1.解决pdf含javasprct脚本动作,这里是验证pdf内部事件。相关pdf文件下载:
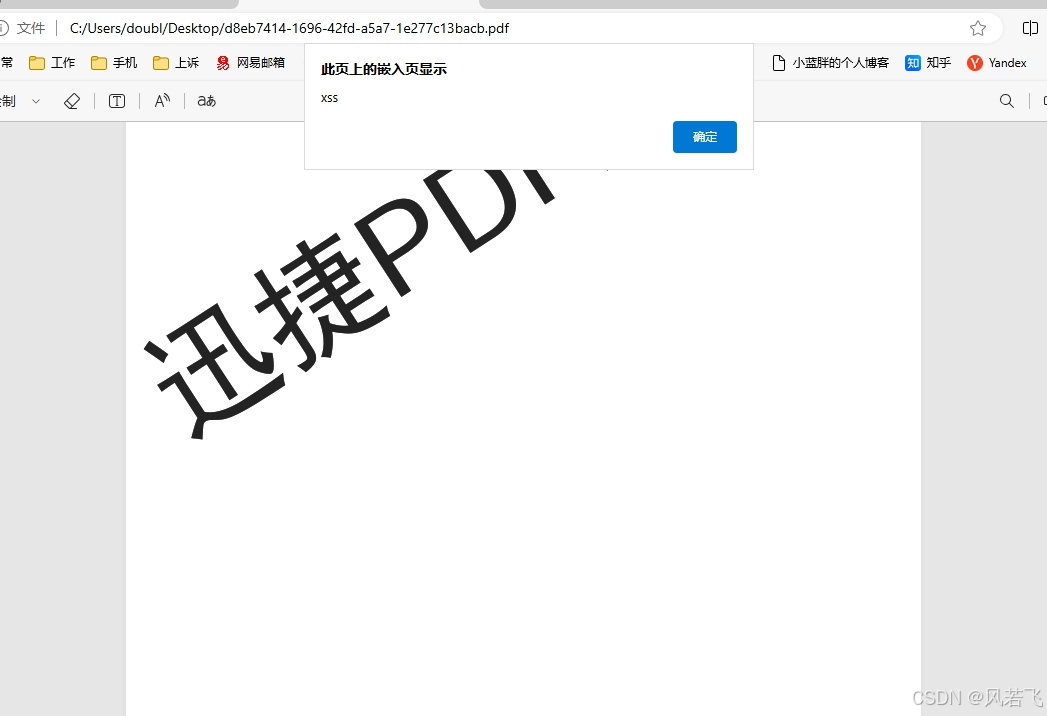
相关包 itextsharp 5.5.13.4
itextsharp
using itextsharp.text.pdf;
using itextsharp.text.pdf.parser;
private boolean ispdfsafe(stream stream)
{
// pdfreader reader = new pdfreader(stream);
using (pdfreader reader = new pdfreader(stream))
{
for (int i = 1; i <= reader.numberofpages; i++)
{
pdfdictionary pagedic = reader.getpagen(i);
pdfobject obj = pdfreader.getpdfobject(pagedic.get(pdfname.annots));
if (obj == null || !obj.isarray())
continue;
pdfarray annots = (pdfarray)obj;
for (int j = 0; j < annots.size; j++)
{
pdfdictionary annot = annots.getasdict(j);
pdfname subtype = annot.getasname(pdfname.subtype);
if (pdfname.link.equals(subtype))
{
pdfdictionary actiondict = annot.getasdict(pdfname.a);
if (actiondict != null)
{
pdfobject action = actiondict.get(pdfname.s);
if (action != null)
{
//可以判断具体哪些事件被拦截,目前已知事件goto,uri(连接跳转)
console.writeline("action found: " + action.tostring());
return false;
}
}
}
}
}
}
return true;
}
//应用的地方 写入缓存比较好,因为是非报错判断成功后可进行保存
using (memorystream memorystream = new memorystream(buffer))
{
if (!ispdfsafe(memorystream))
{
//todo 返回错误信息
}
}
以上就是判断脚本的相关代码。
2.下面介绍一下读取pdf内容的脚本内容,仅做参考。
for (int i = 1; i <= reader.numberofpages; i++)
{
pdfdictionary pagedict = reader.getpagen(i);
pdfdictionary resourcesdict = pagedict.getasdict(pdfname.resources);
// pdfdictionary action = resourcesdict.getasdict(pdfname.action);
// pdfdictionary actiondict = javascriptdict.getasdict(pdfname.javascript);
if (resourcesdict != null)
{
pdfdictionary javascriptdict = resourcesdict.getasdict(pdfname.js);
if (javascriptdict != null)
{
pdfdictionary actiondict = javascriptdict.getasdict(pdfname.javascript);
if (actiondict != null)
{
return false;
}
}
}
}
除了上面的itextsharp ,还有itext7也是做pdf相关处理的。itextsharp 已经停止更新两年了,如果要开发建议用itext7,上述代码进攻参考,因为版本不一样,调用接口也会不一样,开发时候请查相关api具体内容。
代码地址:https://github.com/itext/itextsharp
api地址:https://api.itextpdf.com/itext/dotnet/



发表评论