimator_
if not os.path.exists("./model"):
os.makedirs("./model")
joblib.dump(estimator, "./model/model.pkl")
estimator = joblib.load("./model/model.pkl")
y_pred = estimator.predict(x_test)
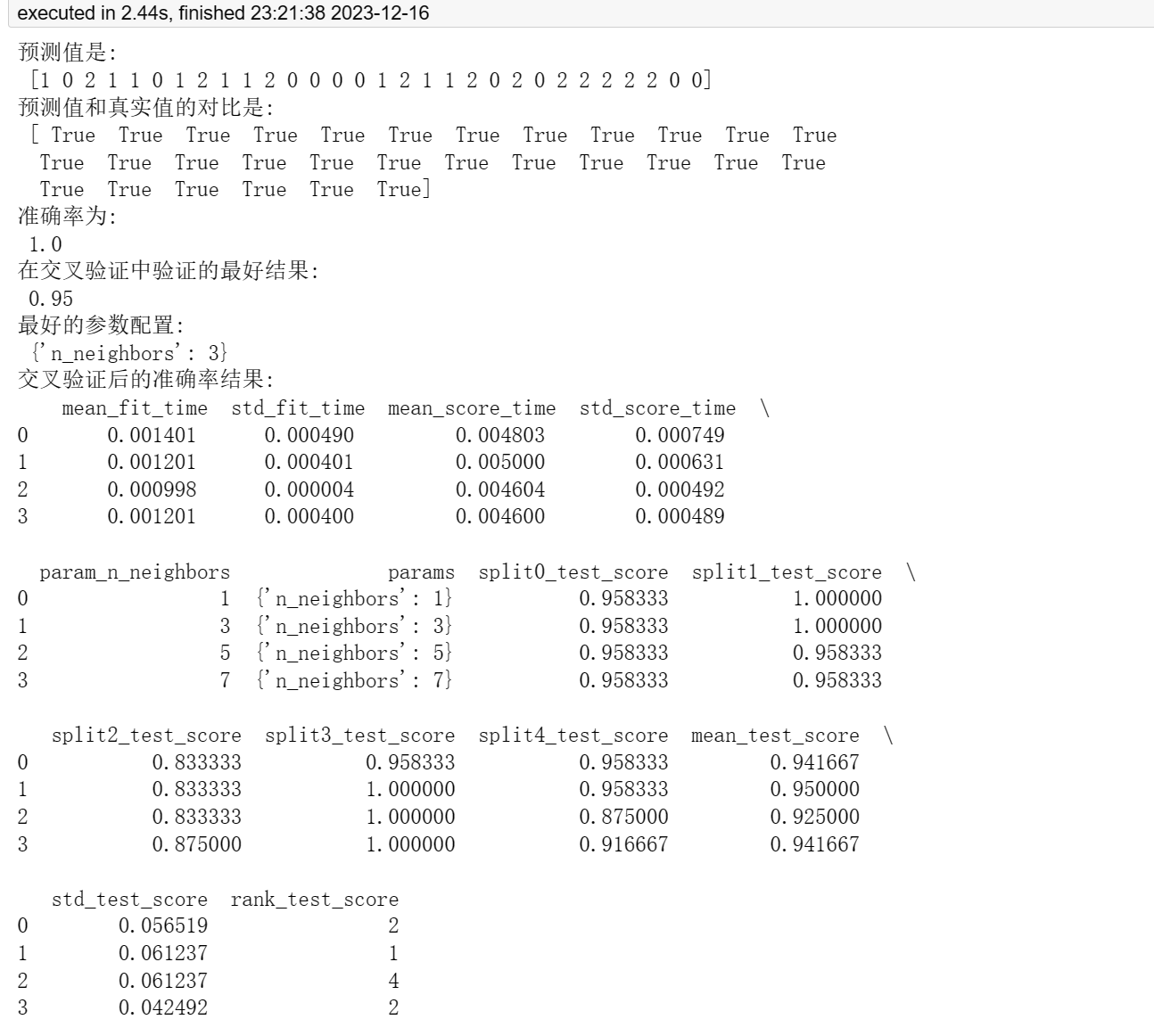
print("预测值是:\n", y_pred)
print("预测值和真实值的对比是:\n", y_pred == y_test)
score = estimator.score(x_test, y_test)
print("准确率为: \n", score)
print("在交叉验证中验证的最好结果:\n", grid_search.best_score_)
print("最好的参数配置:\n", grid_search.best_params_)
cv_results = pd.dataframe(grid_search.cv_results_)
print("交叉验证后的准确率结果:\n", cv_results)使用 k 最近邻算法对鸢尾花数据集进行分类。
我们主要使用了 pandas、joblib、os、sklearn 中的一些模块和函数。
我们首先加载鸢尾花数据集,然后将数据集分为训练集和测试集。接下来对训练集和测试集进行了特征标准化处理,使用了 standardscaler 类对数据进行标准化。
然后定义一个参数网格 param_grid,用于指定超参数 n_neighbors 的取值。创建一个 kneighborsclassifier 估计器,用于训练和预测。通过 gridsearchcv 类对模型进行了交叉验证和参数调优,并选出了最佳的模型估计器。
通过 joblib 模块将最佳的模型保存到./model/model.pkl文件中,并再次加载该模型。
利用这个模型对测试集进行预测,并计算准确率。同时打印了预测值、预测值和真实值的对比结果,交叉验证后的最佳得分和最佳参数配置。
使用 pd.dataframe 将交叉验证的结果转换为数据框格式,并打印交叉验证后的准确率结果。
我们可以通过这段代码可以了解到如何使用 k 最近邻算法对数据集进行分类,并使用网格搜索和交叉验证对模型进行参数调优。
总结
在本文中,我们学习了如何使用knn算法来预测鸢尾花的种类。我们首先进行了数据准备和预处理,然后实现了knn算法,并通过评估指标对模型进行了评估。knn算法是一种简单而有效的算法,在处理小型数据集和简单分类问题时可以发挥很好的作用。


发表评论