23年12月来自复旦大学和华为诺亚实验室的论文“reason2drive: towards interpretable and chain-based reasoning for autonomous driving“。
大型视觉-语言模型(vlm)由于其在复杂推理任务中的先进能力,对高度自动驾驶汽车的行为至关重要,因此在自动驾驶领域引起了越来越多的兴趣。尽管它们有潜力,但由于缺乏带注释推理链的数据集来解释驾驶中的决策过程,自动驾驶系统的研究受到了阻碍。为了弥补这一差距,作者推出reason2drive,一个拥有超过60万个视频-文本对的基准数据集,旨在促进复杂驾驶环境中可解释推理的研究。将自动驾驶过程明确地描述为感知、预测和推理步骤的顺序组合,问答对是从各种开源户外驾驶数据集中自动收集的,包括nuscenes、waymo和once。此外,引入了一种新的聚合评估指标来评估自动驾驶系统中基于链的推理性能,解决了现有指标(如bleu和cider)的语义模糊性。基于所提出的基准,评估各种现有的vlm,揭示其推理能力的见解。此外,开发了一种有效的方法,使vlm能够在特征提取和预测中利用目标级感知元素,进一步提高其推理精度。
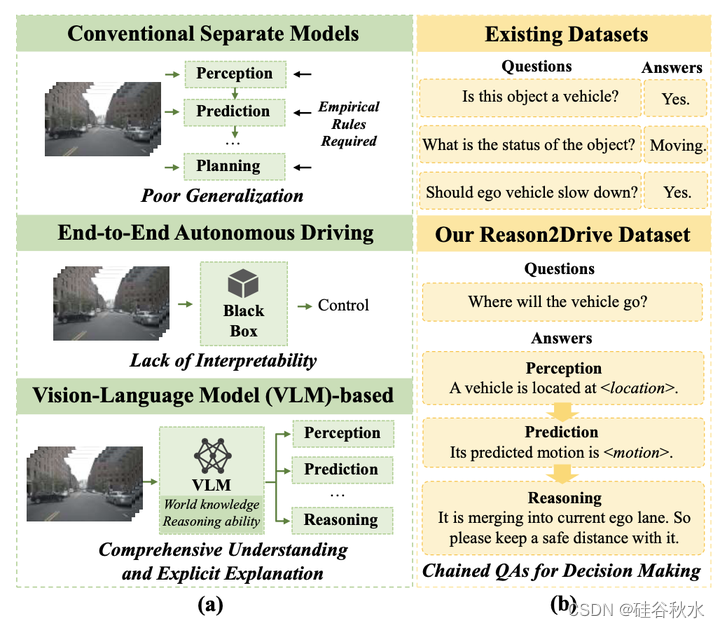
大型视觉语言模型(vlm)提供了一种很有前途的替代方案,有可能增强端到端系统的可解释性和通用性。如图(a)所示,凭借其广泛的世界知识和先进的推理能力,vlm有可能为可靠的决策提供更彻底的理解和明确的解释。尽管如此,现有的工作nuscenes-qa和“language prompt for autonomous driving”[33,41]主要集中在将问答任务直接适应自动驾驶;如何利用vlm来提高自主系统的推理能力仍在探索中。如图(b)所示,问答式推理数据集通常提供受限于布尔(即,是或否)答案或有限的多项选择响应(例如,停止、泊车和移动)的闭合形式注释。然而,自动驾驶转变了一个简单的qa过程。它包括一个多步骤的方法,包括感知、预测和推理,每一个都在决策中发挥着不可或缺的作用。因此,引入一种带有详细决策推理注释的新基准点来评估当前vlm的推理能力是至关重要的。
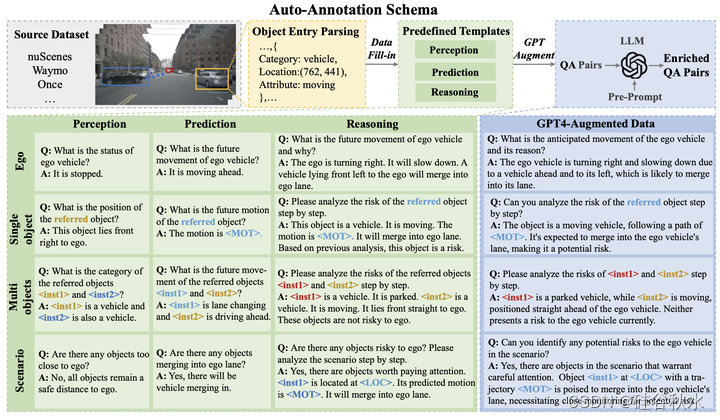
如图是reason2drive数据集的示意图。其用一个可扩展的注释模式,以问答对的形式构建数据。具体而言,首先利用在全球不同地区收集的各种公开可用数据集,包括nuscenes、waymo和once,然后将其全面的目标元数据解析为json结构化条目。每个目标条目都包含与其驾驶行为相关的各种详细信息,包括位置、类别、属性等。然后,这些提取的条目被填充到预定义的模板中,这些模板在目标级和场景级被划分为不同的任务(即感知、预测和推理)。随后,gpt-4和人工注释被用于验证和丰富目的。图上半部说明了数据集自动化构建的流程。下半部显示了感知、预测和推理的详细实例,以及应用gpt-4进行数据扩充后的结果。特殊标记有不同的定义:<inst*>表示指定的实例,表示轨迹坐标的预测序列,表示位置坐标。与这些标记相关联的颜色对应于左上角图像框中高亮显示的目标。
由于自动驾驶活动的复杂性,将任务分为三组获取多样化的数据:感知、预测和推理。这三类任务的具体内容和区别如下:
•感知任务旨在识别驾驶场景中的目标,评估vlm在户外环境中的基本感知能力。
•预测任务需要预测感知范围内关键目标的未来状态,挑战vlm通过视频输入推断目标的意图。
•推理任务促使逐步分析当前感知和预测状态,需要通过思维链(cot)方法进行合理推理和决策的演绎。
对于每个任务,进一步将数据分类为目标级和场景级。更详细地说,
•对目标级数据进行格式化,对特定目标的基本能力进行基准测试。在感知方面,解决了目标的位置和属性,如运动状态和与自车的距离,而在预测方面,考虑了未来的运动和融合状态。
•场景级数据是从全局角度组织的,涉及驾驶环境和自车驾驶指令。它关注的是当前是否有值得注意的目标(感知),未来是否有值得关注的目标(预测)以及为什么(推理)。例如,如上图所示,要求模型从整个场景中识别距离、合并状态和其他风险。它验证了智体感知整个驾驶场景的能力,而不是指定目标,因此更具挑战性和意义。
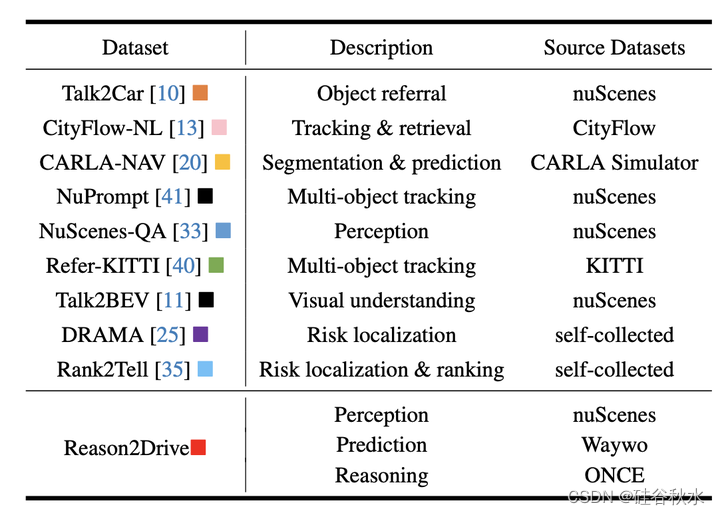
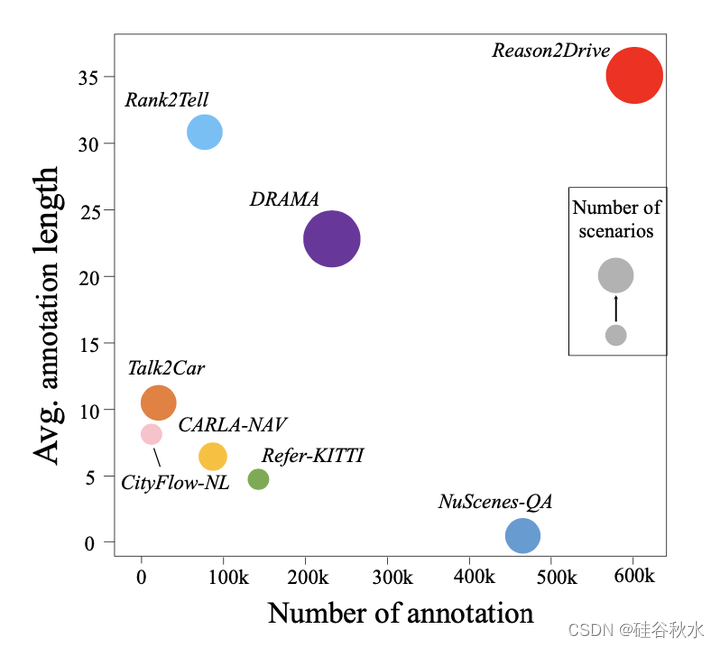
下表和下图展示了reason2drive数据集与现有基准之间的比较。值得注意的是,该基准是迄今为止最大的数据集,在数据集大小和包含大量基于长文本链的推理参考方面都超过了其他数据集。
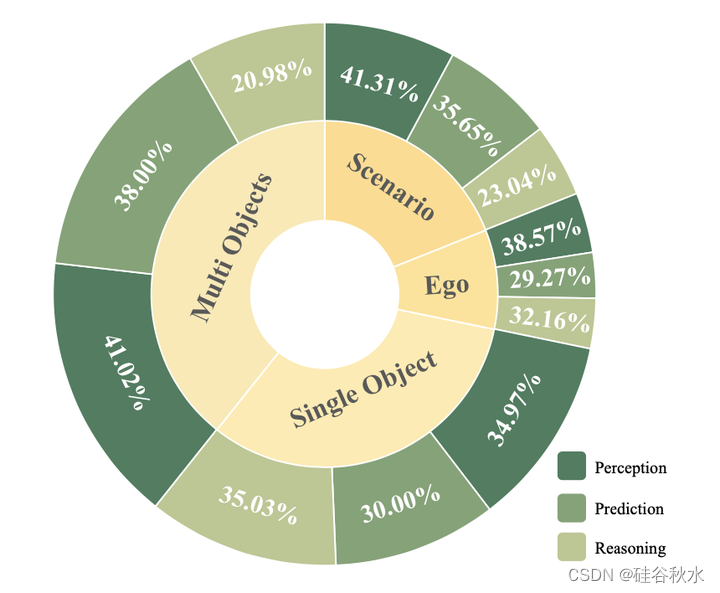
为了进一步研究reason2drive数据集的性质,在下图中统计了数据集的分布。基准测试呈现出平衡的分布,多目标任务占大多数。此外,感知、预测和推理问题分别占39%、34%和27%。
生成的推理步骤表示为假设{h1,…,hn},以及注释作为参考{r1,…,rk}。推理度量的核心是这个从n步假设h到k步参考的推理对齐向量:
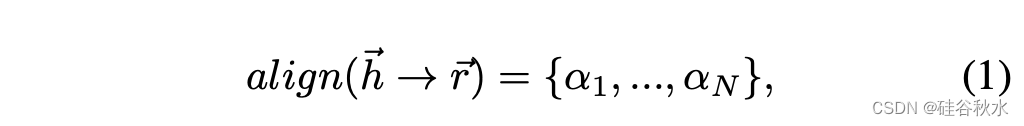
其中对齐值αi表示相应假设步骤和最相似参考步骤之间的语义相似性:
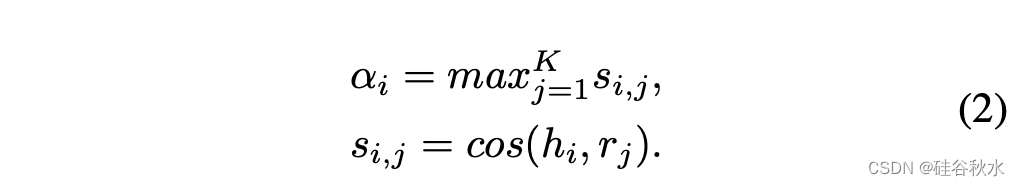
评估假设推理链正确性的最直接方法是比较假设和参考之间的重叠程度。一种方法是测量它们之间的推理对齐性:
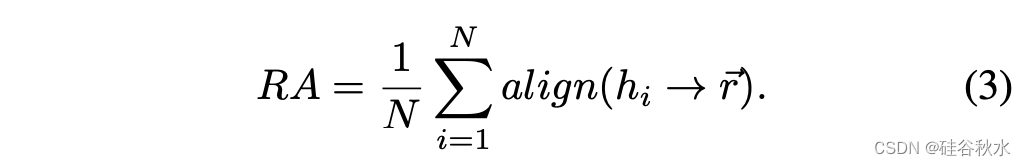
为了找到解决问题不需要信息的链(即冗余步骤),确定与参考步骤最不一致的假设步骤。此度量用正确解决方案不需要的步骤来惩罚链:

为了确定假设中缺失但可能用来解决问题的步骤,观察参考和假设之间的一致性,类似于冗余。遍历参考中的每个步骤,并检查假设中是否有类似的步骤:
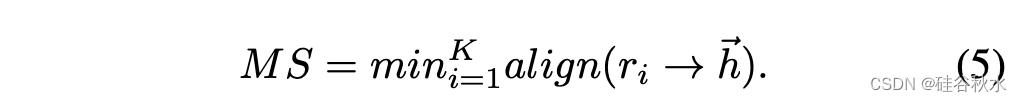
三个指标聚合在一起即是平均数:
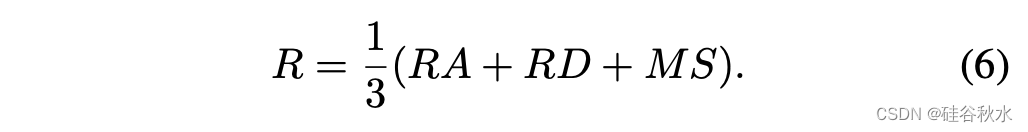
上述指标推广到有视觉元素的情况。具体而言,当假设步和参考步包含视觉元素,即预测用于进一步推理的位置和运动时,相似性得分变为:
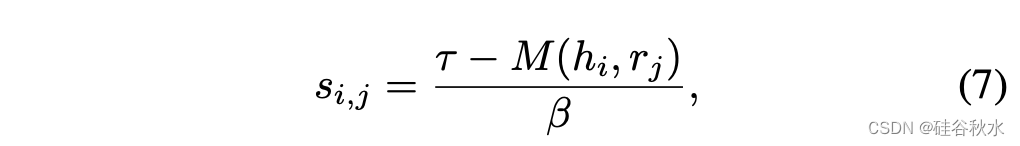
其中m(·)测量两个感知元素之间的均方误差。将其归一化为[0,1],匹配语义级相似性的分布。改进的严格推理度量旨在更准确地评估感知元素在内的推理反应。
大多数vlm难以有效处理目标级感知信息,包括视觉先验的输入和目标位置的预测,这在自动驾驶场景中是必不可少的。限制主要是由于(i)缺乏有针对性的token化器和(ii)解码器仅由语言模型组成,导致推理性能较差。为了解决这一挑战,如图所示引入了一个框架,用两个组件来增强现有的vlm:先验token化器和得到指令的视觉解码器。这些组件旨在增强模型在提取视觉先验和生成感知预测的过程中利用目标级感知元素的能力。q-former将它们与文本的特征空间对齐。llm和指示的视觉解码器利用用户查询的精确感知结果来预测答案。感知结果图像中高亮显示的黄色框和红色曲线分别表示和的可视化。
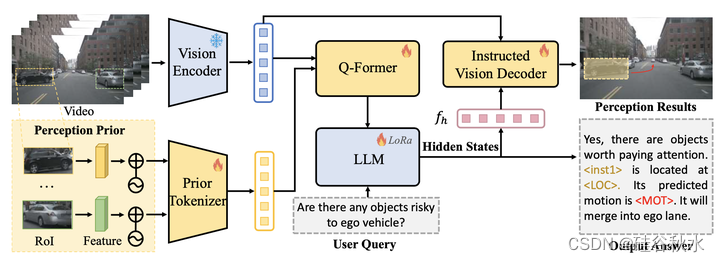
该模型接受视频帧和文本输入,以及感知先验,并将它们token化为嵌入。对于视频帧序列(v1,v2,…,vn),使用预训练的blip-2视觉编码器[22]fv提取特征,并通过级联进行聚合。
作者提出了一种token化策略,专门利用视觉线索。动机是:与强迫llm理解模糊的位置描述相比,提取和对齐视觉特征要简单得多,也更合适。对llm的直接文本输入可能导致诸如信息丢失之类的挑战,因为文本表示可能无法完全捕捉图像细节和上下文,尤其是在具有动态目标位置和速度的复杂场景中。为了解决这个问题,本文设计了一种新的token化器fp,实现为两层mlp,独立地从视觉先验中提取局部图像特征和位置嵌入。
使用roialign[17]运算将这些特征对齐到7×7大小,并融合到单个嵌入fr。其中采用位置编码,将几何位置和运动映射到fr的相同维度中。
将视频和感知先验token化之后,采用一个投影器q(blip-2的q-former[22])将非文本特征对齐到文本域中。然后,为了生成最终的文本输出,用llm对提取的文本进行进一步的语言处理。
对于受指令的视觉解码器设计,目前存在的工作talk2car和“drive like a human:rethinking autonomous driving with large language models“[10,14]将llm视为一种多功能工具,无需中间推理步骤即可生成答案和推理,更不用说考虑智体对驾驶场景的感知了。然而,智体对驾驶场景的感知能力是可靠驾驶过程中不可或缺的一部分。此外,最近的工作“lisa: reasoning segmentation via large language model“[21]已经证明,将感知能力结合到多模态llm中,而不是使用文本化的感知序列进行训练,可以带来显著的改进。
为此,受[21]的启发,作者将新的感知能力集成到多模态llm中。具体来说,通过引入新的token作为占位符(placeholders)来扩展原始llm词汇表,表示为和,表示对感知输出的请求。当llm旨在生成特定感知时,输出应包括设计的token。然后,提取与特定token对应的最后一层文本特征,并用mlp投影层来获得隐藏嵌入fh。最后,文本嵌入和视觉特征馈送到所指示的视觉解码器以解码预测。该模块由一个用于特征对齐的transformer解码器[3]和一个设计用于独立生成目标位置和运动的任务专用头组成。
模型微调策略包括两个阶段:预训练阶段和微调阶段。在预训练阶段,初始化instructionblip[9]中的权重,包括预训练的视觉编码器、q-former和llm,并冻结llm和视觉token化器fv的参数。训练先验token化器fp和q-former q,将视觉先验与文本对齐,还有训练受指示的视觉解码器d去增强视觉定位能力。微调阶段为llm配备了使用指令视觉解码器进行自动驾驶的推理能力。为了能够预训练的llm泛化,用lora[18]进行有效的微调。视觉编码器和先前的token化器fp保持固定,而受指示的视觉解码器d完全微调。llm和q-former的词嵌入,也是可训练的。
对于冻结的视觉编码器,用eva-clip[37]的vit-g/14,一种预训练视觉transformer模型。移除vit的最后一层,并使用倒数第二层的输出特性。
对于语言模型,探讨两种类型的llm:基于编码器-解码器的llm和基于解码器的llm。对于基于编码器-解码器的llm,用flant5-xl[7],这是一个基于编码器-译码器transformer t5[43]的指令调优模型。对于基于解码器的llm,选择vicuna[5],这是一个最近发布的解码器transformer指令,由llama[38]微调而来。

发表评论