1.环境准备
本文是作者es系列的第三篇文章,关于es的核心概念移步:
关于es的下载安装教程以及基本使用,移步:
在前文中,我们已经搭建好了一个es+kibana的基础环境,本文将继续使用该环境,演示java操作es。
2.es java api
elasticsearch rest high level client 是 elasticsearch 官方提供的一个 java 客户端库,用于与 elasticsearch 进行交互。这个客户端库是基于 rest 风格的 http 协议,与 elasticsearch 进行通信,提供了更高级别的抽象,使得开发者可以更方便地使用 java 代码与 elasticsearch 进行交互。
依赖:
<dependency>
<groupid>org.elasticsearch</groupid>
<artifactid>elasticsearch</artifactid>
<version>7.17.3</version>
</dependency>
<dependency>
<groupid>org.elasticsearch.client</groupid>
<artifactid>elasticsearch-rest-high-level-client</artifactid>
<version>7.17.3</version>
</dependency>
<dependency>
<groupid>org.apache.logging.log4j</groupid>
<artifactid>log4j-core</artifactid>
<version>2.10.0</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.12</version>
</dependency>
<dependency>
<groupid>com.alibaba.fastjson2</groupid>
<artifactid>fastjson2</artifactid>
<version>2.0.45</version>
</dependency>其实rest high level client的使用逻辑一共就分散步:
- 拼json
- 创建request
- client执行request
创建client:
resthighlevelclient resthighlevelclient = new resthighlevelclient(restclient.builder(new httphost("127.0.0.1",9200,"http")));创建索引:
@test
public void createindex() throws ioexception {
//1.拼json
//settings
settings.builder settings = settings.builder()
.put("number_of_shards", 3)
.put("number_of_replicas", 1);
//mappings
xcontentbuilder mappings = jsonxcontent.contentbuilder().
startobject().
startobject("properties").
startobject("name").
field("type", "text").
endobject().
startobject("age").
field("type", "integer").
endobject().
endobject().
endobject();
//2.创建request
createindexrequest createindexrequest = new createindexrequest("person").settings(settings).mapping(mappings);
//3.client执行request
resthighlevelclient.indices().create(createindexrequest, requestoptions.default);
}创建文档:
@test
public void createdoc() throws ioexception {
person person=new person("1","zou",20);
jsonobject json = jsonobject.from(person);
system.out.println(json);
indexrequest request=new indexrequest("person",null,person.getid().tostring());
request.source(json, xcontenttype.json);
indexresponse response = resthighlevelclient.index(request, requestoptions.default);
system.out.println(response);
}响应结果:

修改文档:
@test
public void updatedoc() throws ioexception {
hashmap<string, object> doc = new hashmap();
doc.put("name","张三");
string docid="1";
updaterequest request=new updaterequest("person",null,docid);
updateresponse response = resthighlevelclient.update(request, requestoptions.default);
system.out.println(response.getresult().tostring());
}删除文档:
@test
public void deletedoc() throws ioexception {
deleterequest request=new deleterequest("person",null,"1");
deleteresponse response = resthighlevelclient.delete(request, requestoptions.default);
system.out.println(response.getresult().tostring());
}响应结果:
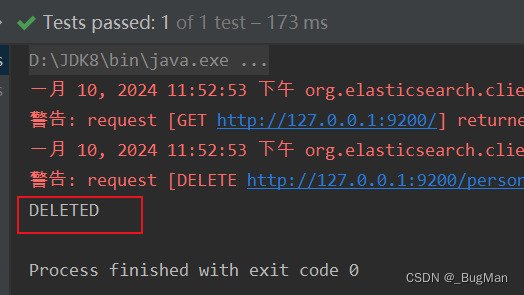
搜索示例:
import org.elasticsearch.action.search.searchrequest;
import org.elasticsearch.action.search.searchresponse;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.client.resthighlevelclient;
import org.elasticsearch.common.unit.timevalue;
import org.elasticsearch.index.query.querybuilders;
import org.elasticsearch.search.builder.searchsourcebuilder;
import java.io.ioexception;
public class elasticsearchsearchexample {
public static void main(string[] args) {
// 创建 resthighlevelclient 实例,连接到 elasticsearch 集群
resthighlevelclient client = new resthighlevelclient(
restclient.builder(new httphost("localhost", 9200, "http"))
);
// 构建搜索请求
searchrequest searchrequest = new searchrequest("your_index"); // 替换为实际的索引名称
// 构建查询条件
searchsourcebuilder searchsourcebuilder = new searchsourcebuilder();
searchsourcebuilder.query(querybuilders.matchallquery()); // 查询所有文档
// 设置一些可选参数
searchsourcebuilder.from(0); // 设置起始索引,默认为0
searchsourcebuilder.size(10); // 设置返回结果的数量,默认为10
searchsourcebuilder.timeout(new timevalue(5000)); // 设置超时时间,默认为1分钟
// 将查询条件设置到搜索请求中
searchrequest.source(searchsourcebuilder);
try {
// 执行搜索请求
searchresponse searchresponse = client.search(searchrequest, requestoptions.default);
// 处理搜索响应
system.out.println("search took: " + searchresponse.gettook());
// 获取搜索结果
searchhits hits = searchresponse.gethits();
system.out.println("total hits: " + hits.gettotalhits().value);
// 遍历搜索结果
for (searchhit hit : hits.gethits()) {
system.out.println("document id: " + hit.getid());
system.out.println("source: " + hit.getsourceasstring());
}
} catch (ioexception e) {
// 处理异常
e.printstacktrace();
} finally {
try {
// 关闭客户端连接
client.close();
} catch (ioexception e) {
// 处理关闭连接异常
e.printstacktrace();
}
}
}
}请注意,上述示例中的 your_index 应该替换为你实际的 elasticsearch 索引名称。这个示例使用了简单的 matchallquery,你可以根据实际需求构建更复杂的查询条件。在搜索响应中,你可以获取到搜索的结果以及相关的元数据。
3.spring boot操作es
在 spring boot 中操作 elasticsearch 通常使用 spring data elasticsearch,以标准的jpa的模式来操作es。
依赖:
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>2.6.x</version> <!-- 选择一个与elasticsearch 7.17.3兼容的spring boot版本 -->
</parent>
<dependencies>
<!-- spring boot starter web -->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-web</artifactid>
</dependency>
<!-- spring data elasticsearch -->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-data-elasticsearch</artifactid>
</dependency>
<!-- spring boot starter test (for testing) -->
<dependency>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-test</artifactid>
<scope>test</scope>
</dependency>
</dependencies>
application.properties配置:spring.data.elasticsearch.cluster-nodes=localhost:9200
实体类:
import org.springframework.data.annotation.id;
import org.springframework.data.elasticsearch.annotations.document;
import org.springframework.data.elasticsearch.annotations.field;
import org.springframework.data.elasticsearch.annotations.fieldtype;
import java.util.date;
@document(indexname = "blogpost_index")
public class blogpost {
@id
private string id;
@field(type = fieldtype.text)
private string title;
@field(type = fieldtype.text)
private string content;
@field(type = fieldtype.keyword)
private string author;
@field(type = fieldtype.date)
private date publishdate;
// 构造函数、getter和setter
public blogpost() {
}
public blogpost(string id, string title, string content, string author, date publishdate) {
this.id = id;
this.title = title;
this.content = content;
this.author = author;
this.publishdate = publishdate;
}
// 省略 getter 和 setter 方法
}dao层:
import org.springframework.data.elasticsearch.repository.elasticsearchrepository;
public interface blogpostrepository extends elasticsearchrepository<blogpost, string> {
// 你可以在这里定义自定义查询方法
}service层:
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.service;
import java.util.list;
import java.util.optional;
@service
public class blogpostservice {
private final blogpostrepository blogpostrepository;
@autowired
public blogpostservice(blogpostrepository blogpostrepository) {
this.blogpostrepository = blogpostrepository;
}
public blogpost save(blogpost blogpost) {
return blogpostrepository.save(blogpost);
}
public optional<blogpost> findbyid(string id) {
return blogpostrepository.findbyid(id);
}
public list<blogpost> findall() {
return (list<blogpost>) blogpostrepository.findall();
}
public void deletebyid(string id) {
blogpostrepository.deletebyid(id);
}
}到此这篇关于java操作elastic search的文章就介绍到这了,更多相关java操作elastic search内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!

发表评论