近年以来,人工智能技术飞速发展,其主要分为鉴别和生成两个方面,其中人脸识别技术是其鉴别技术的重要分支,本文详细讲解使用opencv+sklearn+tensorflow技术,实现人脸识别的学习性项目。
一、系统功能分析
本项目具体功能模块如下所示:
1、采样样本照片
调用本地计算机摄像头采集照片作为样本,设置使用快捷键进行采样和取样,一次性可以多张照片,采样照片越多,人脸识别的成功率越高。
2、图片处理
将采集到原始图像转化为标准数据文件,即数据集。
3、深度学习
创建深度学习模型,学习训练、将训练结果保存为".h5"文件.
4、人脸识别
使用训练所得的模型实现人脸识别功能,即可以从本地摄像头识别,还可从网络摄像头识别。
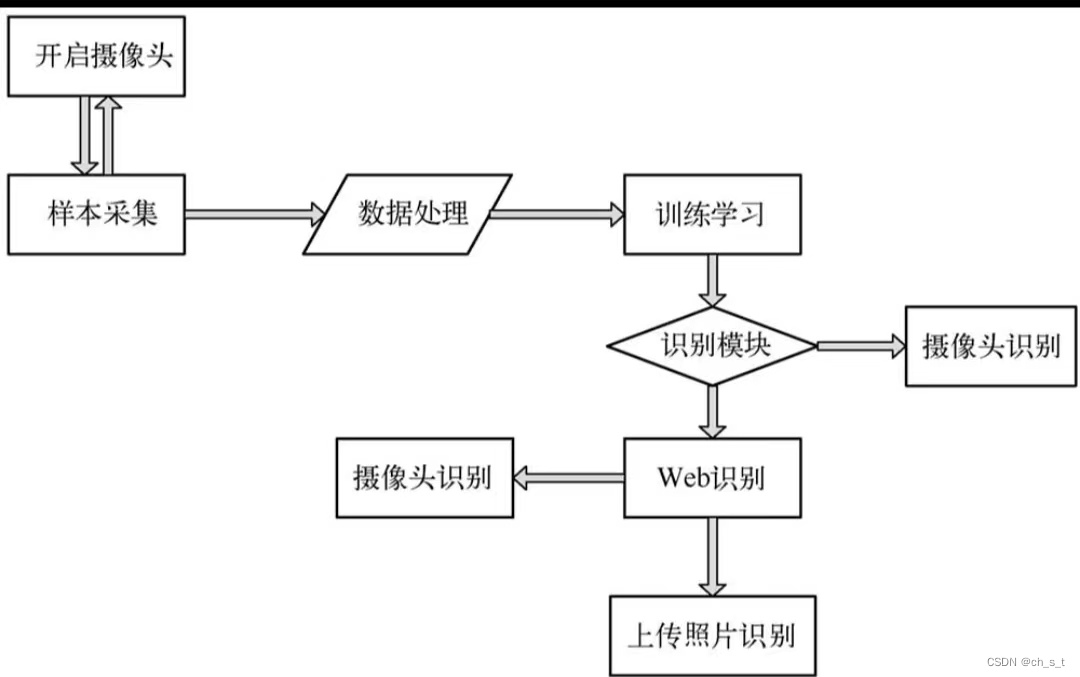
二、系统流程分析
项目实现的流程如下所示:
 三、技术分析
三、技术分析
项目主要用到以下的框架:
(1)flask
典型的python web开发框架
(2)opencv-python
它是opencv的python接口,一个开源发行的跨平台计算机视觉库,轻量级且高效(由一系列c函数和少量c++类构成),提供python,rupy,matlab等语言的接口,实现图像处理和计算机视觉方面的通用算法。
(3)sklearn
机器学习中常用第三方模块,对常用机器学习方法进行封装,包括回归、降维、分类、聚类等方法。
(4)tensorflow
tensorflow是一个由google brain团队开发的开源机器学习框架。最初是作为google内部工具而开发的,但随后在2015年被开源,以便更广泛的社群能够利用和贡献于这个框架。tensorflow支持从研究到生产的全面工作流程,包括模型设计、训练、优化和部署。
四、框架安装
安装以上框架需要使用以下命令:
pip install flask //安装flask框架
pip install opencv-python //安装opencv-python框架
pip install scikit-learn //安装sklearn框架
pip install tensorflow //安装tensoflow框架
五、照片样本采集
样本采集模块getcamerapics.py基本摄像头采集视频流中的数据,截取人脸照片作为样本并存储。具体代码如下:
import os
import cv2
import random
import numpy as np
from tensorflow.python.keras.utils import np_utils
from keras.models import sequential,load_model
from keras.layers import dense,activation,convolution2d,maxpooling2d,flatten,dropout
from sklearn.model_selection import train_test_split
def cameraautoforpictures(savedir='data/'):
"调用计算机摄像头来自动获取图片"
if not os.path.exists(savedir):
os.makedirs(savedir)
count=1
cap=cv2.videocapture(0)
width,height,w=640,480,360
cap.set(cv2.cap_prop_frame_width,width)
cap.set(cv2.cap_prop_frame_height,height)
crop_w_start=(width-w)//2
crop_h_start=(height-w)//2
print('width:',width)
print('height:',height)
while true:
ret,frame=cap.read()
frame=frame[crop_h_start:crop_h_start+w,crop_w_start:crop_w_start+w]
frame=cv2.flip(frame,1,dst=none)
cv2.imshow("capture",frame)
action=cv2.waitkey(1)&0xff
if action==ord('c'):
savedir=input(u"请输入新的存储目录:")
if not os.path.exists(savedir):
os.makedirs(savedir)
elif action==ord('p'):
cv2.imwrite("%s/%d.jpg" % (savedir,count),cv2.resize(frame,(224,224),interpolation=cv2.inter_area))
print(u"%s:%d张图片" % (savedir,count))
count+=1
if action==ord('q'):
break
cap.release()
cv2.destroyallwindows()
if __name__=='__main__':
cameraautoforpictures(savedir='data/guanxi/')通过上述代码,启动摄像头后借助键盘完成图片获取操作,其中按键C(change)表示设置一个存储样本照片的目录,按键p(photo)表示执行截图操作,按键q(quit)表示退出拍摄。运行后打开计算机本地摄像头,按下键盘中p会截取照片,并保存在data/guanxi/目录中。
六、深度学习和训练
处理样本照片,形成数据集,构建卷积网络模型并使用数据集进行训练,将训练后的模型保存为“.h5"模型文件,根据模型文件实现人脸识别。
1、原始图像预处理
原始图像预处理代码文件datahelper.py如下:
import os
import cv2
import time
def readallimg(path,*suffix):
"基于后缀读取文件"
try:
s=os.listdir(path)
resultarray=[]
for i in s :
if endwith(i,suffix):
document=os.path.join(path,i)
img=cv2.imread(document)
resultarray.append(img)
except ioerror:
print("error")
else:
print("读取成功")
return resultarray
def endwith(s,*endstring):
"对字符串的后续和标签进行匹配"
resultarray=map(s.endswith,endstring)
if true in resultarray:
return true
else:
return false
def readpicsaveface(sourcepath,objectpath,*suffix):
"图片标准化存储"
if not os.path.exists(objectpath):
os.makedirs(objectpath)
try:
resultarray=readallimg(sourcepath,*suffix)
count=1
face_cascade=cv2.cascadeclassifier('config/haarcascade_frontalface_alt.xml')
for i in resultarray:
if type(i)!=str:
gray=cv2.cvtcolor(i,cv2.color_bgr2gray)
faces=face_cascade.detectmultiscale(gray,1.1,5)
print(faces)
for (x,y,w,h) in faces:
liststr=[str(int(time.time()))]
filename=".join(liststr)"
f=cv2.resize(gray[y:(y+h),x:(x+w)],(200,200))
cv2.imwrite(objectpath+os.sep+'%s.jpg'%filename,f)
count+=1
except exception as e :
print("exception: ",e)
else:
print("read "+str(count-1)+' faces to destination'+objectpath)
if __name__=='__main__':
print('dataprocessing!!!')
readpicsaveface('data/guanxi/','dataset/chengsongtao/','jpg','jpg','png','png','tiff')代码首先检测是否存在标准化存储目录,如无则创建之,其次读入所有样本图片,使用opencv自带的人脸检测haarcascade_frontalface_alt.xml分类器获取人脸定位,并保存为大小为200*200大小的灰度图像。opencv-python的分类器在lib/site-page/data文件夹中,复制相应的分类器并保存在项目目录下的config文件夹中,其中cv2.cascadeclassifier.detectmultiscale() 函数各个参数及返回值的含义为:
image:待检测图像,通常为灰度图像。
scalefactor:表示在前后两次相继的扫描中,搜索窗口的缩放比例。
minneighbors:表示构成检测目标的相邻矩形的最小个数。默认情况下,该值为 3,意味着有 3 个以上的检测标记存在时,才认为人脸存在。如果希望提高检测的准确率,可以将该值设置得更大,但同时可能会让一些人脸无法被检测到。
flags:该参数通常被省略。在使用低版本 opencv(opencv 1.x 版本)时,它可能会被设置为 cv_haar_do_canny_pruning,表示使用 canny 边缘检测器来拒绝一些区域。
minsize:目标的最小尺寸,小于这个尺寸的目标将被忽略。
maxsize:目标的最大尺寸,大于这个尺寸的目标将被忽略。
objects:返回值,目标对象的矩形框向量组。
如果需要处理多人的样本图片,需要在__main__下添加多个对应的的处理目录,运行上述文件后,会在dataset目录下得到处理后照片。
2、数据集处理类
编写faceregnitionmodel.py文件,功能是通过深度学习和训练构建人脸识别模块,将训练后得到的模型文件face.h5保存在本地。类dataset是保存和读取格式化后的训练数据,具体代码如下:
class dataset(object):
def __init__(self,path):
"初始化"
self.num_classes=none
self.x_train=none
self.x_test=none
self.y_train=none
self.y_test=none
self.img_size=128
self.extract_data(path)
def read_file(self,path):
img_list=[]
label_list=[]
dir_counter=0
img_size=128
for child_dir in os.listdir(path):
child_path=os.path.join(path,child_dir)
for dir_image in os.listdir(child_path):
if dir_image.endswith('jpg'):
img=cv2.imread(os.path.join(child_path,dir_image))
resized_img=cv2.resize(img,(img_size,img_size))
recolored_img=cv2.cvtcolor(resized_img,cv2.color_bgr2gray)
img_list.append(recolored_img)
label_list.append(dir_counter)
dir_counter+=1
img_list=np.array(img_list)
return img_list,label_list,dir_counter
def extract_data(self,path):
imgs,labels,counter=self.read_file(path)
x_train,x_test,y_train,y_test=train_test_split(imgs,labels,test_size=0.2,random_state=random.randint(0,100))
x_train=x_train.reshape(x_train.shape[0],1,self.img_size,self.img_size)/255.0
x_test=x_test.reshape(x_test.shape[0],1,self.img_size,self.img_size)/255.0
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,num_classes=counter)
y_test=np_utils.to_categorical(y_test,num_classes=counter)
self.x_train=x_train
self.x_test=x_test
self.y_train=y_train
self.y_test=y_test
self.num_classes=counter
def check(self):
"校验"
print('num of dim :',self.x_test.ndim)
print('shape: ',self.x_test.shape)
print('size: ',self.x_test.size)
print('num of dim : ',self.x_train.ndim)
print('shape: ',self.x_train.shape)
print('size: ',self.x_train.size)
def read_name_list(self,path):
name_list=[]
for child_dir in os.listdir(path):
name_list.append(child_dir)
return name_list函数extract_data()抽取数据,使用机器学习sklearn中的函数train_test_split将原始数据集按照一定比例划分训练集和测试集对模型进行训练,通过reshape()将图片转换成128*128的灰度图像,通过函数astype()将图片转换为float32数据类型。其中train_test_split()函数原型如下所示:
train_test_split(train_data,train_target,test_size,random_state)各参数具体说明如下:
train_data: 表示被划分的样本特征集
train_target:表示划分的样本标签
test_size: 表示样本按比例划分,返回第的第一个参数值为train_data*test_size
random_state:表示随机种子,当为整数时,不管循环多少次x_train与第一次相同,其值不能为小数。
函数check(self)实现数据校验,打印输出图片的基本信息,函数read_file(self,path) 读取指定路径的图片信息。函数read_name_list(self,path)读取训练数据集。
3、模型构建与训练
类model创建一个基于cnn的人脸识别模型,开始构建数据模型并进行训练,具体代码如下:
class model(object):
"人脸识别模型"
file_path="face.h5"
image_size=128
def __init__(self):
self.model=none
def read_traindata(self,dataset):
self.dataset=dataset
def build_model(self):
self.model=sequential()
self.model.add(
convolution2d(
filters=32,
kernel_size=(5,5),
padding='same',
input_shape=self.dataset.x_train.shape[1:]
)
)
self.model.add(activation('relu'))
self.model.add(
maxpooling2d(
pool_size=(2,2),
strides=(2,2),
padding='same'
)
)
self.model.add(
convolution2d(
filters=64,
kernel_size=(5,5),
padding='same'
)
)
self.model.add(activation('relu'))
self.model.add(
maxpooling2d(
pool_size=(2,2),
strides=(2,2),
padding='same'
)
)
self.model.add(flatten())
self.model.add(dense(1024))
self.model.add(activation('relu'))
self.model.add(dense(self.dataset.num_classes))
self.model.add(activation('softmax'))
self.model.summary()
def train_model(self):
self.model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'] )
self.model.fit(self.dataset.x_train,self.dataset.y_train,epochs=10,batch_size=10)
def evaluate_model(self):
print('\ntesting--------------')
loss,accuracy=self.model.evaluate(self.dataset.x_test,self.dataset.y_test)
print('test loss: ', loss)
print('test accuracy: ',accuracy)
def save(self,file_path=file_path):
print('model saved finished!!!')
self.model.save(file_path)
def load(self,file_path=file_path):
print('model loaded successful!!!')
self.model=load_model(file_path)
def predict(self,img):
img=img.reshape((1,1,self.image_size,self.image_size))
img=img.astype('float32')
img=img/255.0
result=self.model.predict_proba(img)
max_index=np.argmax(result)
return max_index.result[0][max_index]类model创建一个基于cnn的人脸识别模型,其模型结构如下所示:
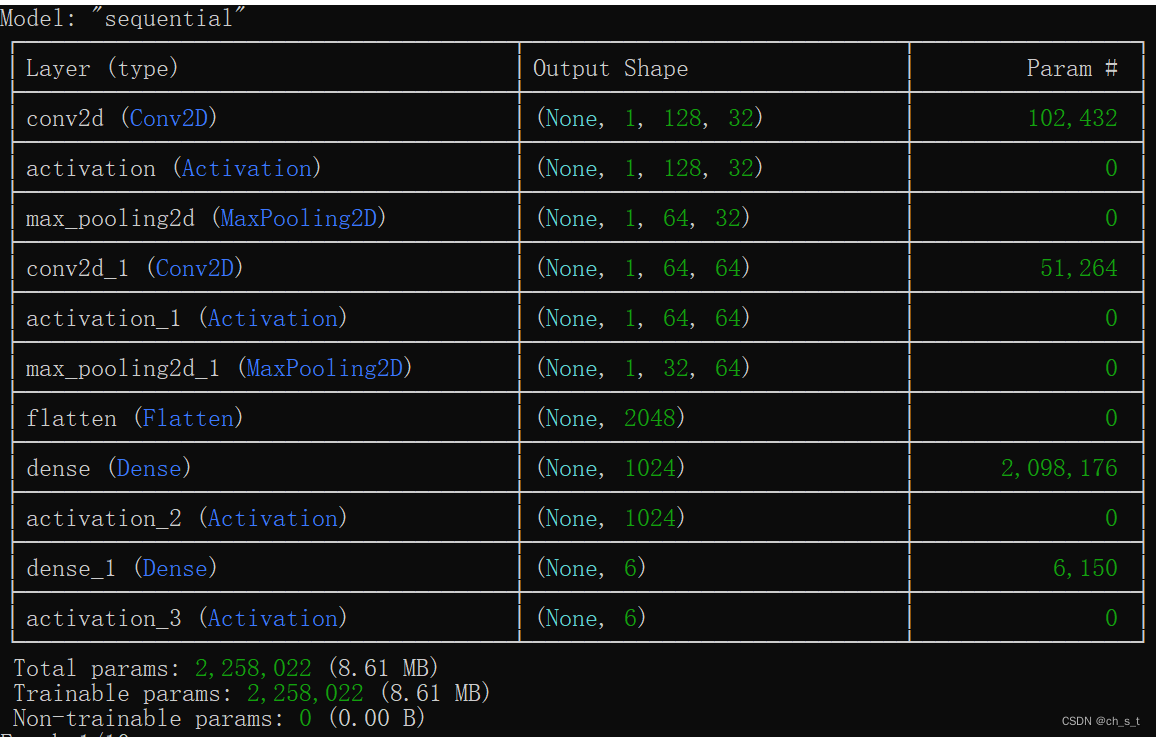
模型输入为1*128*128,训练、评估、保存效果如下所示:
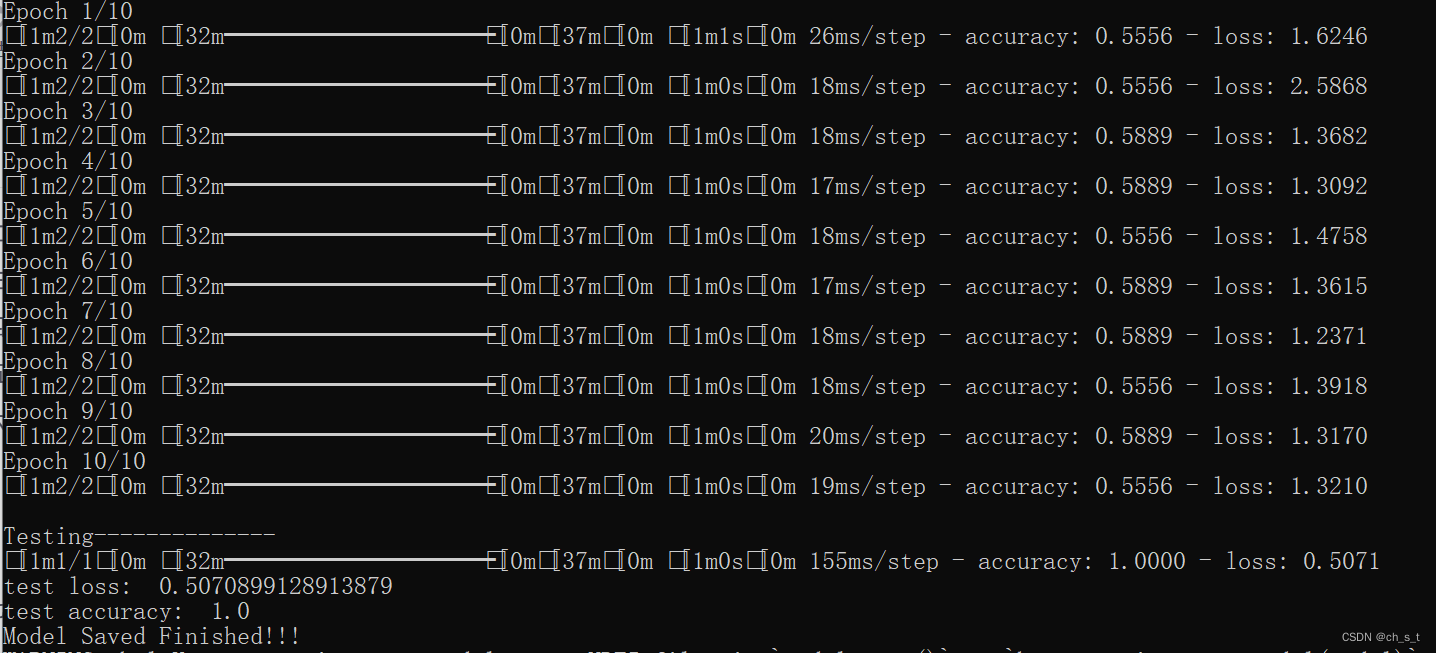
调用上面的函数,打印输出模型训练和评估结果,具体的代码如下:
if __name__=='__main__':
dataset=dataset('dataset/')
model=model()
model.read_traindata(dataset)
model.build_model()
model.train_model()
model.evaluate_model()
model.save()七、人脸识别
使用人工智能技术实现深度学习后,生成一个数据模型文件, 通过调用这个模型文件可以实现人脸识别功能,实例camerademp.py文件,通过opencv-python直接调用摄像头实现人脸识别功能,代码如下所示:
from faceregnitionmodel import model
threshold=0.7 #如果模型认为概率高于70%则显示为模型中已有的人物
def read_name_list(path):
"读取训练数据集"
name_list=[]
for child_dir in os.listdir(path):
name_list.append(child_dir)
return name_list
class camera_reader(object):
def __init__(self):
self.model=model()
self.model.load()
self.img_size=128
def build_camera(self):
"调用摄像头实现实时人脸识别"
name_list=read_name_list('dataset/')
cameracapture=cv2.videocapture(0)
face_cascade=cv2.cascadeclassifier('config/haarcascade_frontalface_alt.xml')
while true:
ret,frame=cameracapture.read()
gray=cv2.cvtcolor(frame,cv2.color_bgr2gray)
faces=face_cascade.detectmultiscale(gray,1.05,5)
for (x,y,w,h) in faces:
roi=gray[x:x+w,y:y+h]
roi=cv2.resize(roi,(self.img_size,self.img_size),interpolation=cv2.inter_linear)
label,prob=self.model.predict(roi)
if prob>threshold:
show_name=name_list[label]
else:
show_name="stranger"
cv2.puttext(frame,show_name,(x,y-20),cv2.font_hershey_simplex,1,255,2)
frame=cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow("capture",frame)
action=cv2.waitkey(1)&0xff
if action==ord('q'):
break
cameracapture.release()
cv2.destroyallwindows()
if __name__=='__main__':
camera=camera_reader()
camera.build_camera()具体的执行逻辑是先开启摄像头,再获取视频帧 ,最后是调用脸部检测分类器,获取脸部视频帧区域参数 ,调用模型进行识别并在原帧上进行标记。执行后会开启摄像头并识别人物且进行标记。



发表评论