
摘要
无代码–
目标检测的两种方法:cnn-based 和 transformer-based, 前者将该任务视为 a dense local matching problem, and the latter sees it as s sparse global retrieval problem.
research in neuroscience has shown that the recognition decision in the brain is based on two processes, namely familiarity and recollection(熟悉和回忆).
网络结构:it integrates cnn- and transformer-based detectors into a comprehensive object detection system consisting of a shared backbone, an efficient dual-stream encoder, and a dynamic dual-decoder.
为了使基于cnn和transform的解码器之间能够更好地协调,我们为双解码器提供了一个选择性掩码。该掩码根据高级表示为图像中的每个位置动态选择更有利的解码器。正如大量实验所证明的那样,我们的方法在不增加flop的情况下将各种源检测器的map提示为3.0 3.7方面显示出灵活性和有效性。
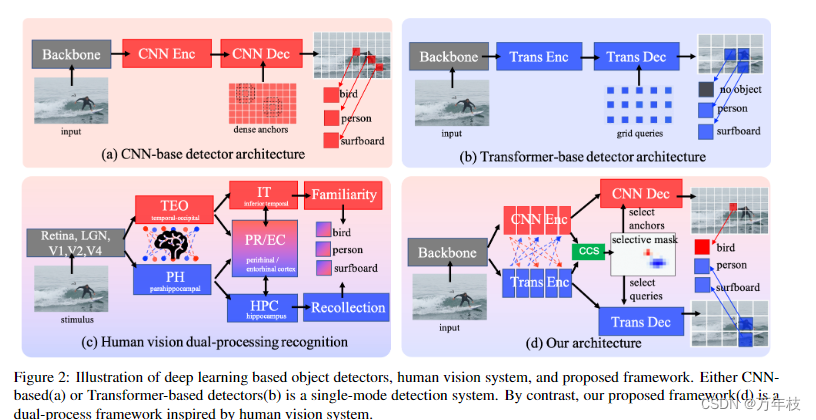
图1:我们提出的方法可以将基于cnn和transformer的探测器的优势与选择性掩码动态结合起来,以实现更好的性能。鸟类的形状和姿势携带丰富的局部模式,但鸟类在海里不常见,因此缺乏上下文信息,而冲浪板的一半被淹没在海里,因此缺少局部特征,但它携带足够的上下文信息,例如人的姿势和海浪。因此,前者可以更好地被基于cnn的探测器定位,后者更容易被基于transformer的探测器定位。

引言
cnn- and transformer-based detectors can be structured into a backbone-encoder-decoder architecture.
this architecture includes a backbone that extracts rich and general shallow features, an encoder that generates task-relevant high-level representations, and a decoder that predicts the results.
神经科学家发现,熟悉感与不同的视觉皮层区域有关,其生物学机制体现在cnn架构中,而回忆通常归因于与transformer关系密切的海马体。
最近的一些工作试图通过将一种方法的关键性能引入另一种方法来提高cnn-transform混合方法[7,43,6,8,37]的检测器性能。然而,他们只考虑了类似熟悉的基于cnn的编解码pipeline 或 基于类回忆的transformer pipeline,不能同时反映双过程机制。
本文提出 dynamic dual-processing framework,ddp 模拟大脑的熟悉和回忆过程,如图2d.
它由一个共享的骨干网、一个高效的双流编码器和一个动态的双解码器组成。虽然很容易想到使用两个独立的基于cnn和transverter的编码解码分支,但这两个检测器的简单集成成本很高,并且只能产生边际改进。
为了实现有效和高效的组合,有两个关键问题需要解决:1)信息如何在编码器中的cnn和transformer流之间交互和集成;2)两个解码器如何合作和聚合预测以实现最佳性能。
为了解决第一个问题,我们的双流编码器(dse, dual-stream-encoder)保留了cnn和trans-former编码流,并允许沿每个流进行中间特征交互,这与以前的混合单流编码器不同。我们使用neural network architecture search method 来寻找最佳深度和特征融合策略,而不是手动设计特征交互策略。
为了解决第二个问题,与简单地组装两个独立解码器的预测相反,我们提供了一个配备二进制选择掩码的动态双解码器(dynamic dual-decoder, ddd)。该掩码基于高级表示为图像中的每个位置动态选择更有利的解码器,如图1(c)所示。该掩码的学习可以看作是基于cnn和transform的解码器在预测相应位置的目标方面的竞争。因此,它避免了冗余计算,并使每个解码器能够专注于自己强大的一面,避免弱点,如图1(d)所示。我们表明,所提出的框架在coco数据集[23]上的准确性和模型复杂度方面取得了有希望的性能。
人类视觉系统到神经网络检测器
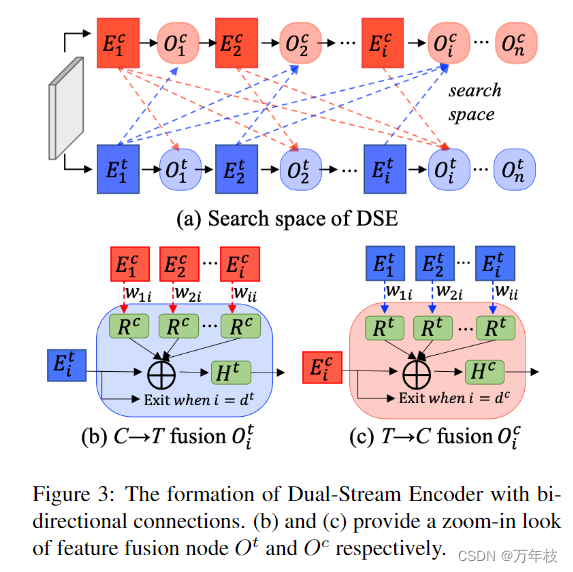
图3:具有双向连接的双流编码器的形成。(b)和(c)分别提供特征融合节点ot和oc的放大外观。
hint1:具有共享主干的双cnn和类似transform的识别路径。
如图2(c)所示,在通过共享的retina、lgn、v1、v2和v4后,视觉刺激由双过程识别模型处理[44]。teo-it和ph-hpc分别与熟悉度和回忆度相关联。上述发现表明,要模仿双过程识别模型,基于cnn(熟悉度)和transform(回忆度)的模块应该共存于对象检测器的编码器和解码器中,并且它们可以共享相同的主干。
hint2:cnn和transform pathways之间的交互在编码视觉信息时。
在上述双过程模型的编码器中,研究人员还发现了teo和ph之间的双向交互[40],这使得能够为teo-it和ph-hpc路径创建上下文绑定表示和注意链接表示。然而,交互机制如此复杂,以至于没有得到充分利用。这些研究表明,cnn和transform处理路径之间的双向连接使视觉系统能够通过融合上下文和注意力特征来获得增强的特征。为了实现这一未知特征融合过程,我们使用神经网络搜索来找到一个满意的架构。
hint3:cnn和transform解码器协同工作。
如上所述,熟悉和回忆负责基于快速匹配的识别和基于缓慢检索的识别[44]。它们的协作由pr/ec模块控制[2]。上述过程意味着应该有一种机制,在检测不同的对象时自适应地决定使用cnn或transform解码器,这是我们动态双解码器设计中的一个选择性掩码。
动态双向处理网络
包括 dual-stream encoder, dynamic dual-decoder,
e
1
c
∼
e
n
c
e_1^c \sim e_n^c
e1c∼enc和
e
1
t
∼
e
n
t
e_1^t \sim e_n^t
e1t∼ent是[38]和[3]的注释,代表cnn和transformer-encode的一系列重复块.
为简化,本文使用n为cnn-和transformer-based encoders 在 dse的最大块数,但事实上两者最大块数可能会不同。
另外,设立中间节点
o
1
c
∼
o
n
c
o_1^c \sim o_n^c
o1c∼onc和
o
1
t
∼
o
n
t
o_1^t \sim o_n^t
o1t∼ont,其中来自cnn编码器的局部特征和来自transformer-编码器的全局自注意特征将被组合和增强。此外,每个节点还应确定是否停止特征编码过程并在语义足够丰富的情况下直接将编码后的特征输出到解码器。
为了找到计算复杂度适中的最优特征融合策略,应用了神经网络搜索方法。因此,我们将我们的dse定制为一个可搜索的直接非循环超网,类似于[10],搜索空间包含特征流边缘和编码器深度。具体而言,如图3(b)所示,transformer-stream的第i个节点
o
i
t
o_i^t
oit的输出可以表示为
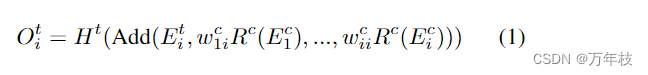
至于对于cnn-based结构,输出有稍许不同;
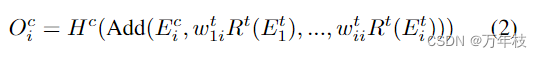
与[10]不同,dse中每个流的深度也是可搜索的,其中深度可以是在范围(1, n)中变化的离散数
d
c
d^c
dc或
d
t
d^t
dt。例如,一旦为transform-steam指定了活动编码器深度
d
t
d^t
dt,transformer-steam中
e
d
t
t
e^t_ {d^t}
edtt的输出将直接输出到解码器,并且路径上剩余的编码器块和融合节点将不会被激活,这对于基于cnn的流也是如此。总体而言,通过组合特征融合节点和编码器块的数量,我们的总搜索空间容量为
o
(
n
2
2
n
2
)
o(n^2 2^{n^2})
o(n22n2)。
绿色方框(ccs)代表concat-conv-gumbelsoftmax操作,用于生成掩码。如图4所示,该掩码被投影到锚点和查询的坐标空间,然后强加给它们,其中1在cnn-解码器中激活锚点,0在相应位置激活变压器-解码器中的查询。值得注意的是,原始detr模型中的查询不包含任何空间先验,而在后来的作品中,如deformable detr[46]、anchor detr[41]和dab-detr[24],查询被赋予空间信息。因此,在我们的声明中,我们将dab-detr中的4d框式查询用于基于变压器的解码器。
基于上述描述,我们相应地将
d
c
d^c
dc和
d
t
d^t
dt定义为cnn和transformer-解码器,并将cnn解码器的锚点中心设置为a,将查询设置为q。我们定义了一个二进制掩码m,因此,我们的双解码器在掩码上的位置
(
y
,
x
)
(y, x)
(y,x)产生的预测
r
(
y
,
x
)
r(y,x)
r(y,x)可以表示如下

然而,在神经网络中学习这种二进制掩码具有挑战性,因为它non-differentiability 不可微性。为了解决这个问题,我们参考了gumbel-softmax重新参数化技巧[16],其中他们重新参数化一个非微分随机节点,该节点通过学习神经网络从分类分布中采样,作用于gumbel基本分布的随机噪声。有关gumbel-softmax重新参数化技巧的更多详细信息,请参阅[16]。在我们的例子中,我们使用选择性掩码m的输出来重新参数化一个i. i.d gumbel分布
g
i
∼
g
u
m
b
e
l
(
0
,
1
)
g_i \sim gumbel(0,1)
gi∼gumbel(0,1),
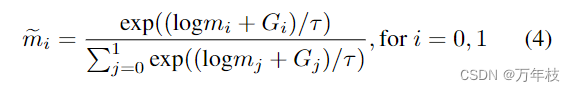
其中,
m
1
=
1
−
m
0
,
τ
>
0
m_1=1−m_0,τ>0
m1=1−m0,τ>0是决定softmax清晰度的温度参数。因此,我们得到了选择性掩码
m
~
\tilde{m}
m~的近似值。在前向传递中,我们使用
m
~
\tilde{m}
m~的 argmax 来执行锚点或查询的二元选择,在后向传递中,使用softmax启用基于梯度下降的训练。训练过程的细节将在下一节中解释.
ddp的多阶段学习
1.独立预训练
在我们的公式中,如果我们只考虑dse中没有特征交互的两条独立处理路径和ddd中的选择掩码,整个框架工作被退火到两个并行的基于cnn和transform的检测器的结构,具有共享的主干。我们将完整的检测器定义为n,参数θb、θe、θd分别用于主干、编码器和解码器。因此,作为起点,我们首先联合训练这个没有搜索空间和动态选择掩码的朴素组合,以优化这些参数,直到收敛。在这一步中,cnn和transform检测器都作为独立检测器单独工作。对于一批输入图像i,整体训练过程可以用
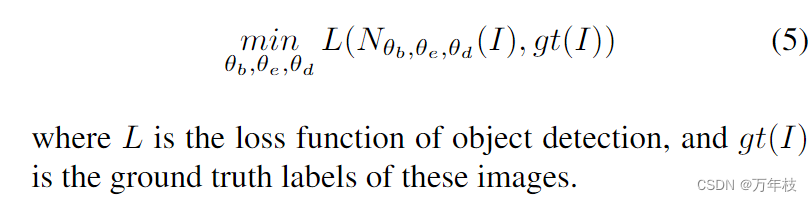
2.dse的搜索
对于融合策略和dse深度的搜索,我们参考[13],利用spos方法来执行nas任务。在这种方法中,参数化的超网被训练,然后搜索最优子网。在训练阶段,所有可能的子网都从搜索空间中独立均匀地采样,每个采样子网中的参数在每次迭代期间更新。在我们的例子中,对于dse超网训练的每次迭代,我们首先得到cnn和transformer-stream dc和dt的活动编码器深度,它们是从集合d={1,2,…, n}中随机选择的。在选择的深度下,对于
i
∈
(
1
,
d
c
)
,
j
≤
i
i \in (1, d^c), j≤i
i∈(1,dc),j≤i的融合策略
w
j
i
c
w_{ji}^c
wjic和
i
∈
(
1
,
d
c
)
,
j
≤
i
i \in (1, d^c), j≤i
i∈(1,dc),j≤i的融合策略
w
j
i
t
w_{ji}^t
wjit 是来自伯努利分布
b
e
r
n
(
0.5
)
bern(0.5)
bern(0.5)。
对于每个具体的
w
j
i
c
,
w
j
i
t
,
d
c
,
d
t
w^c_{ji},w^t_{ji},d^c ,d^t
wjic,wjit,dc,dt,可以得到特定的dse结构。因此,对于每批图像i,类似于公式5,可以得到:
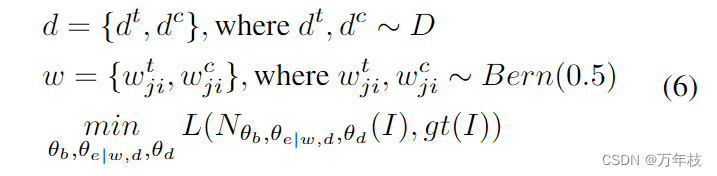
此外,在超网训练之前,我们将在第5.1节中加载前一步的预训练权重。在超网训练之后,我们可以有效地探索所有可能的子结构的性能,并通过在验证集上选择性能最好的子结构来找到给定复杂性约束的最优dse,结果
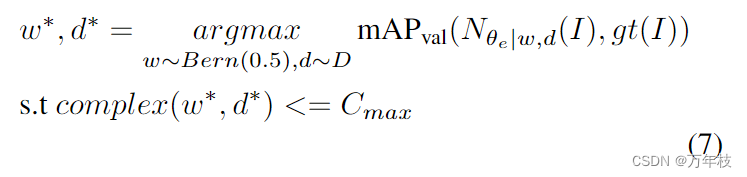
w
∗
w^*
w∗和
d
∗
d^*
d∗代表搜索到的dse的最佳融合策略和编码器深度,也满足复杂性约束
c
m
a
x
c_{max}
cmax。还参考[13],带有flops约束的进化搜索算法也用于寻找
w
∗
w^*
w∗和
d
∗
d^*
d∗。
3.选择性mask学习和联合训练
经过前面5.1和5.2节中的训练步骤,我们可以获得一个可接受的双检测器系统,该系统具有搜索的dse和双解码器,而不需要ddd中的动态选择掩码。如第4.2节所述,动态选择掩码不会对图像中的对象进行定位和分类,而是预测哪个解码器在图像中的给定位置表现更好。换句话说,我们不能用传统目标检测任务中的定位损失和对象类别分类损失来训练这个模块,而是将选择掩码纳入平均精度(map)的计算中,并直接最大化map。
更详细地说,我们定义了检测结果
r
c
(
y
a
,
x
a
)
r^c(y_a, x_a)
rc(ya,xa)给定cnn解码器的锚点
a
(
y
a
,
x
a
)
a(y_a,x_a)
a(ya,xa),
r
t
(
y
q
,
x
q
)
r^t(y_q, x_q)
rt(yq,xq)给定变压器解码器的
a
(
y
q
,
x
q
)
a(y_q,x_q)
a(yq,xq),并在等式4中的位置(y,x)处从gumbel-softmax预测选择性掩码
m
~
(
y
,
x
)
\tilde{m}(y,x)
m~(y,x)。因此,动态双解码器产生的(y,x)处的结果是

其中n是图像中gt对象的数量,gj是图像中的第j个gt,tp,fp表示确定预测r(y,x)是真阳性还是假阳性样本的规则。因此,给定一批图像i的训练损失函数可以写成
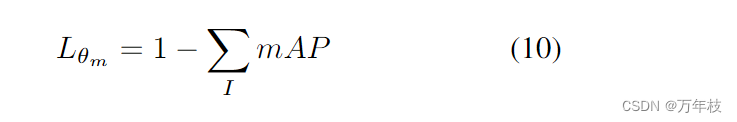
其中θm是生成选择掩码的子模块(ccs)的参数。在上述训练过程中,我们取主干的预训练权重、从上一步搜索到的dse和ddd并冻结它们的参数。
通过学习选择掩码,我们有效地弥补了一个检测器的弱点和另一个检测器的优势,我们相信通过联合训练双解码器和选择掩码的检测任务,锚/查询选择机制使cnn和基于转换的解码器更加专注于自己的优势,从而产生更好的整体性能。因此,最后我们附加了一个微调阶段,该阶段联合训练整个网络的检测和映射丢失。
实验
v100上运行
总结
本文使用了 熟悉-回忆 即 cnn&transformer-based 网络结构;使用了gumbel-softmax 方法;
本文提出了一种基于cnn和transformer的检测器协同结合的动态双进程目标检测框架,该框架由共享骨干网、高效双流编码器和动态双解码器三部分组成。两种主流检测器之间的集成的每一部分都经过了弹性设计,同时考虑了生物学的合理性和成本效益。实验结果表明,我们的方法灵活、有效,能够稳定地提高源模型的准确性,突破单一类型检测器的性能瓶颈。我们希望我们的工作将启发对下一代目标检测框架的进一步探索。




发表评论