fscrawler 是一个开源项目,可以帮助我们快速简便地将文件(如 pdfs、office 文档等)索引到 elasticsearch 中。
其作者 david pilato,有20年+工作经验。自 2013 年至今,一直在 elastic公司工作,可以算作 elastic 元老级员工。

博客地址:https://david.pilato.fr/
github:https://github.com/dadoonet
咱们之前的织网文档检索系统项目,也就是《一本书讲透elasticsearch》第18章项目,就推荐使用 fscrawler 作为文档爬虫。本文将深入详尽介绍 fscrawler 的功能、使用方法,并给出注意事项,确保大家都能够有效利用这一强大的文档爬虫工具。
一、fscrawler 功能介绍
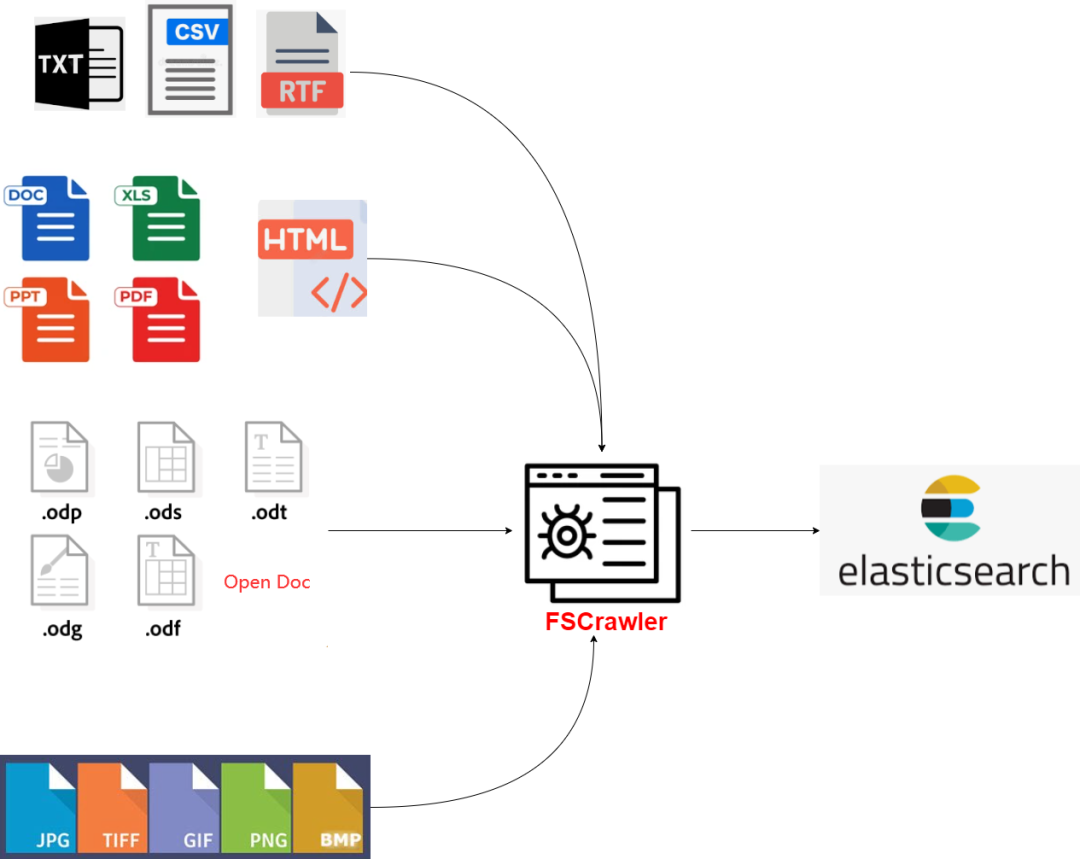
fscrawler 提供了一种高效的方法来自动化文件的索引过程,支持多种文件格式,并具备以下核心功能:
多种文件支持:能够处理包括但不限于pdf、microsoft office文档、openoffice文档等多种格式。
文本提取:从上述文件中提取文本,利用 ocr 技术处理图像和扫描的文档。
元数据提取:自动提取文件的元数据,如作者、标题、关键词等。
更新和同步:监视文件夹变化,自动更新索引以反映新增、修改或删除的文件。
安全:支持使用用户名和密码对 elasticsearch 进行安全连接。
扩展性:可以配置为处理大规模的数据集。
二、fscrawler 下载步骤指南
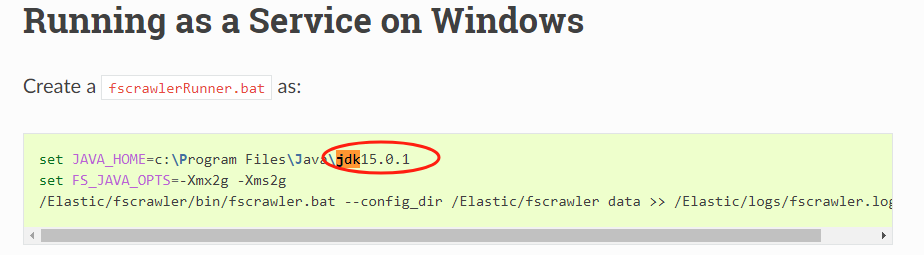
首先,确保我们已安装 java 8 或更高版本,因为 fscrawler 是用 java 开发的。
官方文档举例的时候,jdk 版本是15.0.1。所以,版本不建议过低。
接下来,从 github 上的 fscrawler 项目 下载最新的发行版。
fscrawler github地址:https://github.com/dadoonet/fscrawler
这里有个版本映射表,咱们需要结合自己 elasticsearch 集群版本进行选型。如下图所示,elasticsearch 6.x、7.x、8.x 都推荐使用 fscrawler 的2.10-snapshot 版本。
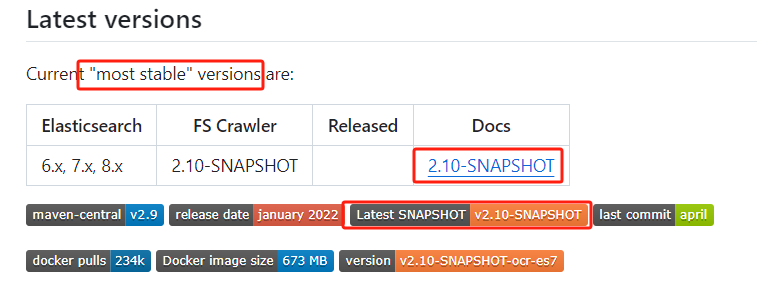
下载步骤建议如下:
2.1 第一步:点击上图的“last snapshot v2.10-snapshot”。
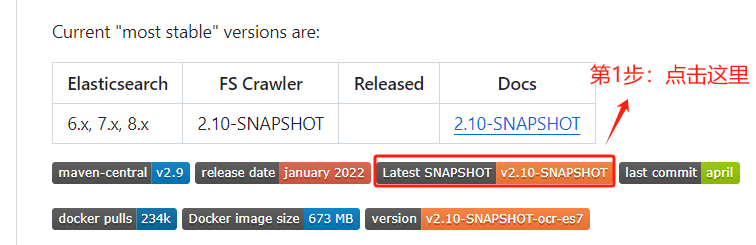
2.2 第二步:点击“2.10-snapshot”。
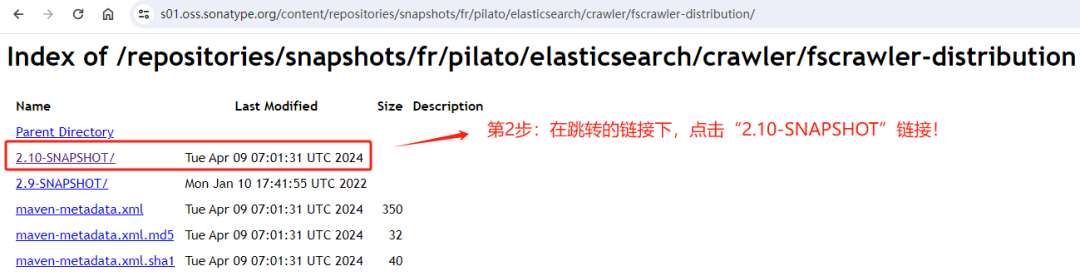
2.3 第3步,找到适合自己版本的安装包。
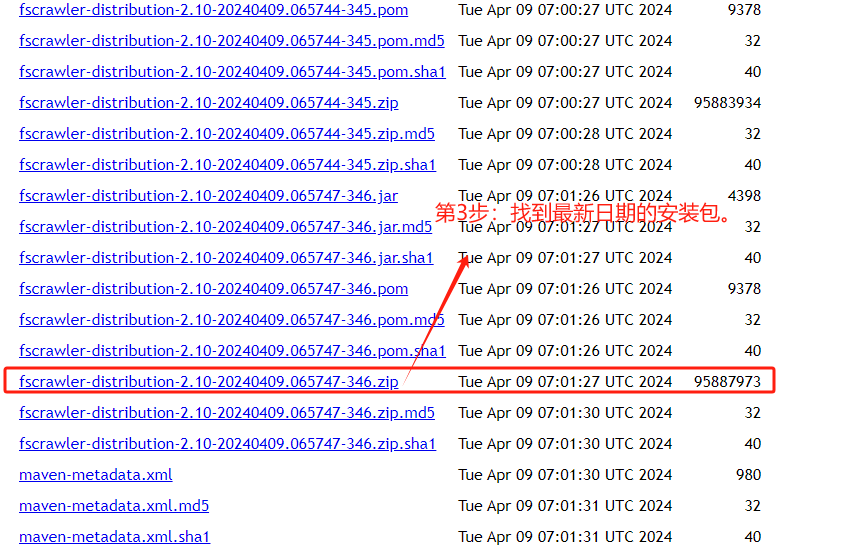
这里其实有个小细节,默认最新版本的安装包在页面的最后面,需要不断地下拉到底才能找到。
如果 elasticsearch 8.x,选型了2022年左右的版本,后续的启动环节会报错!
所以,选型版本真的非常重要!
下载成功标示如下:

三、fscrawler 安装指南
安装很简单,只需要解压下载的文件即可。
将安装包下载或者远程拷贝到 linux 服务器,其他部署方式如docker等,参见官方文档即可,原理一致,不再赘述。
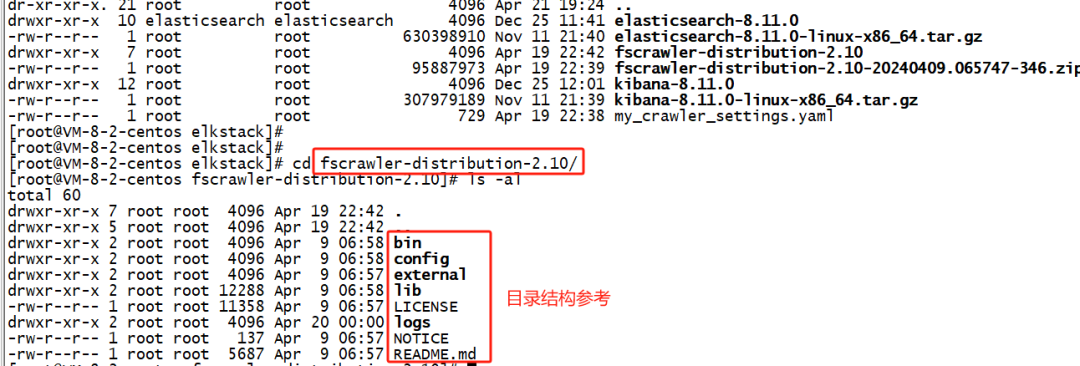
3.1 步骤1:解压 fscrawler
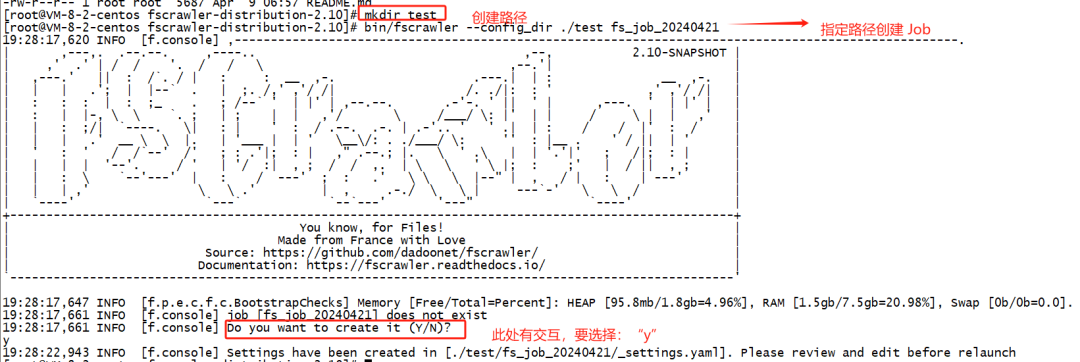
3.2 步骤2:启动 fscrawler
为了方便咱们在部署路径本地修改和维护配置文件,我们要指定一个本地路径,同时需要写上一个 job 名称。
具体命令行参考如下:
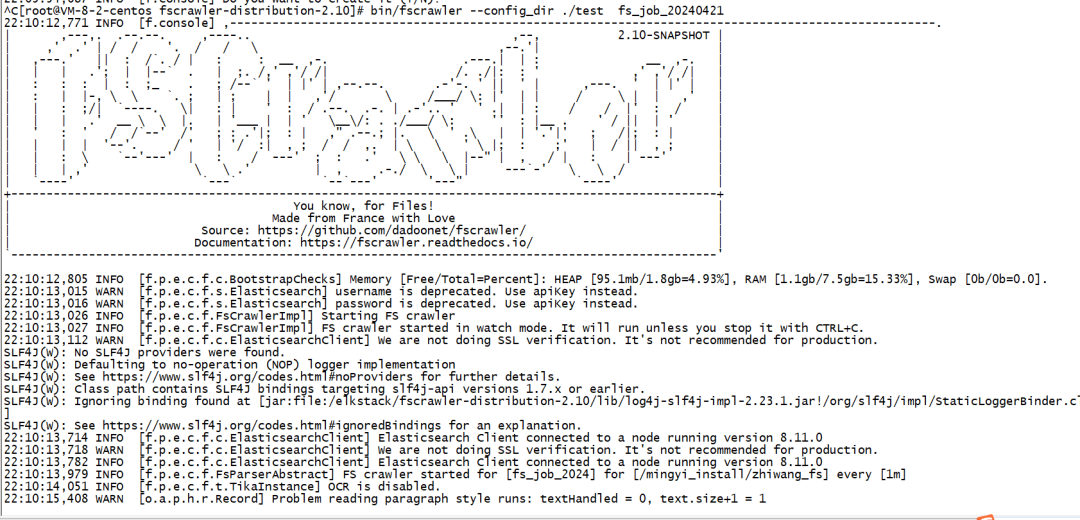
mkdir test
bin/fscrawler --config_dir ./test fs_job_20240421执行截图参考如下:
3.3 步骤3:修改配置文件
经过步骤 2 后,test 路径下会创建了名为:“fs_job_20240421”的 job 任务,目录结构如下图所示。

我们先解读一下_settings.yaml 各个字段的含义,然后再说明针对 8.x 版本如何修改。
配置内容主要包括 elasticsearch 连接信息、文件夹路径、扫描间隔等,如下表格所示。
| 字段名 | 含义 | 使用范例 |
|---|---|---|
name | fscrawler 任务的名称,用于区分不同的索引任务 | "name": "fs_job_20240421" |
fs.url | 需要被索引的文件或目录的路径 | "url": "/tmp/es" |
fs.update_rate | 文件系统检查更新的频率,如15分钟检查一次 | "update_rate": "15m" |
fs.excludes | 定义哪些文件应该被排除在外的文件名模式列表(支持通配符) | "excludes": ["*/~*"] |
fs.json_support | 布尔值,决定是否解析文件中的json内容 | "json_support": false |
fs.filename_as_id | 布尔值,是否使用文件名作为elasticsearch文档id | "filename_as_id": false |
fs.add_filesize | 布尔值,决定是否将文件大小信息添加到索引中 | "add_filesize": true" |
fs.remove_deleted | 布尔值,决定是否从索引中删除已经在文件系统中删除的文件 | "remove_deleted": true" |
fs.add_as_inner_object | 布尔值,是否将文件信息作为内部对象添加 | "add_as_inner_object": false" |
fs.store_source | 布尔值,是否存储原始文件的内容 | "store_source": false" |
fs.index_content | 布尔值,决定是否索引文件内容 | "index_content": true" |
fs.attributes_support | 布尔值,是否索引文件的属性(如权限等信息) | "attributes_support": false" |
fs.raw_metadata | 布尔值,是否索引文件的原始元数据 | "raw_metadata": false" |
fs.xml_support | 布尔值,是否解析和索引xml文件 | "xml_support": false" |
fs.index_folders | 布尔值,是否索引目录结构 | "index_folders": true" |
fs.lang_detect | 布尔值,是否进行语言检测并索引 | "lang_detect": false" |
fs.continue_on_error | 布尔值,是否在遇到错误时继续执行 | "continue_on_error": false" |
fs.ocr.language | ocr处理的语言 | "language": "eng" |
fs.ocr.enabled | 布尔值,是否启用ocr功能 | "enabled": true" |
fs.ocr.pdf_strategy | ocr处理pdf文件的策略 | "pdf_strategy": "ocr_and_text" |
fs.follow_symlinks | 布尔值,是否跟随符号链接 | "follow_symlinks": false" |
elasticsearch.nodes.url | elasticsearch节点的完整url | "url": "https://127.0.0.1:9200" |
elasticsearch.bulk_size | 在单个批量请求中向elasticsearch发送的最大文档数量 | "bulk_size": 100" |
elasticsearch.flush_interval | 批量操作的刷新间隔,确保数据定期被写入elasticsearch | "flush_interval": "5s" |
elasticsearch.byte_size | 指定批量请求的最大字节大小 | "byte_size": "10mb" |
elasticsearch.ssl_verification | 布尔值 |
|一个基本的默认的配置示例如下:
---
name: "fs_job_20240421"
fs:
url: "/tmp/es"
update_rate: "15m"
excludes:
- "*/~*"
json_support: false
filename_as_id: false
add_filesize: true
remove_deleted: true
add_as_inner_object: false
store_source: false
index_content: true
attributes_support: false
raw_metadata: false
xml_support: false
index_folders: true
lang_detect: false
continue_on_error: false
ocr:
language: "eng"
enabled: true
pdf_strategy: "ocr_and_text"
follow_symlinks: false
elasticsearch:
nodes:
- url: "https://127.0.0.1:9200"
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: true
push_templates: true我修改后的正确的可执行的配置如下:
---
name: "fs_job_2024"
fs:
url: "/mingyi_install/zhiwang_fs"
update_rate: "1m"
excludes:
- "*/~*"
json_support: false
filename_as_id: false
add_filesize: true
remove_deleted: true
add_as_inner_object: false
store_source: false
index_content: true
attributes_support: false
raw_metadata: false
xml_support: false
index_folders: true
lang_detect: false
continue_on_error: false
ocr:
language: "eng"
enabled: true
pdf_strategy: "ocr_and_text"
follow_symlinks: false
elasticsearch:
nodes:
- url: "https://127.0.0.1:9200"
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: false
username: elastic
password: changeme极简解读一下:
fs 相关的都是:文件源头相关配置,比如:url 代表的是文件存储的路径。
而 elasticsearch 相关的都是:“目的端”,代表 elasticsearch 集群相关配置。
在 elasticsearch 部分如果不设置 index 相关,则同步到elasticsearch 默认索引名为name下的 "fs_job_2024"名称。
更多细节配置参考:
https://fscrawler.readthedocs.io/en/latest/admin/fs/index.html#example-job-file-specification
8.x 版本安全需要设置用户名和密码,需要 https 通信。
3.4 步骤 4: 运行 fscrawler
在配置文件设置完毕后,使用命令行启动 fscrawler,命令如下:
bin/fscrawler --config_dir ./test fs_job_20240421再次执行,就能将本地文件写入 elasticsearch。
在 kibana dev-tool 中,我们能看到两个索引。
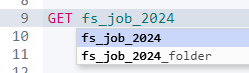
其一,索引名:fs_job_2024 就是 _settings.yaml 配置文件中的最开头的 name。
其存储数据如下,基本上文件想的信息,比如:文件内容、文件基础数据(meta)、文件创建/修改时间、扩展名、路径等全部都包含了。
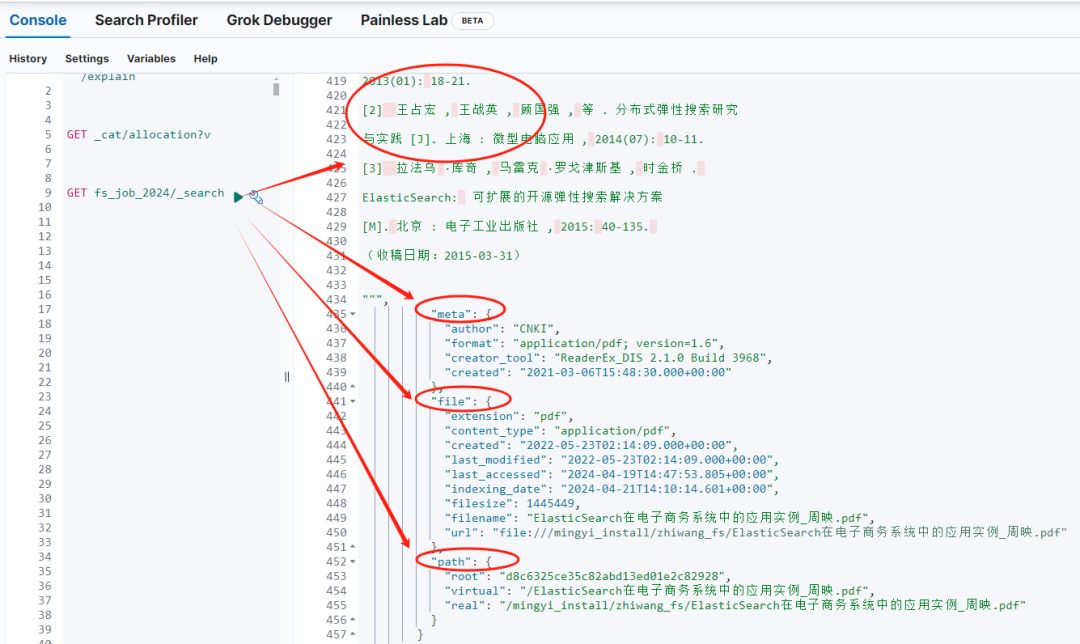
其二,索引名:fs_job_2024_folder 是基于咱们定义的 name 自动生成和创建的。
存储的是配置的文件路径相关的基础信息。
3.5 步骤 5: 按业务需求修改 mapping,重新导入数据。
mapping 映射是默认生成的。
我们朴素的认知:倒排索引的不可变导致我们重新修改 mapping 后必须重新导入数据。
但,默认的mapping可能达不到业务的预期,所以,咱们必须得修改。
究竟如何改呢?——这个问题我反复验证几个不同方案超过三个小时,最后总结出如下核心步骤。
第一步:先同步讲数据写入 elasticsearch
同步骤 3.4 所示。
bin/fscrawler --config_dir ./test fs_job_20240421这个时候,如官方文档所述:
https://fscrawler.readthedocs.io/en/latest/admin/fs/elasticsearch.html#mappings
在 elasticsearch 集群中会多了如下的索引模版和组件模版。
| 模版类型 | 模版名称 |
|---|---|
| 索引模版 | fscrawler_docs_fs_job_2024 |
| 索引模版 | fscrawler_folders_fs_job_2024_folder |
| 索引模版 | fscrawler_folders_fs_job_folder |
| 索引模版 | fscrawler_docs_fs_job |
| 组件模版 | fscrawler_settings_total_fields |
| 组件模版 | fscrawler_mapping_file |
| 组件模版 | fscrawler_mapping_attributes |
| 组件模版 | fscrawler_mapping_path |
| 组件模版 | fscrawler_alias |
| 组件模版 | fscrawler_mapping_meta |
| 组件模版 | fscrawler_settings_shards |
| 组件模版 | fscrawler_mapping_content |
| 组件模版 | fscrawler_mapping_attachment |
如下指令我和可以看出,一个索引模版由多个组件模版组成。这是 elasticsearch 模版的最新格式。

如上表格内容都是 fscrawler 在导入环节自动生成的。
第二步:禁用 fscrawler 的自动模板推送
在我们之前的 fscrawler 配置文件 _settings.yaml 中,设置 push_templates 为 false。
该设置阻止 fscrawler 自动创建和更新 elasticsearch 的索引模板。
配置示例如下:
name: "fs_job_2024"
elasticsearch:
push_templates: false第三步:按需修改组件模版的部分参数
在禁用自动模板推送后,我们需要手动更新或创建所需的 component template,以包含中文分词器。
例如,如果我们想对内容字段使用中文分词器,我们可以更新 fscrawler_mapping_content 模板如下:
put _component_template/fscrawler_mapping_content
{
"template": {
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
######省略其他定制需求########第四步: 删除现有的索引
如果在 elasticsearch 中已经存在由 fscrawler 创建的索引,我们需要删除这些索引,因为索引的 mapping 一旦创建后不能直接修改(只能增加字段)。删除索引的命令如下:
delete fs_job_2024_folder
delete fs_job_2024请注意,这将删除所有相关数据,因此请确保我们已经备份了任何重要数据。
第五步: 重启 fscrawler
在更新了 component template 并删除了旧索引后,重新启动 fscrawler。
现在,fscrawler 将使用我们更新的 template 来创建新的索引,而这次新的索引将包含我们设置的中文分词器。
bin/fscrawler --config_dir ./test fs_job_20240421第六步:验证 mapping
验证新创建的索引是否使用了正确的 mapping 设置。我们可以使用以下命令来查看索引的 mapping:
get fs_job_2024/_mapping确保返回的信息中包含了我们配置的中文分词器。
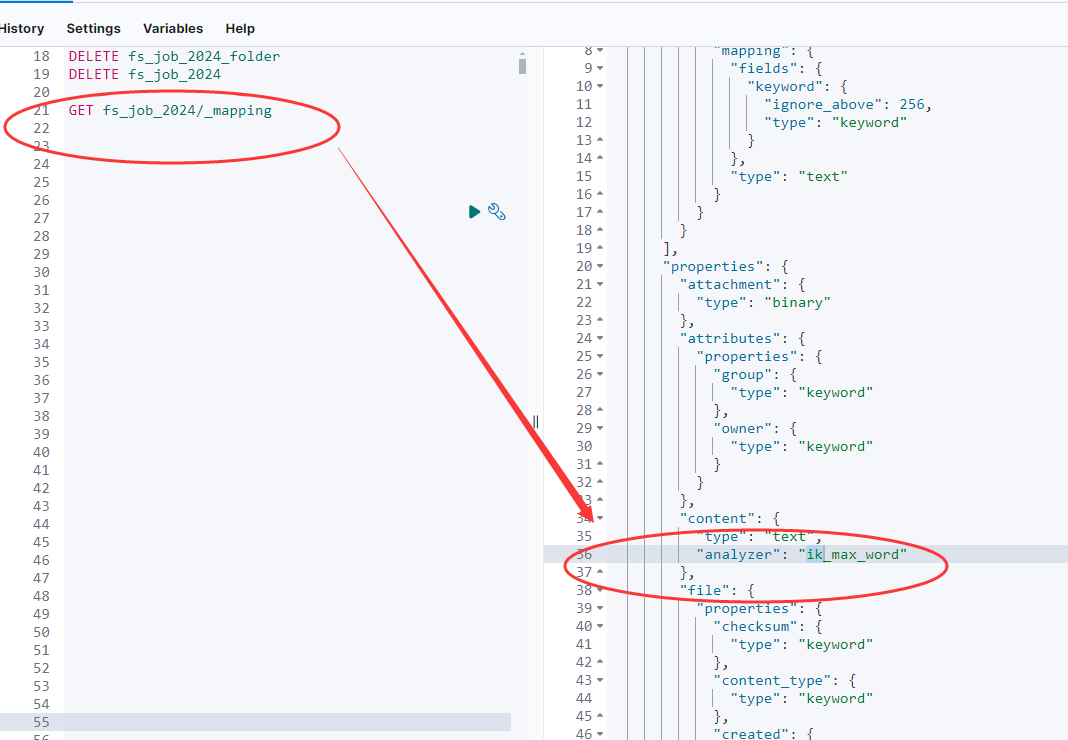
通过以上步骤,我们可以确保 fscrawler 不会覆盖我们自定义的 mapping,同时能够使用中文分词器来索引文档内容。
这样配置后,fscrawler 在爬取文档到 elasticsearch 的过程中,就会使用咱们刚才指定的中文分词器进行文本分析。
四、fscrawler 常见使用错误与解决方案
在使用 fscrawler 进行文件索引时,我们可能会遇到各种问题。本小节将列出一些常见的错误以及相应的解决方案,帮助我们更有效地使用 fscrawler。
4.1 问题一:索引大文件和小文件时出现错误
问题描述:当索引包含大小差异很大的文件时,可能会遇到“http entity too large”错误 。
解决方案:此错误通常由 elasticsearch 的 http 请求体大小限制引起。我们可以通过增加服务器的接收限制来解决这个问题:
1.在 elasticsearch 的配置文件 elasticsearch.yml 中,设置 http.max_content_length 的值更高(例如 200mb,缺省100mb)。
2.重启 elasticsearch 服务以使配置生效。
3.重新启动 fscrawler 并再次尝试索引操作。
http.max_content_length: 200mb参见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html
4.2 问题二:索引文件夹未在最新版本中创建
问题描述:在使用最新版本的 fscrawler 时,文件夹索引没有被创建 。
解决方案:这可能是由于 fscrawler 的配置问题或是 elasticsearch 版本兼容性问题。尝试以下方法:
1.检查 ~/.fscrawler/{job_name}/_settings.json 文件中的 fs.index_folders 设置,确保其值为 true。
2.确认我们的 elasticsearch 版本与 fscrawler 的版本兼容。在一些情况下,fscrawler 的新版本可能需要更新的 elasticsearch 版本。
记得在进行任何配置修改或软件升级后,都应该重启相关服务,以确保所有的更改能够正确应用。
4.3 问题三:反复闪退问题
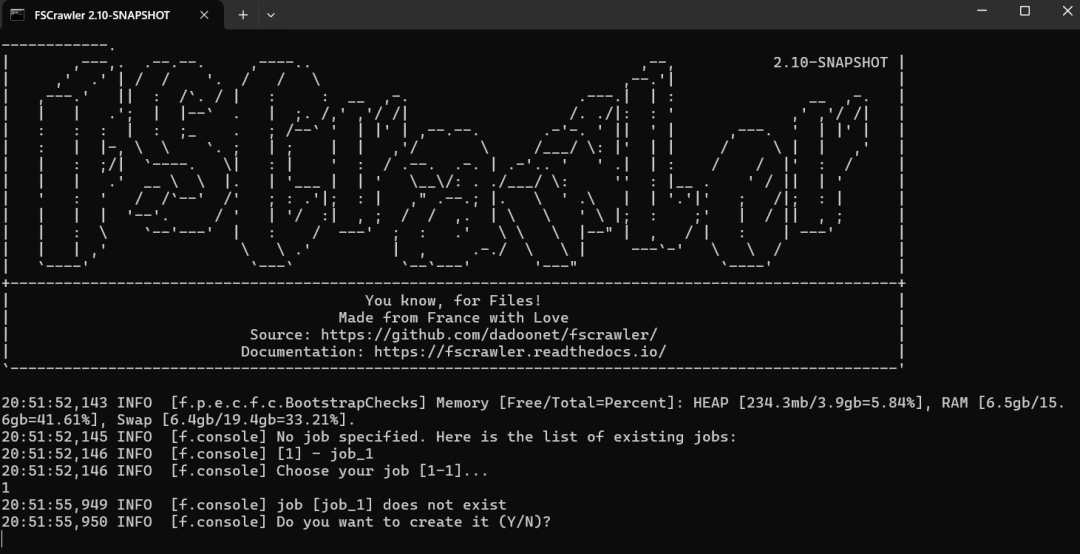
每次都要求重新创建文件,即便已经反复确认创建成功了。这个我花了3个小时左右验证,是版本问题,需要咱们选择 2.10 最新日期的版本!
4.4 问题四:python flask 连接报错——security_exception
elasticsearch.exceptions.authenticationexception: authenticationexception(401, 'security_exception', 'missing authentication credentials for rest request [/fs_job/_search]')python 版本问题,python 要3.10 以上!负责会报如上错误。
五、注意事项及小结
安全配置:在连接到 elasticsearch 时,如果我们的集群配置了安全认证,确保我们的配置文件中填写了正确的用户名和密码。
ocr 设置:如果需要从图像或pdf文档中提取文本,请确保我们的系统上安装了 tesseract ocr,并正确配置在 fscrawler 设置中。
性能优化:对于大数据量的文件处理,考虑适当增加 jvm 的内存分配,以及使用 ssd 硬盘来提升处理速度。
错误处理:fscrawler 会在控制台输出运行日志,如果遇到问题,日志是解决问题的第一手资料。

通过上述详细指南,我们应该能够有效地部署和使用 fscrawler,使文档管理和检索过程自动化、高效化。希望这份指南对你也有所帮助!
此部分也可以作为《一本书讲透 elasticsearch》第18章的延伸讲解。
如果有任何问题,欢迎留言交流。

更短时间更快习得更多干货!
和全球 近2000+ elastic 爱好者一起精进!
elastic6.cn——elasticstack进阶助手

比同事抢先一步学习进阶干货!
发表评论