扩散模型 (diffusion model) 简要介绍与源码分析
前言
近期同事分享了 diffusion model, 这才发现生成模型的发展已经到了如此惊人的地步, openai 推出的 dall-e 2 可以根据文本描述生成极为逼真的图像, 质量之高直让人惊呼哇塞. 今早公众号给我推送了一篇关于 stability ai 公司的报道, 他们推出的 ai 文生图扩散模型 stable diffusion 已开源, 能够在消费级显卡上实现 dall-e 2 级别的图像生成, 效率提升了 30 倍.
于是找到他们的开源产品体验了一把, 在线体验地址在 https://huggingface.co/spaces/stabilityai/stable-diffusion (开源代码在 github 上: https://github.com/compvis/stable-diffusion), 在搜索框中输入 “a dog flying in the sky” (一只狗在天空飞翔), 生成效果如下:
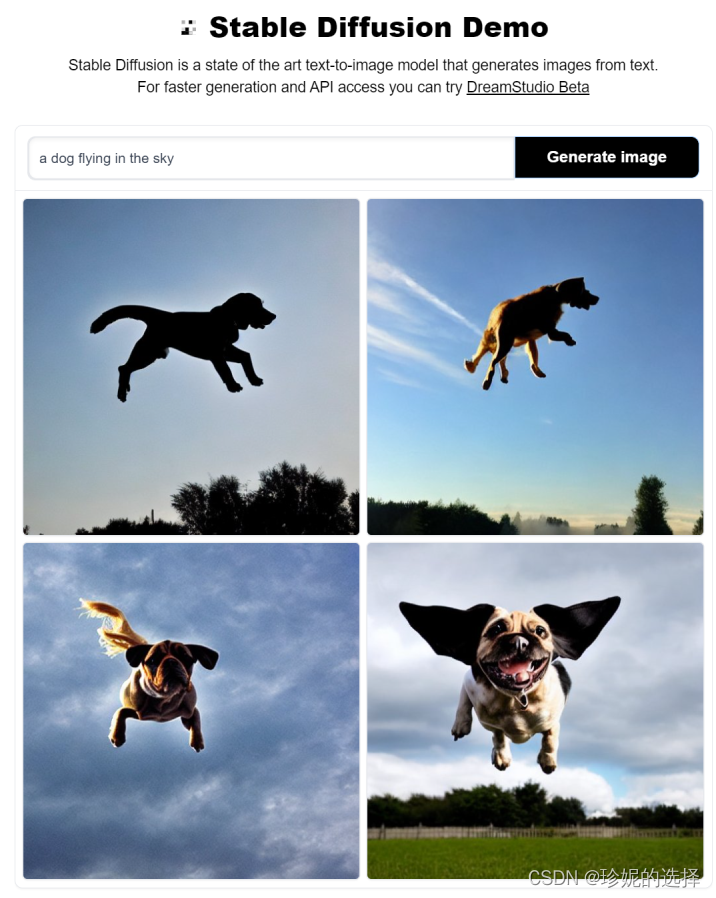
amazing! 当然, 不是每一张图片都符合预期, 但好在可以生成无数张图片, 其中总有效果好的. 在震惊之余, 不免对 diffusion model (扩散模型) 背后的原理感兴趣, 就想看看是怎么实现的.
当时同事分享时, ppt 上那一堆堆公式扑面而来, 把我给整懵圈了, 但还是得撑起下巴, 表现出似有所悟、深以为然的样子, 在讲到关键处不由暗暗点头以表示理解和赞许. 后面花了个周末专门学习了一下, 公式推导+代码分析, 感觉终于了解了基本概念, 于是记录下来形成此文, 不敢说自己完全懂了, 毕竟我不做这个方向, 但回过头去看 ppt 上的公式就不再发怵了.
广而告之
可以在微信中搜索 “珍妮的算法之路” 或者 “world4458” 关注我的微信公众号, 可以及时获取最新原创技术文章更新.
另外可以看看知乎专栏 poormemory-机器学习, 以后文章也会发在知乎专栏中.
总览
本文对 diffusion model 扩散模型的原理进行简要介绍, 然后对源码进行分析. 扩散模型的实现有多种形式, 本文关注的是 ddpm (denoising diffusion probabilistic models). 在介绍完基本原理后, 对作者释放的 tensorflow 源码进行分析, 加深对各种公式的理解.
参考文章
在理解扩散模型的路上, 受到下面这些文章的启发, 强烈推荐阅读:
- lilian 的博客, 内容非常非常详实, 干货十足, 而且每篇文章都极其用心, 向大佬学习: what are diffusion models?
- ewrfcas 的知乎, 公式推导补充了更多的细节: 由浅入深了解diffusion model
- lilian 的博客, 介绍变分自动编码器 vae: from autoencoder to beta-vae, diffusion model 需要从分布中随机采样样本, 该过程无法求导, 需要使用到 vae 中介绍的重参数技巧.
- denoising diffusion probabilistic models 论文,
- 其 tf 源码位于: https://github.com/hojonathanho/diffusion, 源码介绍以该版本为主
- pytorch 的开源实现: https://github.com/lucidrains/denoising-diffusion-pytorch, 核心逻辑和上面 tensorflow 版本是一致的, stable diffusion 参考的是 pytorch 版本的代码.
扩散模型介绍
基本原理
diffusion model (扩散模型) 是一类生成模型, 和 vae (variational autoencoder, 变分自动编码器), gan (generative adversarial network, 生成对抗网络) 等生成网络不同的是, 扩散模型在前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程.
具体来说, 前向阶段在原始图像 x 0 \mathbf{x}_0 x0 上逐步增加噪声, 每一步得到的图像 x t \mathbf{x}_t xt 只和上一步的结果 x t − 1 \mathbf{x}_{t - 1} xt−1 相关, 直至第 t t t 步的图像 x t \mathbf{x}_t xt 变为纯高斯噪声. 前向阶段图示如下:

而逆向阶段则是不断去除噪声的过程, 首先给定高斯噪声 x t \mathbf{x}_t xt, 通过逐步去噪, 直至最终将原图像 x 0 \mathbf{x}_0 x0 给恢复出来, 逆向阶段图示如下:

模型训练完成后, 只要给定高斯随机噪声, 就可以生成一张从未见过的图像. 下面分别介绍前向阶段和逆向阶段, 只列出重要公式,
前向阶段
由于前向过程中图像 x t \mathbf{x}_t xt 只和上一时刻的 x t − 1 \mathbf{x}_{t - 1} xt−1 有关, 该过程可以视为马尔科夫过程, 满足:
q ( x 1 : t ∣ x 0 ) = ∏ t = 1 t q ( x t ∣ x t − 1 ) q ( x t ∣ x t − 1 ) = n ( x t ; 1 − β t x t − 1 , β t i ) , \begin{align} q\left(x_{1: t} \mid x_0\right) &=\prod_{t=1}^t q\left(x_t \mid x_{t-1}\right) \\ q\left(x_t \mid x_{t-1}\right) &=\mathcal{n}\left(x_t ; \sqrt{1-\beta_t} x_{t-1}, \beta_t \mathbf{i}\right), \end{align} q(x1:t∣x0)q(xt∣xt−1)=t=1∏tq(xt∣xt−1)=n(xt;1−βtxt−1,βti),
其中 β t ∈ ( 0 , 1 ) \beta_t\in(0, 1) βt∈(0,1) 为高斯分布的方差超参, 并满足 β 1 < β 2 < … < β t \beta_1 < \beta_2 < \ldots < \beta_t β1<β2<…<βt. 另外公式 (2) 中为何均值 x t − 1 x_{t-1} xt−1 前乘上系数 1 − β t x t − 1 \sqrt{1-\beta_t} x_{t-1} 1−βtxt−1 的原因将在后面的推导介绍. 上述过程的一个美妙性质是我们可以在任意 time step 下通过 重参数技巧 采样得到 x t x_t xt.
重参数技巧 (reparameterization trick) 是为了解决随机采样样本这一过程无法求导的问题. 比如要从高斯分布 z ∼ n ( z ; μ , σ 2 i ) z \sim \mathcal{n}(z; \mu, \sigma^2\mathbf{i}) z∼n(z;μ,σ2i) 中采样样本 z z z, 可以通过引入随机变量 ϵ ∼ n ( 0 , i ) \epsilon\sim\mathcal{n}(0, \mathbf{i}) ϵ∼n(0,i), 使得 z = μ + σ ⊙ ϵ z = \mu + \sigma\odot\epsilon z=μ+σ⊙ϵ, 此时 z z z 依旧具有随机性, 且服从高斯分布 n ( μ , σ 2 i ) \mathcal{n}(\mu, \sigma^2\mathbf{i}) n(μ,σ2i), 同时 μ \mu μ 与 σ \sigma σ (通常由网络生成) 可导.
简要了解了重参数技巧后, 再回到上面通过公式 (2) 采样
x
t
x_t
xt 的方法, 即生成随机变量
ϵ
t
∼
n
(
0
,
i
)
\epsilon_t\sim\mathcal{n}(0, \mathbf{i})
ϵt∼n(0,i),
然后令
α
t
=
1
−
β
t
\alpha_t = 1 - \beta_t
αt=1−βt, 以及
α
t
‾
=
∏
i
=
1
t
α
t
\overline{\alpha_t} = \prod_{i=1}^{t}\alpha_t
αt=∏i=1tαt, 从而可以得到:
x t = 1 − β t x t − 1 + β t ϵ 1 where ϵ 1 , ϵ 2 , … ∼ n ( 0 , i ) , reparameter trick ; = a t x t − 1 + 1 − α t ϵ 1 = a t ( a t − 1 x t − 2 + 1 − α t − 1 ϵ 2 ) + 1 − α t ϵ 1 = a t a t − 1 x t − 2 + ( a t ( 1 − α t − 1 ) ϵ 2 + 1 − α t ϵ 1 ) = a t a t − 1 x t − 2 + 1 − α t α t − 1 ϵ ˉ 2 where ϵ ˉ 2 ∼ n ( 0 , i ) ; = … = α ˉ t x 0 + 1 − α ˉ t ϵ ˉ t . \begin{align} x_t &= \sqrt{1 - \beta_t} x_{t-1}+\beta_t \epsilon_1 \quad \text { where } \; \epsilon_1, \epsilon_2, \ldots \sim \mathcal{n}(0, \mathbf{i}), \; \text{reparameter trick} ; \nonumber \\ &=\sqrt{a_t} x_{t-1}+\sqrt{1-\alpha_t} \epsilon_1\nonumber \\ &=\sqrt{a_t}\left(\sqrt{a_{t-1}} x_{t-2}+\sqrt{1-\alpha_{t-1}} \epsilon_2\right)+\sqrt{1-\alpha_t} \epsilon_1 \nonumber \\ &=\sqrt{a_t a_{t-1}} x_{t-2}+\left(\sqrt{a_t\left(1-\alpha_{t-1}\right)} \epsilon_2+\sqrt{1-\alpha_t} \epsilon_1\right) \tag{3-1} \\ &=\sqrt{a_t a_{t-1}} x_{t-2}+\sqrt{1-\alpha_t \alpha_{t-1}} \bar{\epsilon}_2 \quad \text { where } \quad \bar{\epsilon}_2 \sim \mathcal{n}(0, \mathbf{i}) ; \tag{3-2} \\ &=\ldots \nonumber \\ &=\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \bar{\epsilon}_t. \end{align} xt=1−βtxt−1+βtϵ1 where ϵ1,ϵ2,…∼n(0,i),reparameter trick;=atxt−1+1−αtϵ1=at(at−1xt−2+1−αt−1ϵ2)+1−αtϵ1=atat−1xt−2+(at(1−αt−1)ϵ2+1−αtϵ1)=atat−1xt−2+1−αtαt−1ϵˉ2 where ϵˉ2∼n(0,i);=…=αˉtx0+1−αˉtϵˉt.(3-1)(3-2)
其中公式 (3-1) 到公式 (3-2) 的推导是由于独立高斯分布的可见性, 有 n ( 0 , σ 1 2 i ) + n ( 0 , σ 2 2 i ) ∼ n ( 0 , ( σ 1 2 + σ 2 2 ) i ) \mathcal{n}\left(0, \sigma_1^2\mathbf{i}\right) +\mathcal{n}\left(0,\sigma_2^2 \mathbf{i}\right)\sim\mathcal{n}\left(0, \left(\sigma_1^2 + \sigma_2^2\right)\mathbf{i}\right) n(0,σ12i)+n(0,σ22i)∼n(0,(σ12+σ22)i), 因此:
a t ( 1 − α t − 1 ) ϵ 2 ∼ n ( 0 , a t ( 1 − α t − 1 ) i ) 1 − α t ϵ 1 ∼ n ( 0 , ( 1 − α t ) i ) a t ( 1 − α t − 1 ) ϵ 2 + 1 − α t ϵ 1 ∼ n ( 0 , [ α t ( 1 − α t − 1 ) + ( 1 − α t ) ] i ) = n ( 0 , ( 1 − α t α t − 1 ) i ) . \begin{aligned} &\sqrt{a_t\left(1-\alpha_{t-1}\right)} \epsilon_2 \sim \mathcal{n}\left(0, a_t\left(1-\alpha_{t-1}\right) \mathbf{i}\right) \\ &\sqrt{1-\alpha_t} \epsilon_1 \sim \mathcal{n}\left(0,\left(1-\alpha_t\right) \mathbf{i}\right) \\ &\sqrt{a_t\left(1-\alpha_{t-1}\right)} \epsilon_2+\sqrt{1-\alpha_t} \epsilon_1 \sim \mathcal{n}\left(0,\left[\alpha_t\left(1-\alpha_{t-1}\right)+\left(1-\alpha_t\right)\right] \mathbf{i}\right) \\ &=\mathcal{n}\left(0,\left(1-\alpha_t \alpha_{t-1}\right) \mathbf{i}\right) . \end{aligned} at(1−αt−1)ϵ2∼n(0,at(1−αt−1)i)1−αtϵ1∼n(0,(1−αt)i)at(1−αt−1)ϵ2+1−αtϵ1∼n(0,[αt(1−αt−1)+(1−αt)]i)=n(0,(1−αtαt−1)i).
注意公式 (3-2) 中 ϵ ˉ 2 ∼ n ( 0 , i ) \bar{\epsilon}_2 \sim \mathcal{n}(0, \mathbf{i}) ϵˉ2∼n(0,i), 因此还需乘上 1 − α t α t − 1 \sqrt{1-\alpha_t \alpha_{t-1}} 1−αtαt−1. 从公式 (3) 可以看出
q ( x t ∣ x 0 ) = n ( x t ; a ˉ t x 0 , ( 1 − a ˉ t ) i ) \begin{align} q\left(x_t \mid x_0\right)=\mathcal{n}\left(x_t ; \sqrt{\bar{a}_t} x_0,\left(1-\bar{a}_t\right) \mathbf{i}\right) \end{align} q(xt∣x0)=n(xt;aˉtx0,(1−aˉt)i)
注意由于 β t ∈ ( 0 , 1 ) \beta_t\in(0, 1) βt∈(0,1) 且 β 1 < … < β t \beta_1 < \ldots < \beta_t β1<…<βt, 而 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt, 因此 α t ∈ ( 0 , 1 ) \alpha_t\in(0, 1) αt∈(0,1) 并且有 α 1 > … > α t \alpha_1 > \ldots>\alpha_t α1>…>αt, 另外由于 α ˉ t = ∏ i = 1 t α t \bar{\alpha}_t=\prod_{i=1}^t\alpha_t αˉt=∏i=1tαt, 因此当 t → ∞ t\rightarrow\infty t→∞ 时, α ˉ t → 0 \bar{\alpha}_t\rightarrow0 αˉt→0 以及 ( 1 − a ˉ t ) → 1 (1-\bar{a}_t)\rightarrow 1 (1−aˉt)→1, 此时 x t ∼ n ( 0 , i ) x_t\sim\mathcal{n}(0, \mathbf{i}) xt∼n(0,i). 从这里的推导来看, 在公式 (2) 中的均值 x t − 1 x_{t-1} xt−1 前乘上系数 1 − β t x t − 1 \sqrt{1-\beta_t} x_{t-1} 1−βtxt−1 会使得 x t x_{t} xt 最后收敛到标准高斯分布.
逆向阶段
前向阶段是加噪声的过程, 而逆向阶段则是将噪声去除, 如果能得到逆向过程的分布
q
(
x
t
−
1
∣
x
t
)
q\left(x_{t-1} \mid x_t\right)
q(xt−1∣xt), 那么通过输入高斯噪声
x
t
∼
n
(
0
,
i
)
x_t\sim\mathcal{n}(0, \mathbf{i})
xt∼n(0,i), 我们将生成一个真实的样本. 注意到当
β
t
\beta_t
βt 足够小时,
q
(
x
t
−
1
∣
x
t
)
q\left(x_{t-1} \mid x_t\right)
q(xt−1∣xt) 也是高斯分布, 具体的证明在 ewrfcas 的知乎文章: 由浅入深了解diffusion model 推荐的论文中: on the theory of stochastic processes, with particular reference to applications. 我大致看了一下, 哈哈, 没太看明白, 不过想到这个不是我关注的重点, 因此 pass. 由于我们无法直接推断
q
(
x
t
−
1
∣
x
t
)
q\left(x_{t-1} \mid x_t\right)
q(xt−1∣xt), 因此我们将使用深度学习模型
p
θ
p_{\theta}
pθ 去拟合分布
q
(
x
t
−
1
∣
x
t
)
q\left(x_{t-1} \mid x_t\right)
q(xt−1∣xt), 模型参数为
θ
\theta
θ:
p θ ( x 0 : t ) = p ( x t ) ∏ t = 1 t p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = n ( x t − 1 ; μ θ ( x t , t ) , σ θ ( x t , t ) ) \begin{align} p_\theta\left(x_{0: t}\right) &=p\left(x_t\right) \prod_{t=1}^t p_\theta\left(x_{t-1} \mid x_t\right) \\ p_\theta\left(x_{t-1} \mid x_t\right) &=\mathcal{n}\left(x_{t-1} ; \mu_\theta\left(x_t, t\right), \sigma_\theta\left(x_t, t\right)\right) \end{align} pθ(x0:t)pθ(xt−1∣xt)=p(xt)t=1∏tpθ(xt−1∣xt)=n(xt−1;μθ(xt,t),σθ(xt,t))
注意到, 虽然我们无法直接求得 q ( x t − 1 ∣ x t ) q\left(x_{t-1} \mid x_t\right) q(xt−1∣xt) (注意这里是 q q q 而不是模型 p θ p_{\theta} pθ), 但在知道 x 0 x_0 x0 的情况下, 可以通过贝叶斯公式得到 q ( x t − 1 ∣ x t , x 0 ) q\left(x_{t-1} \mid x_t, x_0\right) q(xt−1∣xt,x0) 为:
q ( x t − 1 ∣ x t , x 0 ) = n ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t i ) \begin{align} q\left(x_{t-1} \mid x_t, x_0\right) &= \mathcal{n}\left(x_{t-1} ; {\color{blue}{\tilde{\mu}}(x_t, x_0)}, {\color{red}{\tilde{\beta}_t} \mathbf{i}}\right) \end{align} q(xt−1∣xt,x0)=n(xt−1;μ~(xt,x0),β~ti)
推导过程如下:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 ⏟ x t − 1 方差 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 ⏟ x t − 1 均值 + c ( x t , x 0 ) ⏟ 与 x t − 1 无关 ) ) \begin{aligned} q(x_{t-1} \vert x_t, x_0) &= q(x_t \vert x_{t-1}, x_0) \frac{ q(x_{t-1} \vert x_0) }{ q(x_t \vert x_0) } \\ &\propto \exp \big(-\frac{1}{2} \big(\frac{(x_t - \sqrt{\alpha_t} x_{t-1})^2}{\beta_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1-\bar{\alpha}_t} \big) \big) \\ &= \exp \big(-\frac{1}{2} \big(\frac{x_t^2 - 2\sqrt{\alpha_t} x_t \color{blue}{x_{t-1}} \color{black}{+ \alpha_t} \color{red}{x_{t-1}^2} }{\beta_t} + \frac{ \color{red}{x_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} x_0} \color{blue}{x_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} x_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1-\bar{\alpha}_t} \big) \big) \\ &= \exp\big( -\frac{1}{2} \big( \underbrace{\color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} x_{t-1}^2}_{x_{t-1} \text { 方差 }} - \underbrace{\color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} x_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} x_0)} x_{t-1}}_{x_{t-1} \text { 均值 }} + \underbrace{{\color{black}{ c(x_t, x_0)}}}_{\text {与 } x_{t-1} \text { 无关 }} \big) \big) \end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21(xt−1 方差 (βtαt+1−αˉt−11)xt−12−xt−1 均值 (βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+与 xt−1 无关 c(xt,x0)))
上面推导过程中, 通过贝叶斯公式巧妙的将逆向过程转换为前向过程, 且最终得到的概率密度函数和高斯概率密度函数的指数部分 exp ( − ( x − μ ) 2 2 σ 2 ) = exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \exp{\left(-\frac{\left(x - \mu\right)^2}{2\sigma^2}\right)} = \exp{\left(-\frac{1}{2}\left(\frac{1}{\sigma^2}x^2 - \frac{2\mu}{\sigma^2}x + \frac{\mu^2}{\sigma^2}\right)\right)} exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2)) 能对应, 即有:
β ~ t = 1 / ( α t β t + 1 1 − α ˉ t − 1 ) = 1 / ( α t − α ˉ t + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t μ ~ t ( x t , x 0 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t x t + α ˉ t − 1 1 − α ˉ t − 1 x 0 ) 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \begin{align} \tilde{\beta}_t &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})}) = \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\ \tilde{\mu}_t (x_t, x_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} x_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \nonumber\\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} x_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t}\nonumber \\ &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} x_0\\ \end{align} β~tμ~t(xt,x0)=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
通过公式 (8) 和公式 (9), 我们能得到 q ( x t − 1 ∣ x t , x 0 ) q\left(x_{t-1} \mid x_t, x_0\right) q(xt−1∣xt,x0) (见公式 (7)) 的分布. 此外由于公式 (3) 揭示的 x t x_t xt 和 x 0 x_0 x0 之间的关系: x t = α ˉ t x 0 + 1 − α ˉ t ϵ ˉ t x_t =\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \bar{\epsilon}_t xt=αˉtx0+1−αˉtϵˉt, 可以得到
x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) \begin{align} x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon_t) \end{align} x0=αˉt1(xt−1−αˉtϵt)
代入公式 (9) 中得到:
μ ~ t = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \begin{align} \tilde{\mu}_t &= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon_t)\nonumber \\ &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_t \big)} \end{align} μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)
补充一下公式 (11) 的详细推导过程:
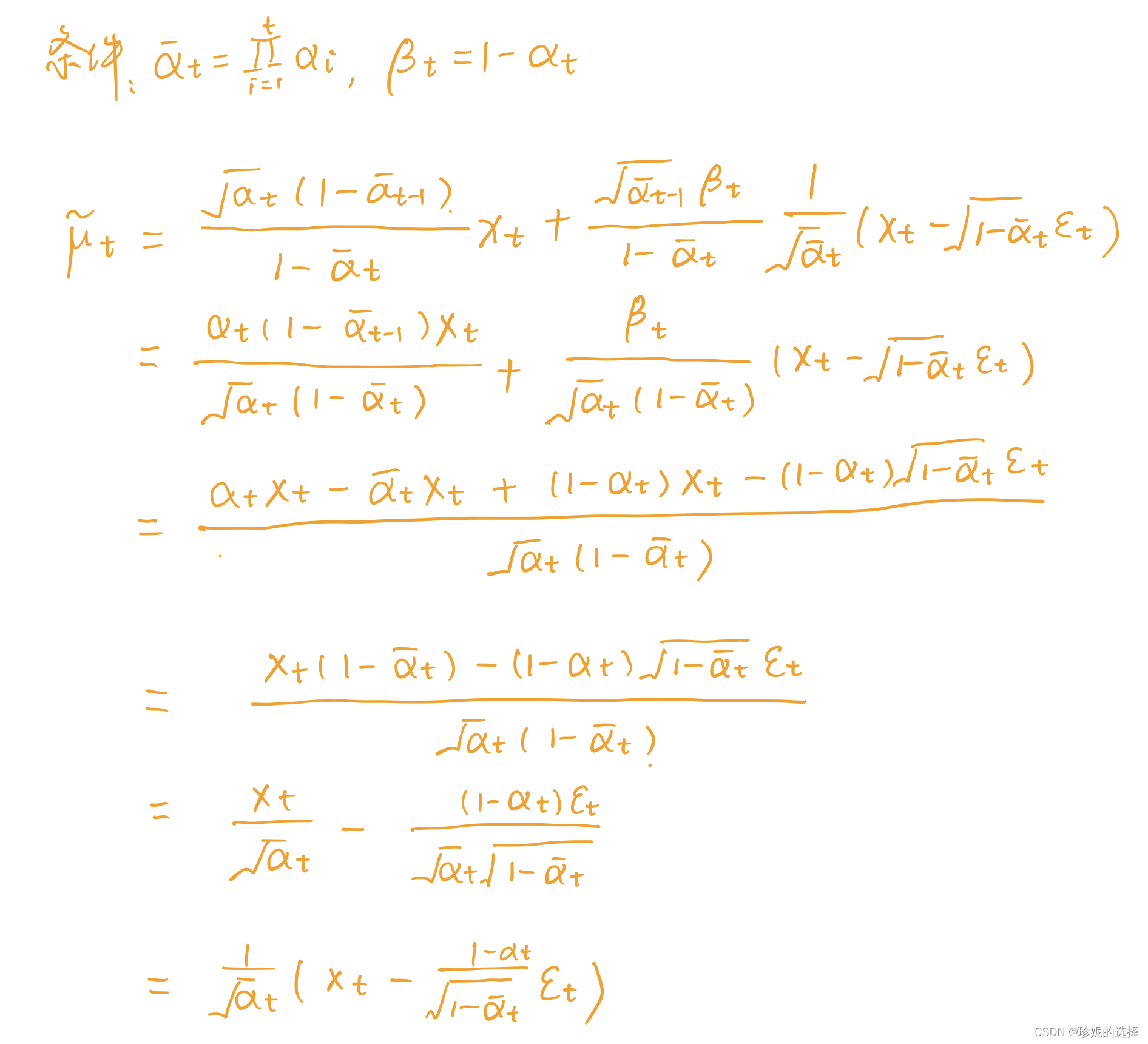
前面说到, 我们将使用深度学习模型 p θ p_{\theta} pθ 去拟合逆向过程的分布 q ( x t − 1 ∣ x t ) q\left(x_{t-1} \mid x_t\right) q(xt−1∣xt), 由公式 (6) 知 p θ ( x t − 1 ∣ x t ) = n ( x t − 1 ; μ θ ( x t , t ) , σ θ ( x t , t ) ) p_\theta\left(x_{t-1} \mid x_t\right) =\mathcal{n}\left(x_{t-1} ; \mu_\theta\left(x_t, t\right), \sigma_\theta\left(x_t, t\right)\right) pθ(xt−1∣xt)=n(xt−1;μθ(xt,t),σθ(xt,t)), 我们希望训练模型 μ θ ( x t , t ) \mu_\theta\left(x_t, t\right) μθ(xt,t) 以预估 μ ~ t = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \tilde{\mu}_t = \frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_t \big) μ~t=αt1(xt−1−αˉt1−αtϵt). 由于 x t x_t xt 在训练阶段会作为输入, 因此它是已知的, 我们可以转而让模型去预估噪声 ϵ t \epsilon_t ϵt, 即令:
μ θ ( x t , t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) thus x t − 1 = n ( x t − 1 ; 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) , σ θ ( x t , t ) ) \begin{align} \mu_\theta(x_t, t) &= \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(x_t, t) \big)} \\ \text{thus }x_{t-1} &= \mathcal{n}(x_{t-1}; \frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(x_t, t) \big), \boldsymbol{\sigma}_\theta(x_t, t)) \end{align} μθ(xt,t)thus xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))=n(xt−1;αt1(xt−1−αˉt1−αtϵθ(xt,t)),σθ(xt,t))
模型训练
前面谈到, 逆向阶段让模型去预估噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t, t) ϵθ(xt,t), 那么应该如何设计 loss 函数 ? 我们的目标是在真实数据分布下, 最大化模型预测分布的对数似然, 即优化在 x 0 ∼ q ( x 0 ) x_0\sim q(x_0) x0∼q(x0) 下的 p θ ( x 0 ) p_\theta(x_0) pθ(x0) 交叉熵:
l = e q ( x 0 ) [ − log p θ ( x 0 ) ] \begin{align} \mathcal{l} = \mathbb{e}_{q(x_0)}\left[-\log{p_\theta(x_0)}\right] \end{align} l=eq(x0)[−logpθ(x0)]
和 变分自动编码器 vae 类似, 使用 variational lower bound 来优化: − log p θ ( x 0 ) -\log{p_\theta(x_0)} −logpθ(x0) :
− log p θ ( x 0 ) ≤ − log p θ ( x 0 ) + d k l ( q ( x 1 : t ∣ x 0 ) ∥ p θ ( x 1 : t ∣ x 0 ) ) ; 注: 注意kl散度非负 = − log p θ ( x 0 ) + e q ( x 1 : t ∣ x 0 ) [ log q ( x 1 : t ∣ x 0 ) p θ ( x 0 : t ) / p θ ( x 0 ) ] ; where p θ ( x 1 : t ∣ x 0 ) = p θ ( x 0 : t ) p θ ( x 0 ) = − log p θ ( x 0 ) + e q ( x 1 : t ∣ x 0 ) [ log q ( x 1 : t ∣ x 0 ) p θ ( x 0 : t ) + log p θ ( x 0 ) ⏟ 与q无关 ] = e q ( x 1 : t ∣ x 0 ) [ log q ( x 1 : t ∣ x 0 ) p θ ( x 0 : t ) ] . \begin{align} -\log p_\theta\left(x_0\right) &\leq-\log p_\theta\left(x_0\right)+d_{k l}\left(q\left(x_{1: t} \mid x_0\right) \| p_\theta\left(x_{1: t} \mid x_0\right)\right); \quad \text{注: 注意kl散度非负}\nonumber\\ &=-\log p_\theta\left(x_0\right)+\mathbb{e}_{q\left(x_{1: t} \mid x_0\right)}\left[\log \frac{q\left(x_{1: t} \mid x_0\right)}{p_\theta\left(x_{0: t}\right) / p_\theta\left(x_0\right)}\right] ; \; \text { where } \; p_\theta\left(x_{1: t} \mid x_0\right)=\frac{p_\theta\left(x_{0: t}\right)}{p_\theta\left(x_0\right)}\nonumber\\ &=-\log p_\theta\left(x_0\right)+\mathbb{e}_{q\left(x_{1: t} \mid x_0\right)}[\log \frac{q\left(x_{1: t} \mid x_0\right)}{p_\theta\left(x_{0: t}\right)}+\underbrace{\log p_\theta\left(x_0\right)}_{\text {与q无关 }}]\nonumber\\ &=\mathbb{e}_{q\left(x_{1: t} \mid x_0\right)}\left[\log \frac{q\left(x_{1: t} \mid x_0\right)}{p_\theta\left(x_{0: t}\right)}\right] . \end{align} −logpθ(x0)≤−logpθ(x0)+dkl(q(x1:t∣x0)∥pθ(x1:t∣x0));注: 注意kl散度非负=−logpθ(x0)+eq(x1:t∣x0)[logpθ(x0:t)/pθ(x0)q(x1:t∣x0)]; where pθ(x1:t∣x0)=pθ(x0)pθ(x0:t)=−logpθ(x0)+eq(x1:t∣x0)[logpθ(x0:t)q(x1:t∣x0)+与q无关 logpθ(x0)]=eq(x1:t∣x0)[logpθ(x0:t)q(x1:t∣x0)].
对公式 (15) 左右两边取期望 e q ( x 0 ) \mathbb{e}_{q(x_0)} eq(x0), 利用到重积分中的 fubini 定理 可得:
l v l b = e q ( x 0 ) ( e q ( x 1 : t ∣ x 0 ) [ log q ( x 1 : t ∣ x 0 ) p θ ( x 0 : t ) ] ) = e q ( x 0 : t ) [ log q ( x 1 : t ∣ x 0 ) p θ ( x 0 : t ) ] ⏟ fubini定理 ≥ e q ( x 0 ) [ − log p θ ( x 0 ) ] \mathcal{l}_{v l b}=\underbrace{\mathbb{e}_{q\left(x_0\right)}\left(\mathbb{e}_{q\left(x_{1: t} \mid x_0\right)}\left[\log \frac{q\left(x_{1: t} \mid x_0\right)}{p_\theta\left(x_{0: t}\right)}\right]\right)=\mathbb{e}_{q\left(x_{0: t}\right)}\left[\log \frac{q\left(x_{1: t} \mid x_0\right)}{p_\theta\left(x_{0: t}\right)}\right]}_{\text {fubini定理 }} \geq \mathbb{e}_{q\left(x_0\right)}\left[-\log p_\theta\left(x_0\right)\right] lvlb=fubini定理 eq(x0)(eq(x1:t∣x0)[logpθ(x0:t)q(x1:t∣x0)])=eq(x0:t)[logpθ(x0:t)q(x1:t∣x0)]≥eq(x0)[−logpθ(x0)]
因此最小化 l v l b \mathcal{l}_{v l b} lvlb 就可以优化公式 (14) 中的目标函数. 之后对 l v l b \mathcal{l}_{v l b} lvlb 做进一步的推导, 这部分的详细推导见上面的参考文章, 最终的结论是:
l v l b = l t + l t − 1 + … + l 0 l t = d k l ( q ( x t ∣ x 0 ) ∣ ∣ p θ ( x t ) ) l t = d k l ( q ( x t ∣ x t + 1 , x 0 ) ∣ ∣ p θ ( x t ∣ x t + 1 ) ) ; 1 ≤ t ≤ t − 1 l 0 = − log p θ ( x 0 ∣ x 1 ) \begin{align} \mathcal{l}_{v l b} &= l_t + l_{t - 1} + \ldots + l_0 \\ l_t &= d_{kl}\left(q(x_t|x_0)||p_{\theta}(x_t)\right) \\ l_t &= d_{kl}\left(q(x_t|x_{t + 1}, x_0)||p_{\theta}(x_t|x_{t+1})\right); \quad 1 \leq t \leq t - 1 \\ l_0 &= -\log{p_\theta\left(x_0|x_1\right)} \end{align} lvlbltltl0=lt+lt−1+…+l0=dkl(q(xt∣x0)∣∣pθ(xt))=dkl(q(xt∣xt+1,x0)∣∣pθ(xt∣xt+1));1≤t≤t−1=−logpθ(x0∣x1)
最终是优化两个高斯分布 q ( x t ∣ x t − 1 , x 0 ) = n ( x t − 1 ; μ ~ ( x t , x 0 ) , β ~ t i ) q(x_t|x_{t - 1}, x_0) = \mathcal{n}\left(x_{t-1} ; {\color{blue}{\tilde{\mu}}(x_t, x_0)}, {\color{red}{\tilde{\beta}_t} \mathbf{i}}\right) q(xt∣xt−1,x0)=n(xt−1;μ~(xt,x0),β~ti) (详见公式 (7)) 与 p θ ( x t ∣ x t + 1 ) = n ( x t − 1 ; μ θ ( x t , t ) , σ θ ) p_{\theta}(x_t|x_{t+1}) = \mathcal{n}\left(x_{t-1} ; \mu_\theta\left(x_t, t\right), \sigma_\theta\right) pθ(xt∣xt+1)=n(xt−1;μθ(xt,t),σθ) (详见公式(6), 此为模型预估的分布)之间的 kl 散度. 由于多元高斯分布的 kl 散度存在闭式解, 详见: multivariate_normal_distributions, 从而可以得到:
l t = e x 0 , ϵ [ 1 2 ∥ σ θ ( x t , t ) ∥ 2 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 ] = e x 0 , ϵ [ 1 2 ∥ σ θ ∥ 2 2 ∥ 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) − 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 ] = e x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( x t , t ) ∥ 2 ] ; 其中 ϵ t 为高斯噪声 , ϵ θ 为模型学习的噪声 = e x 0 , ϵ [ ( 1 − α t ) 2 2 α t ( 1 − α ˉ t ) ∥ σ θ ∥ 2 2 ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{align} l_t &= \mathbb{e}_{x_0, \epsilon} \big[\frac{1}{2 \| \boldsymbol{\sigma}_\theta(x_t, t) \|^2_2} \| \color{blue}{\tilde{\mu}_t(x_t, x_0)} - \color{green}{\mu_\theta(x_t, t)} \|^2 \big] \\ &= \mathbb{e}_{x_0, \epsilon} \big[\frac{1}{2 \|\boldsymbol{\sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_t \big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(x_t, t) \big)} \|^2 \big] \\ &= \mathbb{e}_{x_0, \epsilon} \big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\sigma}_\theta \|^2_2} \|\epsilon_t - \epsilon_\theta(x_t, t)\|^2 \big]; \quad \text{其中} \epsilon_t \text{为高斯噪声}, \epsilon_{\theta} \text{为模型学习的噪声} \\ &= \mathbb{e}_{x_0, \epsilon} \big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\sigma}_\theta \|^2_2} \|\epsilon_t - \epsilon_\theta(\sqrt{\bar{\alpha}_t}x_0 + \sqrt{1 - \bar{\alpha}_t}\epsilon_t, t)\|^2 \big] \end{align} lt=ex0,ϵ[2∥σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=ex0,ϵ[2∥σθ∥221∥αt1(xt−1−αˉt1−αtϵt)−αt1(xt−1−αˉt1−αtϵθ(xt,t))∥2]=ex0,ϵ[2αt(1−αˉt)∥σθ∥22(1−αt)2∥ϵt−ϵθ(xt,t)∥2];其中ϵt为高斯噪声,ϵθ为模型学习的噪声=ex0,ϵ[2αt(1−αˉt)∥σθ∥22(1−αt)2∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥2]
ddpm 将 loss 简化为如下形式:
l t simple = e x 0 , ϵ t [ ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 ] \begin{align} l_t^{\text {simple }}=\mathbb{e}_{x_0, \epsilon_t}\left[\left\|\epsilon_t-\epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t, t\right)\right\|^2\right] \end{align} ltsimple =ex0,ϵt[ ϵt−ϵθ(αˉtx0+1−αˉtϵt,t) 2]
因此 diffusion 模型的目标函数即是学习高斯噪声 ϵ t \epsilon_t ϵt 和 ϵ θ \epsilon_{\theta} ϵθ (来自模型输出) 之间的 mse loss.
最终算法
最终 ddpm 的算法流程如下:

训练阶段重复如下步骤:
- 从数据集中采样 x 0 x_0 x0
- 随机选取 time step t t t
- 生成高斯噪声 ϵ t ∈ n ( 0 , i ) \epsilon_t\in\mathcal{n}(0, \mathbf{i}) ϵt∈n(0,i)
- 调用模型预估 ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) \epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t, t\right) ϵθ(αˉtx0+1−αˉtϵt,t)
- 计算噪声之间的 mse loss: ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 \left\|\epsilon_t-\epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t, t\right)\right\|^2 ϵt−ϵθ(αˉtx0+1−αˉtϵt,t) 2, 并利用反向传播算法训练模型.
逆向阶段采用如下步骤进行采样:
- 从高斯分布采样 x t x_t xt
- 按照
t
,
…
,
1
t, \ldots, 1
t,…,1 的顺序进行迭代:
- 如果 t = 1 t = 1 t=1, 令 z = 0 \mathbf{z} = {0} z=0; 如果 t > 1 t > 1 t>1, 从高斯分布中采样 z ∼ n ( 0 , i ) \mathbf{z}\sim\mathcal{n}(0, \mathbf{i}) z∼n(0,i)
- 利用公式 (12) 学习出均值 μ θ ( x t , t ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) \mu_\theta(x_t, t) = \color{cyan}{\frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(x_t, t) \big)} μθ(xt,t)=αt1(xt−1−αˉt1−αtϵθ(xt,t)), 并利用公式 (8) 计算均方差 σ t = β ~ t = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \sigma_t = \sqrt{\tilde{\beta}_t} = \sqrt{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} σt=β~t=1−αˉt1−αˉt−1⋅βt
- 通过重参数技巧采样 x t − 1 = μ θ ( x t , t ) + σ t z x_{t - 1} = \mu_\theta(x_t, t) + \sigma_t\mathbf{z} xt−1=μθ(xt,t)+σtz
- 经过以上过程的迭代, 最终恢复 x 0 x_0 x0.
源码分析
ddpm 文章以及代码的相关信息如下:
- denoising diffusion probabilistic models 论文,
- 其 tf 源码位于: https://github.com/hojonathanho/diffusion, 源码介绍以该版本为主
- pytorch 的开源实现: https://github.com/lucidrains/denoising-diffusion-pytorch, 核心逻辑和上面 tensorflow 版本是一致的, stable diffusion 参考的是 pytorch 版本的代码.
本文以分析 tensorflow 源码为主, pytorch 版本的代码和 tensorflow 版本的实现逻辑大体不差的, 变量名字啥的都类似, 阅读起来不会有啥门槛. tensorlow 源码对 diffusion 模型的实现位于 diffusion_utils_2.py, 模型本身的分析以该文件为主.
训练阶段
以 cifar 数据集为例.
在 run_cifar.py 中进行前向传播计算 loss:

- 第 6 行随机选出 t ∼ uniform ( { 1 , … , t } ) t\sim\text{uniform}(\{1, \ldots, t\}) t∼uniform({1,…,t})
- 第 7 行
training_losses定义在 gaussiandiffusion2 中, 计算噪声间的 mse loss.
进入 gaussiandiffusion2 中, 看到初始化函数中定义了诸多变量, 我在注释中使用公式的方式进行了说明:

下面进入到 training_losses 函数中:

- 第 19 行:
self.model_mean_type默认是eps, 模型学习的是噪声, 因此target是第 6 行定义的noise, 即 ϵ t \epsilon_t ϵt - 第 9 行: 调用
self.q_sample计算 x t x_t xt, 即公式 (3) x t = α ˉ t x 0 + 1 − α ˉ t ϵ t x_t =\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t xt=αˉtx0+1−αˉtϵt - 第 21 行:
denoise_fn是定义在 unet.py 中的unet模型, 只需知道它的输入和输出大小相同; 结合第 9 行得到的 x t x_t xt, 得到模型预估的噪声: ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) \epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t, t\right) ϵθ(αˉtx0+1−αˉtϵt,t) - 第 23 行: 计算两个噪声之间的 mse: ∥ ϵ t − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ t , t ) ∥ 2 \left\|\epsilon_t-\epsilon_\theta\left(\sqrt{\bar{\alpha}_t} x_0+\sqrt{1-\bar{\alpha}_t} \epsilon_t, t\right)\right\|^2 ϵt−ϵθ(αˉtx0+1−αˉtϵt,t) 2, 并利用反向传播算法训练模型
上面第 9 行定义的 self.q_sample 详情如下:

- 第 13 行的
q_sample已经介绍过, 不多说. - 第 2 行的
_extract在代码中经常被使用到, 看到它只需知道它是用来提取系数的即可. 引入输入是一个 batch, 里面的每个样本都会随机采样一个 time step t t t, 因此需要使用tf.gather来将 α t ˉ \bar{\alpha_t} αtˉ 之类选出来, 然后将系数 reshape 为[b, 1, 1, ....]的形式, 目的是为了利用 broadcasting 机制和 x t x_t xt 这个 tensor 相乘.
前向的训练阶段代码实现非常简单, 下面看逆向阶段
逆向阶段
逆向阶段代码定义在 gaussiandiffusion2 中:
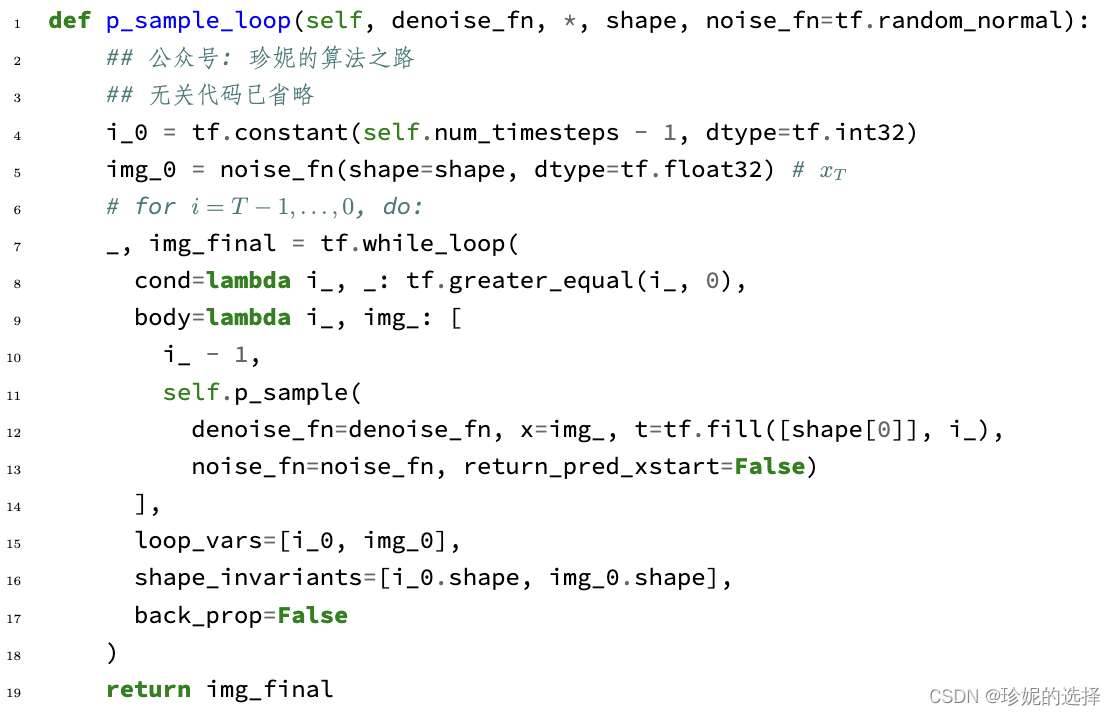
- 第 5 行生成高斯噪声 x t x_t xt, 然后对其不断去噪直至恢复原始图像
- 第 11 行的
self.p_sample就是公式 (6) p θ ( x t − 1 ∣ x t ) = n ( x t − 1 ; μ θ ( x t , t ) , σ θ ( x t , t ) ) p_\theta\left(x_{t-1} \mid x_t\right) =\mathcal{n}\left(x_{t-1} ; \mu_\theta\left(x_t, t\right), \sigma_\theta\left(x_t, t\right)\right) pθ(xt−1∣xt)=n(xt−1;μθ(xt,t),σθ(xt,t)) 的过程, 使用模型来预估 μ θ ( x t , t ) \mu_\theta\left(x_t, t\right) μθ(xt,t) 以及 σ θ ( x t , t ) \sigma_\theta\left(x_t, t\right) σθ(xt,t) - 第 12 行的
denoise_fn在前面说过, 是定义在 unet.py 中的unet模型;img_表示 x t x_t xt. - 第 13 行的
noise_fn则默认是tf.random_normal, 用于生成高斯噪声.
进入 p_sample 函数:

- 第 7 行调用
self.p_mean_variance生成 μ θ ( x t , t ) \mu_\theta\left(x_t, t\right) μθ(xt,t) 以及 log ( σ θ ( x t , t ) ) \log\left(\sigma_\theta\left(x_t, t\right)\right) log(σθ(xt,t)), 其中 σ θ ( x t , t ) \sigma_\theta\left(x_t, t\right) σθ(xt,t) 通过计算 β ~ t \tilde{\beta}_t β~t 得到. - 第 11 行从高斯分布中采样 z \mathbf{z} z
- 第 18 行通过重参数技巧采样 x t − 1 = μ θ ( x t , t ) + σ t z x_{t - 1} = \mu_\theta(x_t, t) + \sigma_t\mathbf{z} xt−1=μθ(xt,t)+σtz, 其中 σ t = β ~ t \sigma_t = \sqrt{\tilde{\beta}_t} σt=β~t
进入 self.p_mean_variance 函数:

- 第 6 行调用模型
denoise_fn, 通过输入 x t x_t xt, 输出得到噪声 ϵ t \epsilon_t ϵt - 第 19 行
self.model_var_type默认为fixedlarge, 但我当时看fixedsmall比较爽, 因此model_variance和model_log_variance分别为 β ~ t = 1 − α ˉ t − 1 1 − α ˉ t ⋅ β t \tilde{\beta}_t = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t β~t=1−αˉt1−αˉt−1⋅βt (见公式 8), 以及 log β ~ t \log\tilde{\beta}_t logβ~t - 第 29 行调用
self._predict_xstart_from_eps函数, 利用公式 (10) 得到 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon_t) x0=αˉt1(xt−1−αˉtϵt) - 第 30 行调用
self.q_posterior_mean_variance通过公式 (9) 得到 μ θ ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \mu_\theta(x_t, x_0) = \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} x_0 μθ(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
self._predict_xstart_from_eps 函数相亲如下:

- 该函数计算 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ t ) x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon_t) x0=αˉt1(xt−1−αˉtϵt)
self.q_posterior_mean_variance 函数详情如下:

- 相关说明见注释, 另外发现对于 μ θ ( x t , x 0 ) \mu_\theta(x_t, x_0) μθ(xt,x0) 的计算使用的是公式 (9) μ θ ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 \mu_\theta(x_t, x_0) = \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} x_0 μθ(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0 而不是进一步推导后的公式 (11) μ θ ( x t , x 0 ) = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ t ) \mu_\theta(x_t, x_0) = \frac{1}{\sqrt{\alpha_t}} \big( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_t \big) μθ(xt,x0)=αt1(xt−1−αˉt1−αtϵt).
总结
写文章真的挺累的, 好处是, 我发现写之前我以为理解了, 但写的过程中又发现有些地方理解的不对. 写完后才终于把逻辑理顺.



发表评论