微服务和高并发:随着传统开发逐渐转向微服务架构,面向"老百姓"的应用需要处理的并发量急剧增加。在这种高并发环境下,传统关系型数据库在增删改查操作上的速度往往跟不上项目的需求。
传统开发解决高并发的策略:
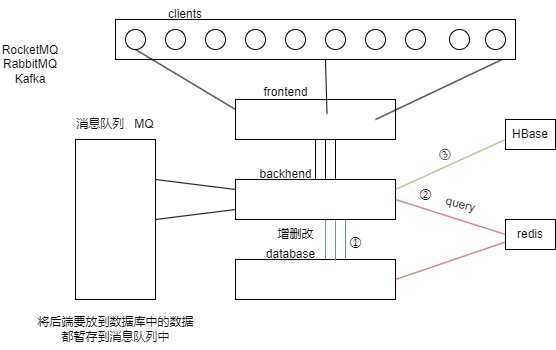
- ① 将数据库中的数据定期存储到redis中,后端查询操作直接面向redis来执行。
- ② 构建数据库的redis的集群化。
引入hbase的原因:当redis的存储能力不足或主从结构过于复杂导致效率下降,hbase成为一个优秀的选择。hbase以其【快速的读写速度】和【高吞吐量】,能够有效且快速地处理大数据的增删改查操作。
hbase特点:
- ① 高吞吐量的读写操作
- 为什么hbase有快速的读写速度(高吞吐量)?
- 写操作:
- 内存写入:所有的写操作首先被写入到memstore中,这一操作是在内存中完成的,高效。并且对于hbase而言,只要数据写入memstore存储区就标志着写操作已经完成,无需等待落盘。
- 数据备份:在数据刷新到磁盘之前,所有的写操作都会被记录在hlog,即使故障,也能够恢复数据。
- 并行写操作:hbase的每个列族对应一个memstore,能够对不同列族的数据进行并行处理。
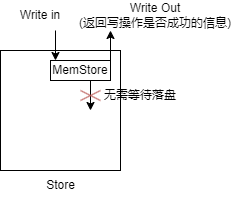
- 如何理解"无需暂停写入操作以等待数据落盘"的设计理念?
- memstore提供了一种暂存数据的方式,直至数据被刷新到磁盘上的storefile中。
- 通过wal机制保证memstore在数据未落盘时发生故障也不会导致数据丢失。
- 保障数据一定能够落盘(即使数据丢失也可以通过hlog恢复数据),此时可以认为操作已经完成。
- 因此写入的数据得到保障后,允许系统在高吞吐量的情况下继续接受和处理新的写请求。
- 读操作:
- 读操作可以直接从内存中的memstore或者是缓存中的blockcache获取数据
- 使用bloom filter检查所需的数据是否不在storefile中,如果数据不在那里,能够及时终止读操作,避免了不必要的磁盘访问。
- (为什么bloom filter能够实现快速检查的功能?bloomfilter的算法原理。)
- ② hbase天生支持集群部署,无需进行复杂的分表或者分库操作。简化了大规模数据处理的复杂性。
- ③ hbase是列式存储
- 列式存储和行式存储的理解
- 定义
- 列式存储是指每一列的数据存储在一起。
- 行式存储是指每一行的数据存储在一起。
- 列式存储的优势
- 高效的数据存储ÿ

发表评论