在rt-thread/include/rtdef.h文件里有对链表节点的定义
/**
* double list structure 双链表
*/
struct rt_list_node
{
struct rt_list_node *next; /**< point to next node. */
struct rt_list_node *prev; /**< point to prev node. */
};
typedef struct rt_list_node rt_list_t; /**< type for lists. */
/**
* single list structure 单链表
*/
struct rt_slist_node
{
struct rt_slist_node *next; /**< point to next node. */
};
typedef struct rt_slist_node rt_slist_t; /**< type for single list. */
在rt-thread/include/rtservice.h文件里有对链表的实现
为什么实现会放在.h文件里呢
可以发现每个函数的前边都有一个rt_inline修饰,那这个是啥呢,跳过去看一下
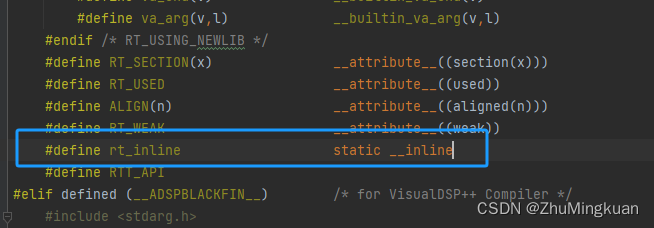
这里涉及到一个知识点——内联函数 static __inline
参考大佬文章static __inline 内联函数
_inline函数也称为内联函数或内嵌函数,_inline定义的类的内联函数,函数代码被放入符号调用表,使用时直接展开,不需要调用,即在编译期间将所调用的函数的代码直接嵌入到主调函数中,是一种以空间换时间的函数.
内联函数有些类似于宏。内联函数的代码会被直接嵌入在它被调用的地方,没有使用call指令。这样省去了函数调用时的一些额外开销,可以加快速度。
static _inline的内联函数,一般情况下不会产生函数本身的代码,而是全部被嵌入在被调用的地方。如果不加static,则表示该函数有可能会被其他编译单元所调用,所以一定会产生函数本身的代码。所以加了static,一般可令可执行文件变小。内核里一般见不到只用inline的情况,而都是使用static inline。
接着来看rt-thread中链表的具体实现,这里只关注双链表
/**
* @brief initialize a list 链表初始化,前后都指向自己
*
* @param l list to be initialized
*/
rt_inline void rt_list_init(rt_list_t *l)
{
l->next = l->prev = l;
}
/**
* @brief insert a node after a list 在后边插入一个节点
*
* @param l list to insert it
* @param n new node to be inserted
*/
rt_inline void rt_list_insert_after(rt_list_t *l, rt_list_t *n)
{
l->next->prev = n;
n->next = l->next;
l->next = n;
n->prev = l;
}
/**
* @brief insert a node before a list 在前边插入一个节点
*
* @param n new node to be inserted
* @param l list to insert it
*/
rt_inline void rt_list_insert_before(rt_list_t *l, rt_list_t *n)
{
l->prev->next = n;
n->prev = l->prev;
l->prev = n;
n->next = l;
}
/**
* @brief remove node from list. 从链表中删除一个节点
* @param n the node to remove from the list.
*/
rt_inline void rt_list_remove(rt_list_t *n)
{
n->next->prev = n->prev;
n->prev->next = n->next;
n->next = n->prev = n;
}
/**
* @brief tests whether a list is empty 检查链表是否为空
* @param l the list to test.
*/
rt_inline int rt_list_isempty(const rt_list_t *l)
{
return l->next == l;
}
/**
* @brief get the list length 获取链表的长度
* @param l the list to get.
*/
rt_inline unsigned int rt_list_len(const rt_list_t *l)
{
unsigned int len = 0;
const rt_list_t *p = l;
while (p->next != l)
{
p = p->next;
len ++;
}
return len;
}
该文件里还有几个宏定义,着重看一下下面这个
/**
* rt_container_of - return the member address of ptr, if the type of ptr is the
* struct type.
*/
#define rt_container_of(ptr, type, member) \
((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))
/**
* @brief initialize a list object
*/
#define rt_list_object_init(object) { &(object), &(object) }
/**
* @brief get the struct for this entry
* @param node the entry point
* @param type the type of structure
* @param member the name of list in structure
*/
#define rt_list_entry(node, type, member) \
rt_container_of(node, type, member)
/**
* rt_list_for_each - iterate over a list
* @pos: the rt_list_t * to use as a loop cursor.
* @head: the head for your list.
*/
#define rt_list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
着重看一下这个宏 #define rt_container_of(ptr, type, member)
这个宏的作用是通过结构体成员的指针 ptr 和成员名 member,计算出包含该成员的结构体的起始地址,并将其转换为 type 类型的指针。简单点说就是用于从一个结构体成员的指针获取整个结构体的指针。
我们来看一下它的具体实现过程:
(type *)0:将 0 强制转换为 type 类型的指针。这意味着我们假设结构体的起始地址是 0。
&((type *)0)->member:获取结构体成员 member 的地址。由于结构体的起始地址是 0,所以这个地址实际上是成员 member 相对于结构体起始地址的偏移量。
(unsigned long)(&((type *)0)->member):将成员的偏移量 转换为 unsigned long 类型。
(char *)(ptr):将指向成员的指针 ptr 转换为 char * 类型。这样做是为了进行指针算术运算,因为 char 类型的指针算术运算是按字节进行的。
(char *)(ptr) - (unsigned long)(&((type *)0)->member):通过减去成员的偏移量,得到结构体的起始地址。
(type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member)):将计算结果转换回 type 类型的指针。
在简单一点说,就是先计算出member和type类型结构体之间的偏移量,同时这个偏移量也是 ptr 和 type之间的偏移量,然后ptr的地址减去 这个偏移量 就得到 这个结构体的 起始地址啦。
本小白第一次接触这段代码,听说和linux是一样的,感觉很妙。
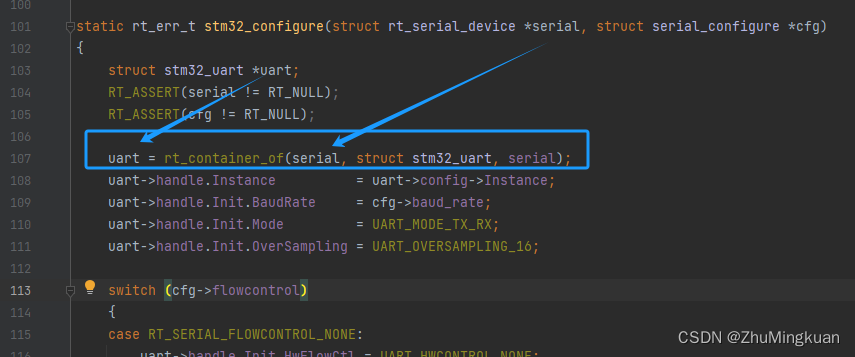
为什么要着重看一下这个宏定义呢
因为在设备驱动框架中就用到了,比如下面这段,这句话是 由父结构体 得到 子结构体的地址,因为 子结构体 继承 父结构体,也就是 父结构体 是 子结构体 中的一个成员。
反正这里先记住这个宏比较重要就可以了。
(其实如果把父结构体 放在 子结构体 的第一个成员 ,就不用这么麻烦了,但是既然是这么写的,那就先这么学吧)


发表评论