transformer的pytorch实现有多个开源版本,基本大同小异,我参考的是这份英译中的工程。
为了代码讲解的直观性,还是先把transformer的结构贴上来。
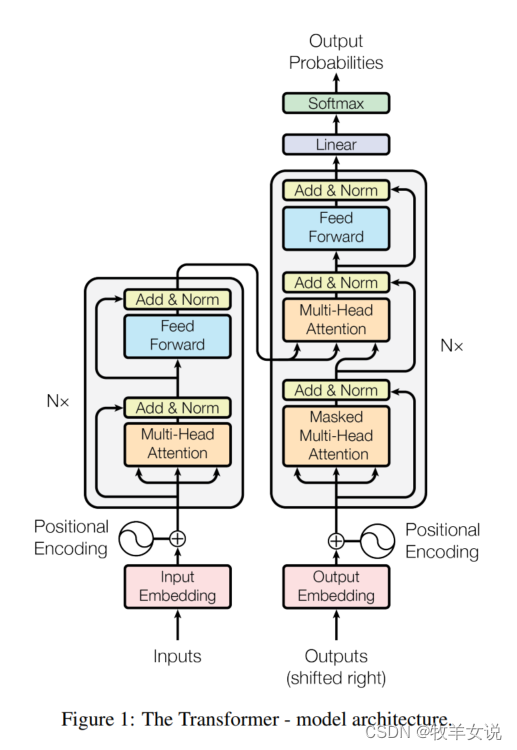
针对上述结构,我们从粗到细地来看一下模型的代码实现。
1. 模型整体构造
class transformer(nn.module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(transformer, self).__init__()
self.encoder = encoder # 编码端,论文中包含了6个encoder模块
self.decoder = decoder # 解码端,也是6个decoder模块
self.src_embed = src_embed # 输入embedding模块
self.tgt_embed = tgt_embed # 输出embedding模块
self.generator = generator # 最终的generator层,包括linear+softmax
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
# encoder的结果作为decoder的memory参数传入,进行decode
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
通过make_model()函数对transformer模型进行构造:
def make_model(src_vocab, tgt_vocab, n=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
# 实例化attention对象
attn = multiheadedattention(h, d_model).to(device)
# 实例化feedforward对象
ff = positionwisefeedforward(d_model, d_ff, dropout).to(device)
# 实例化positionalencoding对象
position = positionalencoding(d_model, dropout).to(device)
# 实例化transformer模型对象
model = transformer(
encoder(encoderlayer(d_model, c(attn), c(ff), dropout).to(device), n).to(device),
decoder(decoderlayer(d_model, c(attn), c(attn), c(ff), dropout).to(device), n).to(device),
nn.sequential(embeddings(d_model, src_vocab).to(device), c(position)),
nn.sequential(embeddings(d_model, tgt_vocab).to(device), c(position)),
generator(d_model, tgt_vocab)).to(device)
# this was important from their code.
# initialize parameters with glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
# 这里初始化采用的是nn.init.xavier_uniform
nn.init.xavier_uniform_(p)
return model.to(device)
那么,接下来,我们就对以上涉及到的模块进行一一实现。
2. mutiheadedattention
mutiheadedattention()实现的是论文中的如下结构:
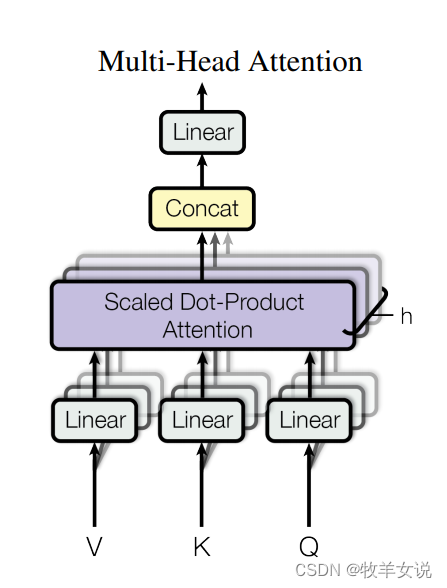
class multiheadedattention(nn.module):
def __init__(self, h, d_model, dropout=0.1):
super(multiheadedattention, self).__init__()
# h为head数量,保证可以整除,论文中该值是8
assert d_model % h == 0
# 得到一个head的attention表示维度,论文中是512/8=64
self.d_k = d_model // h
# head数量
self.h = h
# 定义4个全连接函数,供后续作为wq,wk,wv矩阵和最后h个多头注意力矩阵concat之后进行变换的矩阵wo
self.linears = clones(nn.linear(d_model, d_model), 4)
self.attn = none
self.dropout = nn.dropout(p=dropout)
def forward(self, query, key, value, mask=none):
if mask is not none:
mask = mask.unsqueeze(1)
# query的第一个维度值为batch size
nbatches = query.size(0)
# 将embedding层乘以wq,wk,wv矩阵(均为全连接)
# 并将结果拆成h块,然后将第二个和第三个维度值互换
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 调用attention函数计算得到h个注意力矩阵跟value的乘积,以及注意力矩阵
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 将h个多头注意力矩阵concat起来(注意要先把h变回到第三维的位置)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 使用self.linears中构造的最后一个全连接函数来存放变换后的矩阵进行返回
return self.linears[-1](x)
其中,主体attention函数的定义在该模块之外,主要实现下面这个结构,当然,是批量实现h个这样的结构:
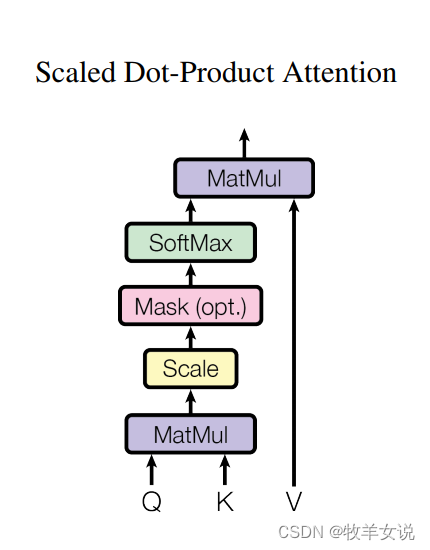
def attention(query, key, value, mask=none, dropout=none):
# 将query矩阵的最后一个维度值作为d_k
d_k = query.size(-1)
# 将key的最后两个维度互换(转置),才能与query矩阵相乘,乘完了还要除以d_k开根号
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 如果存在要进行mask的内容,则将那些为0的部分替换成一个很大的负数
if mask is not none:
scores = scores.masked_fill(mask == 0, -1e9)
# 将mask后的attention矩阵按照最后一个维度进行softmax,归一化到0~1
p_attn = f.softmax(scores, dim=-1)
# 如果dropout参数设置为非空,则进行dropout操作
if dropout is not none:
p_attn = dropout(p_attn)
# 最后返回注意力矩阵跟value的乘积,以及注意力矩阵
return torch.matmul(p_attn, value), p_attn3. positionwisefeedforward
接下来,我们按照make_model()函数中的顺序,来看看positionwisefeedforward模块。该模块相对较简单,公式如下:
![]()
代码如下:
class positionwisefeedforward(nn.module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(positionwisefeedforward, self).__init__()
self.w_1 = nn.linear(d_model, d_ff)
self.w_2 = nn.linear(d_ff, d_model)
self.dropout = nn.dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(f.relu(self.w_1(x))))
4. positionalencoding
位置编码在论文中的实现公式如下:
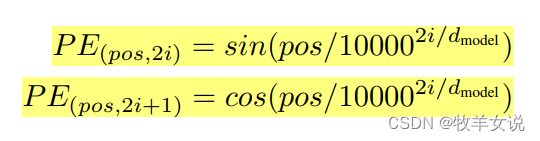
代码:
class positionalencoding(nn.module):
def __init__(self, d_model, dropout, max_len=5000):
super(positionalencoding, self).__init__()
self.dropout = nn.dropout(p=dropout)
# 初始化一个size为 max_len(设定的最大长度)×embedding维度 的全零矩阵
# 来存放所有小于这个长度位置对应的positional embedding
pe = torch.zeros(max_len, d_model, device=device)
# 生成一个位置下标的tensor矩阵(每一行都是一个位置下标)
"""
形式如:
tensor([[0.],
[1.],
[2.],
[3.],
[4.],
...])
"""
position = torch.arange(0., max_len, device=device).unsqueeze(1)
# 这里幂运算太多,我们使用exp和log来转换实现公式中pos下面要除以的分母(由于是分母,要注意带负号),已经忘记中学对数操作的同学请自行补课哈
div_term = torch.exp(torch.arange(0., d_model, 2, device=device) * -(math.log(10000.0) / d_model))
# 根据公式,计算各个位置在各embedding维度上的位置纹理值,存放到pe矩阵中
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 加1个维度,使得pe维度变为:1×max_len×embedding维度
# (方便后续与一个batch的句子所有词的embedding批量相加)
pe = pe.unsqueeze(0)
# 将pe矩阵以持久的buffer状态存下(不会作为要训练的参数)
self.register_buffer('pe', pe)
def forward(self, x):
# 将一个batch的句子所有词的embedding与已构建好的positional embeding相加
# (这里按照该批次数据的最大句子长度来取对应需要的那些positional embedding值)
x = x + variable(self.pe[:, :x.size(1)], requires_grad=false)
return self.dropout(x)5. encoder
make_model()函数中的encoder是包含了整个encoder端的模块,包括6个encoder layer。
class encoder(nn.module):
# layer = encoderlayer
# n = 6
def __init__(self, layer, n):
super(encoder, self).__init__()
# 复制n个encoder layer
self.layers = clones(layer, n)
# layer norm
self.norm = layernorm(layer.size)
def forward(self, x, mask):
"""
使用循环连续eecode n次(这里为6次)
这里的eecoderlayer会接收一个对于输入的attention mask处理
"""
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
以上代码中,在encoder侧放置n=6个encoder layer,每个encoder layer的实现如下:
class encoderlayer(nn.module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(encoderlayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
# sublayerconnection的作用就是把multi和ffn连在一起
# 只不过每一层输出之后都要先做layer norm再残差连接
self.sublayer = clones(sublayerconnection(size, dropout), 2)
# d_model
self.size = size
def forward(self, x, mask):
# 将embedding层进行multi head attention
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# 注意到attn得到的结果x直接作为了下一层的输入
return self.sublayer[1](x, self.feed_forward)上面的sublayer其实就是残差连接,但是跟架构图上有一点区别,是先做的layernorm,再做residual,所以在整个encoder最后,又加了一次layernorm,见本小节最上面一段代码。
class sublayerconnection(nn.module):
"""
sublayerconnection的作用就是把multi-head attention和feed forward层连在一起
只不过每一层输出之后都要先做layer norm再残差连接
sublayer是lambda函数
"""
def __init__(self, size, dropout):
super(sublayerconnection, self).__init__()
self.norm = layernorm(size)
self.dropout = nn.dropout(dropout)
def forward(self, x, sublayer):
# 返回layer norm和残差连接后结果
return x + self.dropout(sublayer(self.norm(x)))
6. decoder
decoder的结构与encoder相似,但在每个decoder layer上多了一个残差连接的子层;并且需要用到encoder的输出,以及mask操作。
class decoder(nn.module):
def __init__(self, layer, n):
super(decoder, self).__init__()
# 复制n个encoder layer
self.layers = clones(layer, n)
# layer norm
self.norm = layernorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
使用循环连续decode n次(这里为6次)
这里的decoderlayer会接收一个对于输入的attention mask处理
和一个对输出的attention mask + subsequent mask处理
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
layers中包括n=6个decoder layer,每个decoder layer的实现如下:
class decoderlayer(nn.module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(decoderlayer, self).__init__()
self.size = size
# self-attention
self.self_attn = self_attn
# 与encoder传入的context进行attention
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(sublayerconnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
# 用m来存放encoder的最终hidden表示结果
m = memory
# self-attention:注意self-attention的q,k和v均为decoder hidden
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# context-attention:注意context-attention的q为decoder hidden,而k和v为encoder hidden
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)7. generator
generator就是我们上一篇文章所讲的the final linear and softmax layer。它的作用是,先把decoder的输出结果映射到词典大小的变量,再进行log_softmax操作计算出词典中各词的概率分布,从而为输出词语的选择提供依据(完整预测流程准备后面再开一篇讲)。
class generator(nn.module):
# vocab: tgt_vocab
def __init__(self, d_model, vocab):
super(generator, self).__init__()
# decode后的结果,先进入一个全连接层变为词典大小的向量
self.proj = nn.linear(d_model, vocab)
def forward(self, x):
# 然后再进行log_softmax操作(在softmax结果上再做多一次log运算)
return f.log_softmax(self.proj(x), dim=-1)8. embedding
最后,我们来看一下embedding。论文中对embedding的描述较简单,只有如下寥寥几句话,可能因为是在翻译领域比较成熟的技术了吧。

代码中对该功能的实现如下:
class embeddings(nn.module):
def __init__(self, d_model, vocab):
super(embeddings, self).__init__()
# embedding层
self.lut = nn.embedding(vocab, d_model)
# embedding维数
self.d_model = d_model
def forward(self, x):
# 返回x对应的embedding矩阵(需要乘以math.sqrt(d_model))
return self.lut(x) * math.sqrt(self.d_model)好了,今天的解读就先到这里。有更多补充内容,见后续更新。





发表评论