
使用 go-elasticsearch 请求示例
你可以通过参考go 官方文档找到简单的示例,所以我认为先看看这个是个好主意。
连接客户端有两种方式,如下图。
至于两者的特点,typedclient有类型,更容易编写,但文档较少。另外,批量索引不支持typedclient。由于普通客户端都是基于json的,所以我觉得从文档转换到代码还是比较容易的。
我的建议基本上是使用 typedclient!
虽然文档很稀疏,但它是基于规律性的类型化的,所以你越习惯它(特别是当涉及到有很多变化的东西时,比如查询),从 json 转换为类型化代码就越容易。
func main() {
// client
es, err := elasticsearch.newclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
// typed client
es, err := elasticsearch.newtypedclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
}index create/delete
关于索引创建,go官方文档中有一个示例,所以我简单介绍一下。
func main() {
es, err := elasticsearch.newtypedclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
ignoreabove := 256
keywordproperty := types.newkeywordproperty()
keywordproperty.ignoreabove = &ignoreabove
dateproperty := types.newdateproperty()
format := "yyyy/mm/dd||yyyy/mm||mm/dd||yyyy||mm||dd"
dateproperty.format = &format
// index作成
_, err = es.indices.create("sample_index").request(&create.request{
settings: &types.indexsettings{
indexsettings: map[string]json.rawmessage{
// 設定項目
// bulk index里面的数据更新感觉。如果不需要频繁更新,设置得更长会提高性能。
"refresh_interval": json.rawmessage(`"30s"`),
// 可取得的最大件数的上限
"max_result_window": json.rawmessage(`"1000000"`),
},
},
mappings: &types.typemapping{
properties: map[string]types.property{
// 映射的定义
"name": keywordproperty,
"age": types.newintegernumberproperty(),
"is_checked": types.newbooleanproperty(),
"created_at": dateproperty,
},
},
}).do(context.todo())
if err != nil {
log.fatalf("error creating the client: %s", err)
}
// index削除
_, err = es.indices.delete("sample_index").do(context.todo())
if err != nil {
log.fatalf("error deleting the client: %s", err)
}
}bulk index
批量索引代码基于go-elasticsearch 示例。
var jsonitier = jsoniter.configcompatiblewithstandardlibrary
type sampleindexdata struct {
id int64 `json:"id"`
name string `json:"name"`
age int `json:"age"`
ischecked bool `json:"is_checked"`
createdat string `json:"created_at"`
}
func main() {
es, err := elasticsearch.newclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
esref, err := elasticsearch.newtypedclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
datas := []*sampleindexdata{}
for i := 1; i <= 100; i++ {
datas = append(datas, &sampleindexdata{
id: int64(i),
name: fmt.sprintf("name_%d", i),
age: 20,
ischecked: true,
createdat: time.date(2021, 1, 15, 17, 28, 55, 0, jst).format("2006/01/02"),
})
}
bi, err := esutil.newbulkindexer(esutil.bulkindexerconfig{
index: "sample_index", // the default index name
client: es, // the elasticsearch client
numworkers: 1, // the number of worker goroutines
})
if err != nil {
log.fatalf("error creating the indexer: %s", err)
}
for _, a := range datas {
data, err := jsonitier.marshal(a)
if err != nil {
log.fatalf("cannot encode article %d: %s", a.id, err)
}
err = bi.add(
context.background(),
esutil.bulkindexeritem{
// delete时,action为“delete”,body为nil。
action: "index",
documentid: strconv.itoa(int(a.id)),
body: bytes.newreader(data),
onsuccess: func(ctx context.context, item esutil.bulkindexeritem, res esutil.bulkindexerresponseitem) {
fmt.println("success")
},
onfailure: func(ctx context.context, item esutil.bulkindexeritem, res esutil.bulkindexerresponseitem, err error) {
fmt.println("failure")
},
},
)
if err != nil {
log.fatalf("unexpected error: %s", err)
}
}
if err := bi.close(context.background()); err != nil {
log.fatalf("unexpected error: %s", err)
}
// 取决于refresh_interval的值,但是如果感觉很长,在所有的index结束后刷新,数据会立即反映出来,所以很好
_, err = esref.indices.refresh().index("sample_index").do(context.background())
if err != nil {
log.fatalf("error getting response: %s", err)
}
}query
基本查询如下所示:
go 的官方文档仅包含搜索 api 的简单示例。您基本上必须自己组装上述详细信息。就我而言,我正在检查querydsl页面上的查询并在包中复制我需要的内容。
var jst = time.fixedzone("asia/tokyo", 9*60*60)
var formattime = "2006-01-02t15:04:05.999999-07:00"
func main() {
es, err := elasticsearch.newtypedclient(elasticsearch.config{
addresses: []string{"http://localhost:9200"},
})
if err != nil {
log.fatalf("error creating the client: %s", err)
}
agelte := 40.0
ageltec := (*types.float64)(&agelte)
agegte := 13.0
agegtec := (*types.float64)(&agegte)
pagestart := 0
size := 50
req := &search.request{
// 查询
query: &types.query{
bool: &types.boolquery{
// 过滤器(过滤器)
filter: []types.query{
// 范围过滤器(过滤器)
{
range: map[string]types.rangequery{
"age": types.numberrangequery{
gte: agegtec,
lte: ageltec,
},
},
},
// 术语过滤器(过滤器)
{
term: map[string]types.termquery{
"is_checked": {value: true},
},
},
},
},
},
// 页面的起点
from: &pagestart,
// 返回的数量
size: &size,
// 排序指定
sort: []types.sortcombinations{
types.sortoptions{sortoptions: map[string]types.fieldsort{
"created_at": {order: &sortorder.desc},
}},
},
}
res, err := es.search().
index("sample_index").
request(req).
do(context.todo())
if err != nil {
log.fatalf("error query: %s", err)
}
// total
fmt.println(res.hits.total)
ds := []*sampleindexdata{}
for _, hit := range res.hits.hits {
var d *sampleindexdata
if err := json.unmarshal(hit.source_, &d); err != nil {
log.fatalf("error decoding: %s", err)
}
ds = append(ds, d)
}
// 拿出数据.
fmt.println(ds)
}此外,您还可以使用 kibana 中的 devtools 轻松检查详细错误,以查看查询是否正确。为了调整查询以使其正确,最好使用一个围绕此问题的工具(在代码中,它也包含在 err 中,所以也在那里检查它。我可以)。
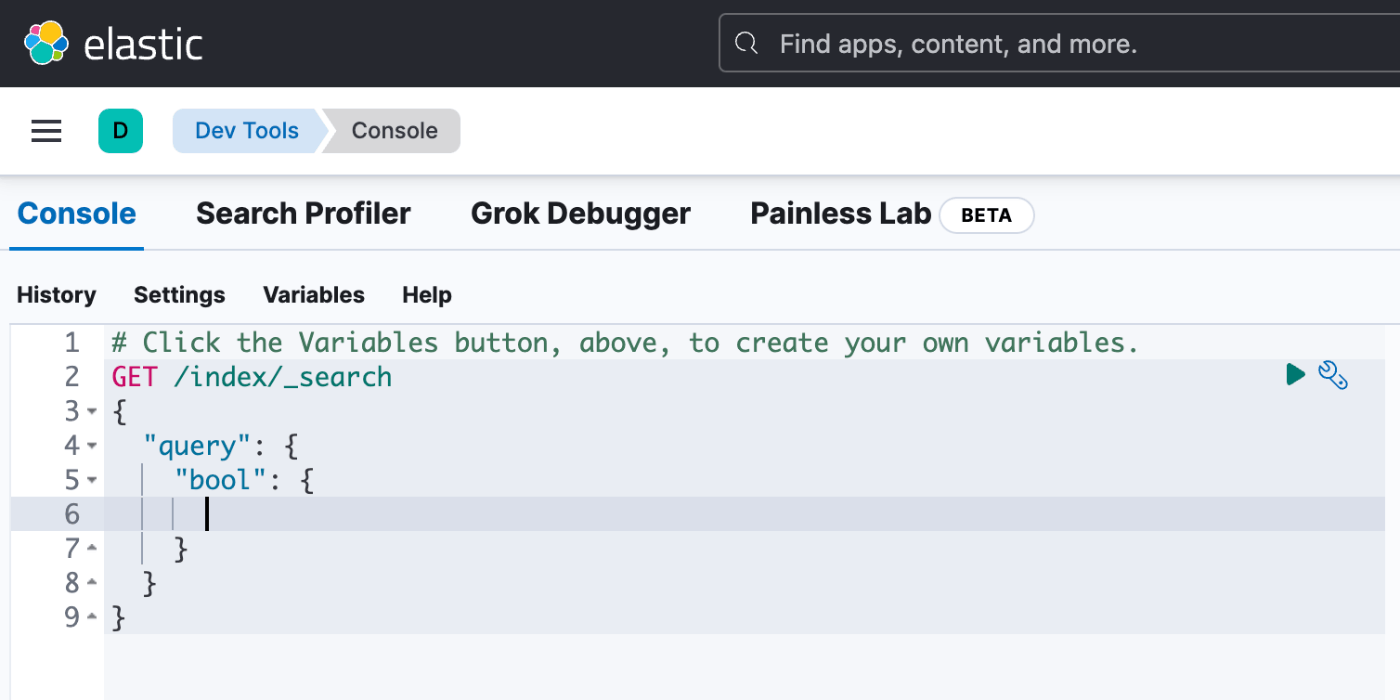
综上所述
我已经简要描述了基本的索引创建/删除、使用 bulk api 的批量处理以及如何在 go-elasticsearch 中使用 searchapi 编写搜索查询。
就我个人而言,我发现很容易迷失在 elasticsearch 的文档中,当我尝试做一些详细的事情时,我最终会输入大量代码并进行反复试验,因此需要花费大量时间来理解整体概念并编写代码。




发表评论