【nlp基础知识-bert向量化】bert模型输出pooler_output和last_hidden_state详解和用法
本次修炼方法请往下查看

下滑查看解决方法
🎯 1. 基本介绍
bert(bidirectional encoder representations from transformers)是一种预训练语言表示模型,由google在2018年提出。它通过使用transformer架构的编码器部分,能够捕捉到文本的双向上下文信息。bert模型在自然语言处理(nlp)领域取得了革命性的进展,为各种下游任务提供了强大的基础。
1.1 bert的关键特点
双向上下文理解:与传统的单向语言模型不同,bert能够同时考虑左右两边的上下文。
预训练任务:bert通过masked language model(mlm)和next sentence prediction(nsp)任务进行预训练。
1.2 bert模型的输出
pooler_output:这是通过将最后一层的隐藏状态的第一个token(通常是[cls] token)通过一个线性层和激活函数得到的输出,常用于分类任务。
last_hidden_state:这是模型所有层的最后一个隐藏状态的输出,包含了整个序列的上下文信息,适用于序列级别的任务。
💡 2. bert向量化使用方法
2.1 bert模型输出介绍
加载bert模型输出解释如下所示,相关的代码实践如下所示:
import tensorflow as tf
from transformers import berttokenizer, tfbertmodel, bertmodel
# 加载berttokenizer和bertmodel
tokenizer = berttokenizer.from_pretrained('bert-base-chinese')
bert_model = tfbertmodel.from_pretrained('bert-base-chinese')
# 定义输入文本
text = '这是一个测试句子'
# 对输入文本进行分词和填充
encoded_input = tokenizer(text, padding=true, uncation=true, return_tensors='tf')
# 获取bert模型的embedding结果
output = bert_model(encoded_input, output_hidden_states=true, output_attentions=true)
# 输出结果
print(output)
# print(output.get_shape())
其中每个输出部分的解释如下所示:
2.2 输出的具体用法
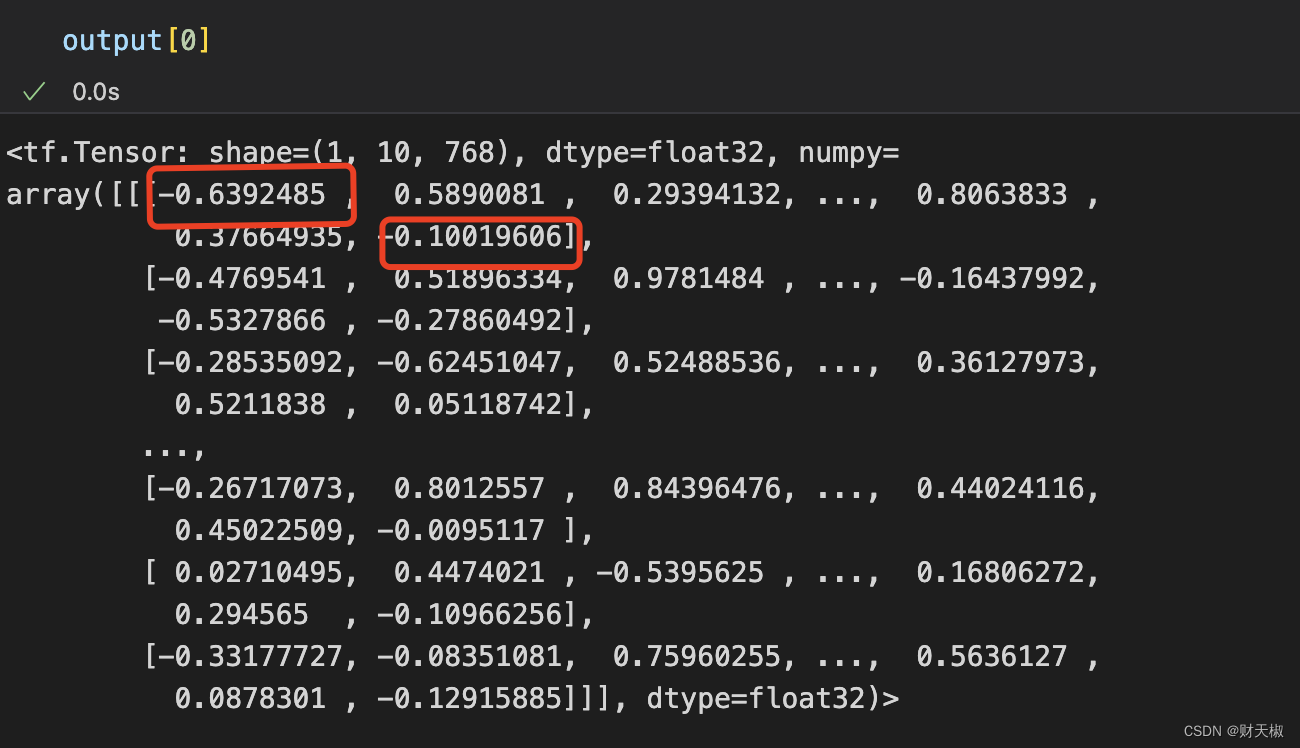
last_hidden_state的输出如下所示,其中第一个红色圈就是cls的embedding,最后一个就是seq的embedding,
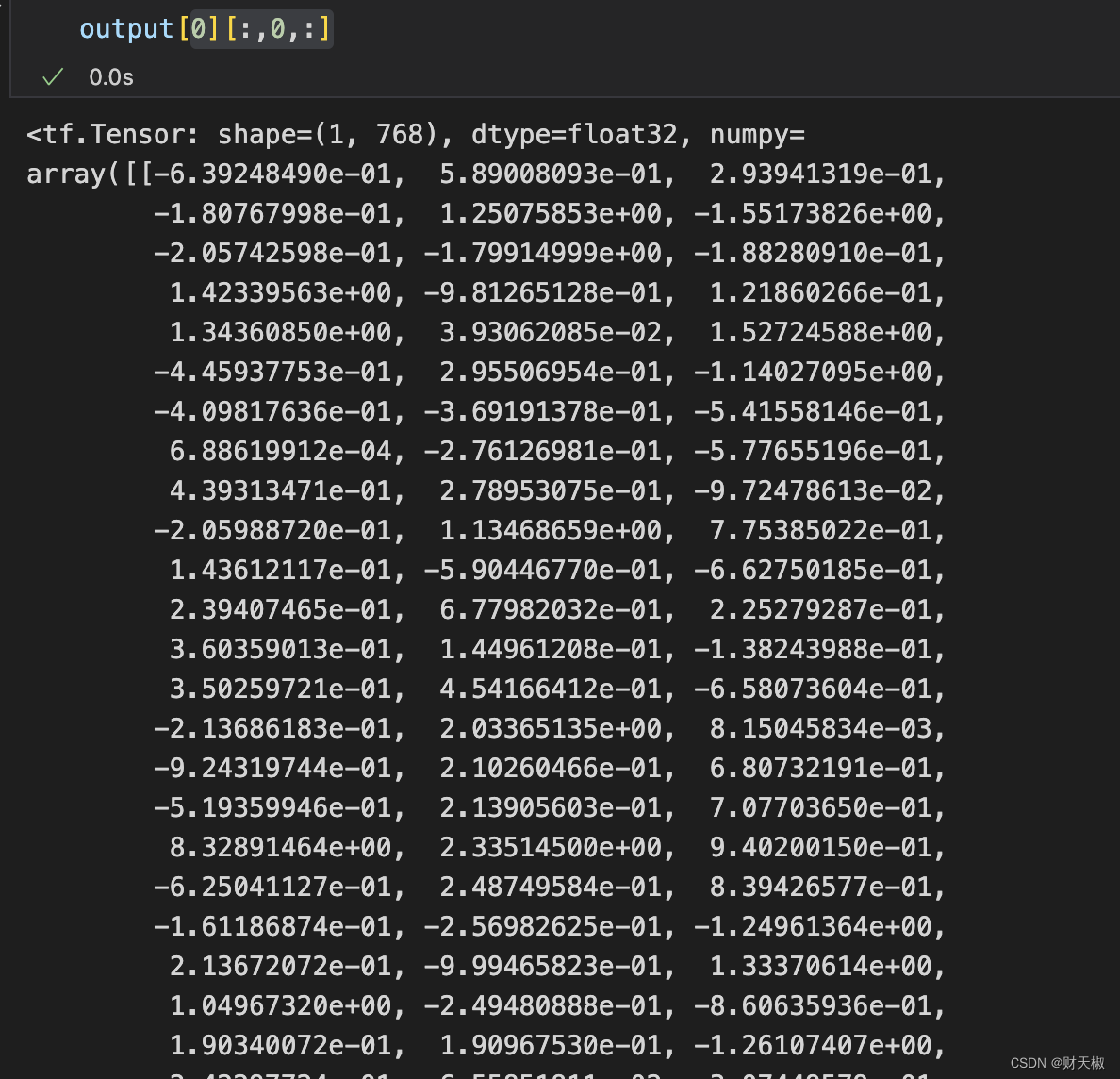
- 取用cls的embedding可以用:output[0][:,0,:]
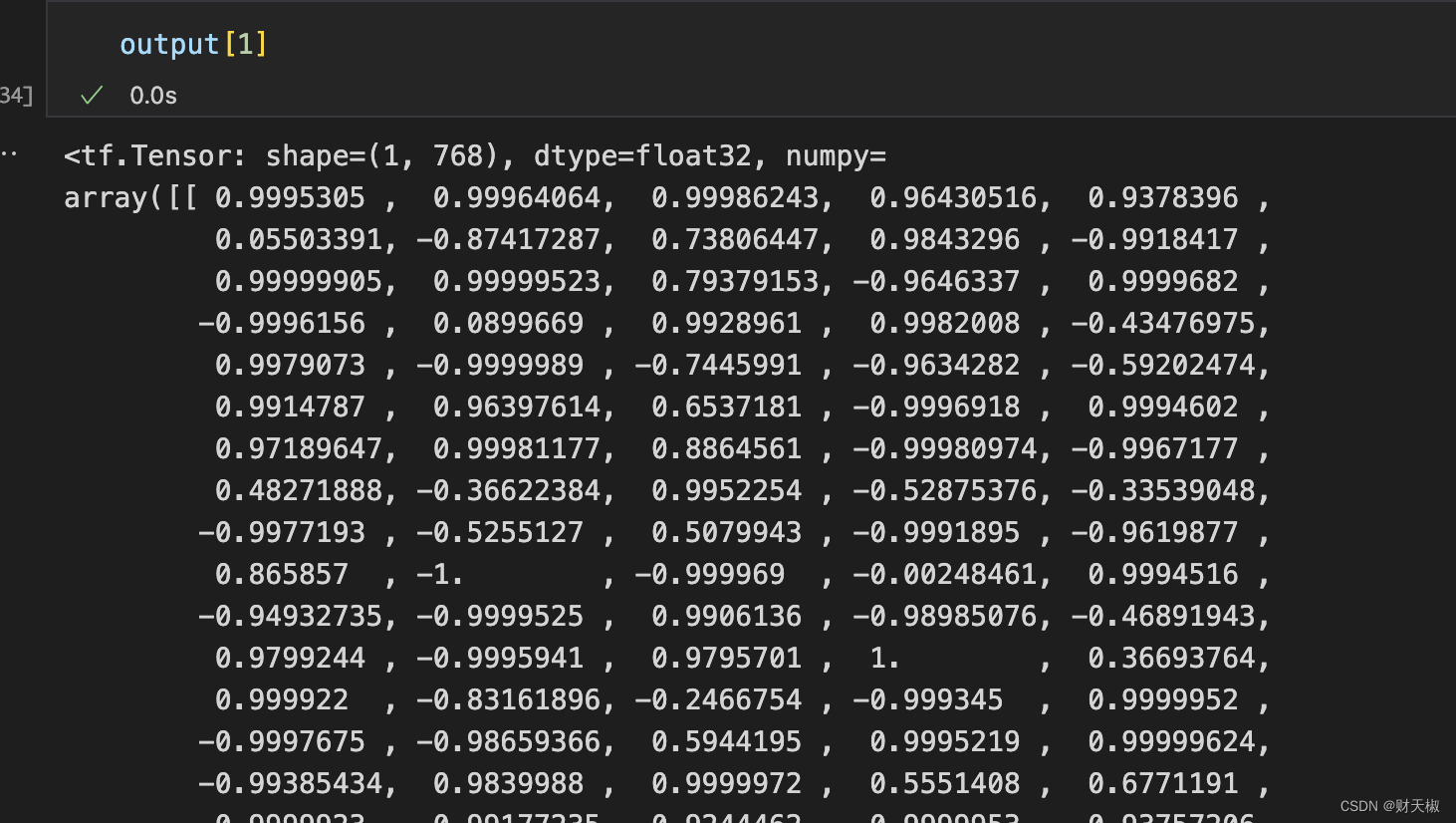
- 用来做分类的向量具体操作方法如下所示, output[1],取到的东西是pooler_output
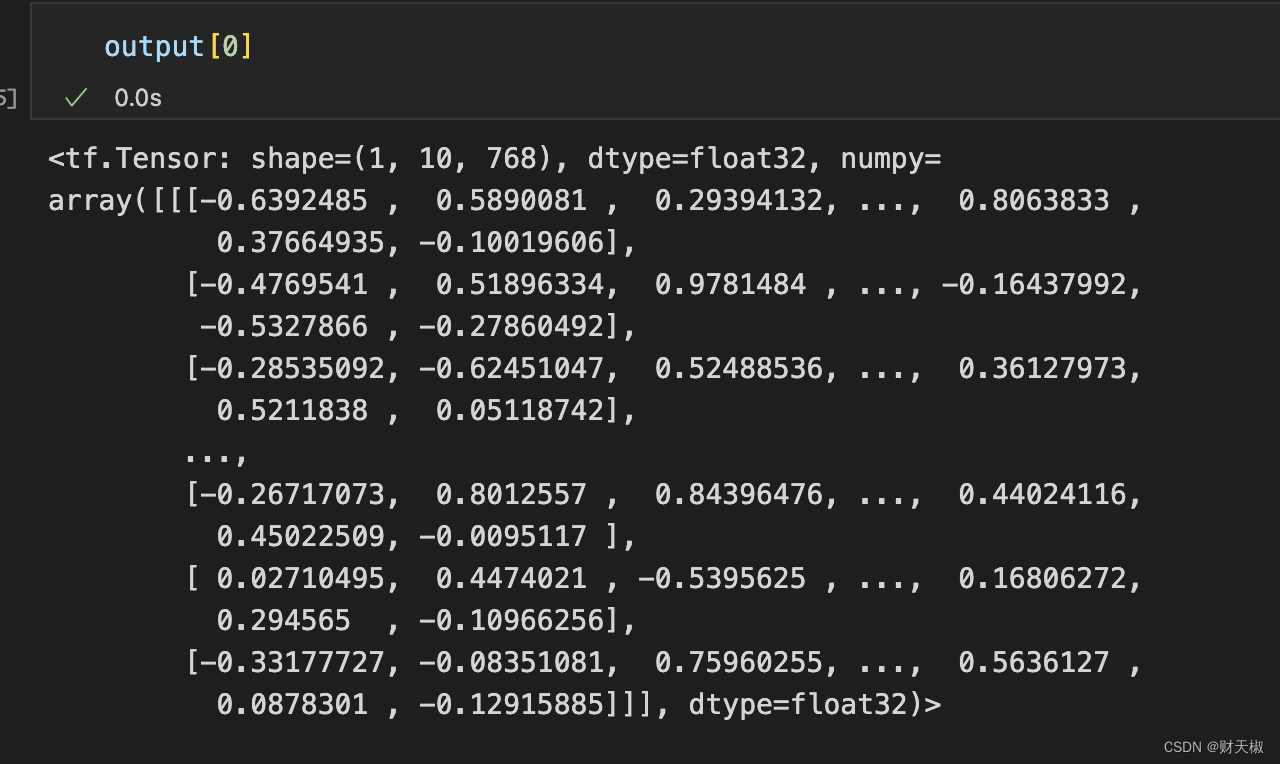
- 通常取到的bert的embdedding向量的方法如下所示, output[0],其中一般在后面接一个池化层将其转为[batch_size, 768]的数据shape:
🔍 3. 注意事项
- 根据任务的需求选择适合的bert模型版本,例如bert-base-uncased或bert-large-cased。
- 在使用bert时,注意[cls]和[sep]等特殊标记的使用,它们在模型的输入和输出中扮演重要角色。
- bert模型计算量大,对于大规模数据集或实时应用,可能需要使用gpu加速。

发表评论