git相信提到这个词大部分学开发的都不陌生,今天我们来分四部分去理解git的原理和实用技巧。
1、git是怎么存储内容的?(数据结构)
2、git怎么通过不同命令操作底层数据存储变更记录的?(可视化)
3、git怎么合并两个分支?(冲突发生的原因)
4、git的实用技巧和实例
一、git是怎么存储内容的
git object分为三种 blob、tree、commit 三者都是一旦提交不可修改的。

用下面的图来举例,看看三种object的数据结构:
其中blob的内容就是111和222
tree的内容是文件的权限(100644)、文件名(a.txt)

commit的内容是tree(当前commit对应的项目快照)、author作者的信息和提交的时间、committer最后提交的信息。

下面是三者关系图:
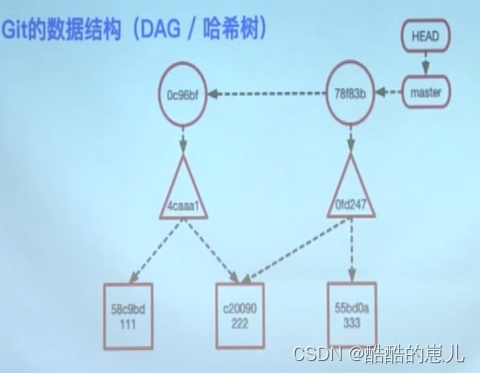
q:为什么要把文件名放在tree object中呢?
a :可以节省空间,提高复用性,如果一个一万行代码的文件改了一下文件名,存在blob中就需要整体都重新复制一遍了,放在tree中只需要复制tree就可以。
q:git如何保障数据不被篡改?
a:当我们修改数据的时候,git整个哈希树都会发生改变,git是一个分布式的系统,所以一旦修改文件内容,大家都会知道。
二、git命令可视化
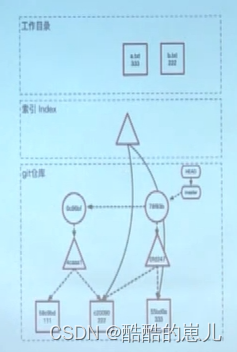
git的三个分区
工作目录:操作系统上的文件,代码开发编译工作都在这里完成。
索引:一个暂存区,下一次commit的时候会被提交到仓库
git仓库:由git object记录着每一次提交的快照以及链式结构记录的提交变更历史。
下面先看git add操作
首先索引中的tree object指向内容为111和222的两个文件,文件名分别为a.txt,b.txt。
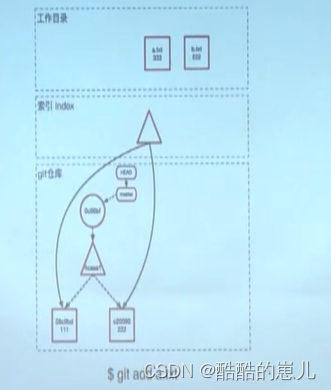
执行git add操作 在git仓库中生成内容为333的blob

然后更新索引 指向更新后的a.txt(内容为333)的文件
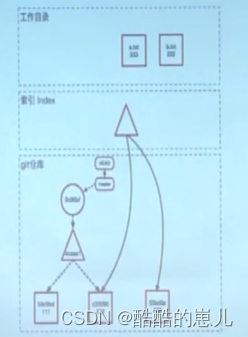
git commit操作
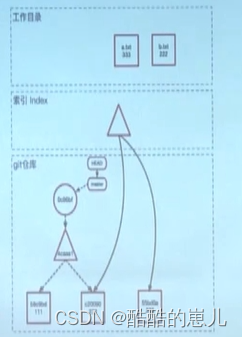
执行git commit操作,将索引中的内容固化下来,在git仓库中生成tree object,然后生成一个新的commit节点,最后将master分支的指针指向最新的commit object。
q:每次commit,git存储的是全新的文件快照还是文件的变更部分?
a:是全新的文件快照
q:那一万行代码改一行也要都存一下,为是什么这么做呢?
a:拿空间换速度,如果要checkout一个节点,那就需要从第一个节点开始递归,速度会比较慢。git还有一套机制(git gc)来保证当空间太大或者需要网络请求的时候会压缩成pack(存储变更部分)。
git checkout操作的流程是什么样呢? 大家可以自己画着试试看,流程如下:
1、将head指针指向要checkout的commit分支
2、将tree object更新到索引
3、将索引所指向的blob object替换到工作目录中
三、git怎么合并两个分支?
策略使用方法 git merge -s[策略名字]
git merge策略
fast-forward、recursive、ours、theirs、octopus
这里我们介绍重点的recursive策略
找到最短路径的公共祖先节点,三向合并,下图是最简单的例子

公共祖先节点为a,那么三向合并的节点为a、a、b,b与他们不同,所以合并后的结果为b且没有冲突。
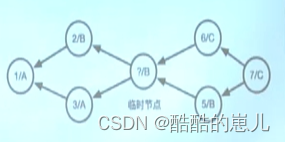
下面来看一种复杂的三向合并
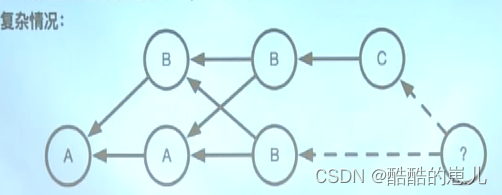
我们可以找到两个最短公共节点,a和b,我们发现当a为祖先节点时,a、b、c进行三向合并,会产生冲突,当b为祖先节点时,b、b、c进行三向合并,产生c,便是正确的合并。
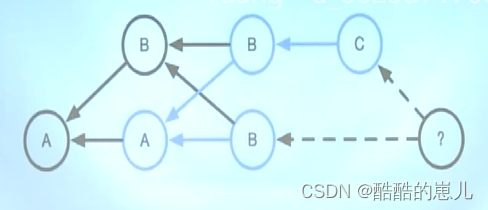
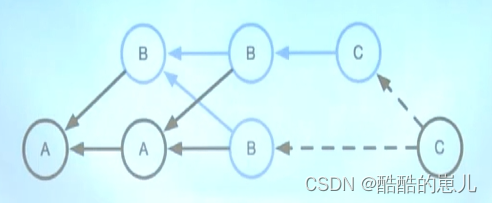
那计算机是如何判断选哪个节点的呢?
要保证冲突尽量少, 当有多个最短公共祖先的时候,计算机继续向前递归找到多个公共祖先的公共祖先(其实是一样的操作),然后进行合并,本图就是找到a为a、b的最短公共祖先进行三向合并得到b,b作为临时节点与b、c进行三向合并生成c,就成功了,如果这种方法也存在冲突,那就需要我们手动去选择保留哪个了。
四、git的实用技巧和实例
这个最好自己上手去做一下试试看,这里给大家一个链接是腾讯的,本文的内容也是源于对该视频的记录和总结,希望对大家有帮助。
下一篇文章会跟大家分享redis原理,希望大家喜欢的关注一下哈🙂



发表评论