现象
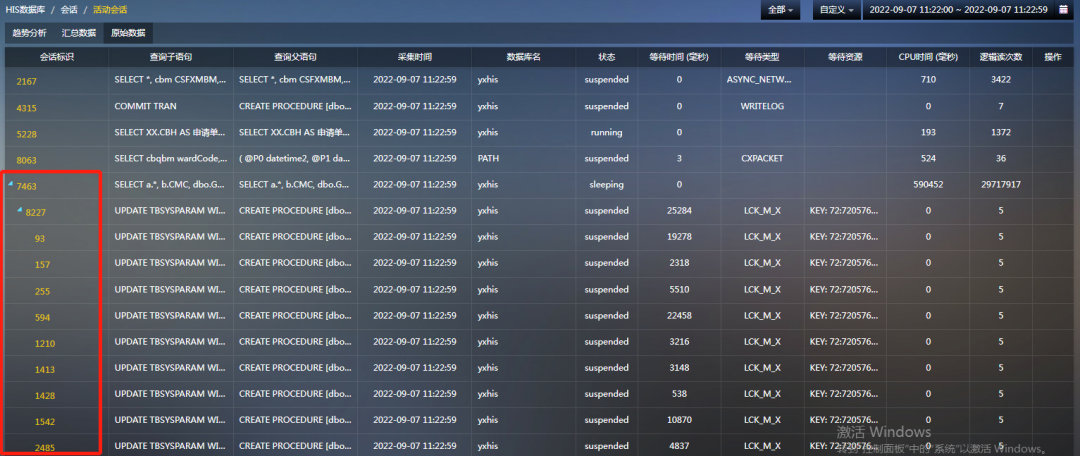
登录sql专家云,进入趋势分析页面,下钻到11点钟内一个小时的数据,看到从11:12开始出现阻塞,越来越严重。

进入活动会话原始数据页面,看到不同时间点的阻塞源头会话是不同的,但都是同一类的现象,阻塞源头会话的状态是sleeping,被阻塞的会话都在对同一个表执行update语句。
分析
状态为sleeping代表当前会话没有执行sql请求,之所以造成阻塞是因为会话以前开启了一个或多个事务, 在事务中修改了一个或多个表的数据,会话对这些修改的数据行持有排他锁,从而阻塞其他会话对该表的操作。如果这种状态持续很长时间,很有可能是前端应用程序出现了异常,并且没有健壮的异常处理机制,出错后没有回滚以前打开的事务并关闭连接,导致阻塞一直存在。 前端应用程序出错原因主要有两种,一种是执行sql语句时被阻塞等原因导致执行时间长并产生超时;一种是执行非数据库访问逻辑时因为某些原因出错了,例如转换数据类型失败、接收数据量太大导致内存溢出、访问别的接口报错等。
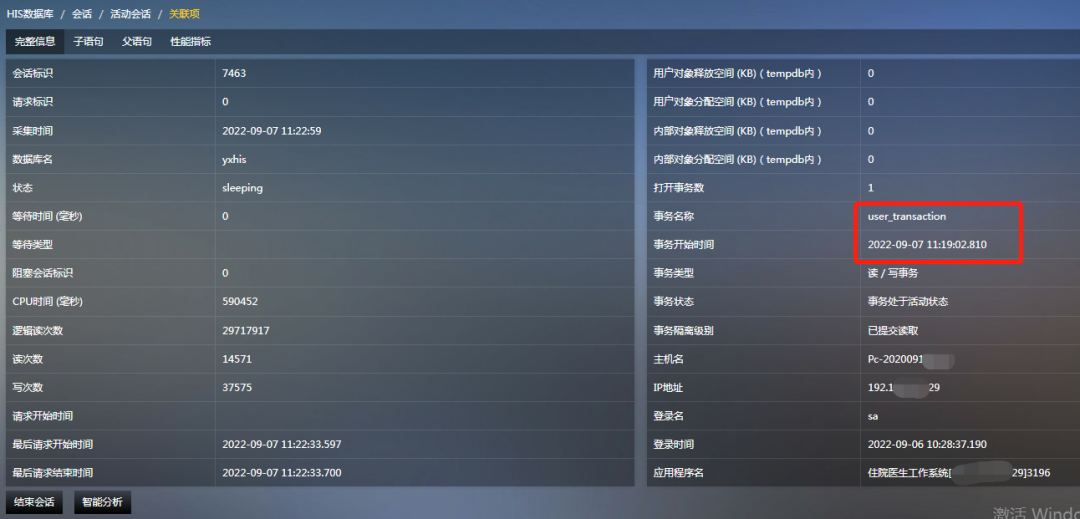
本着这个经验,对这些sleeping的会话进行回溯,发现这些会话在sleeping之前,都曾经被阻塞过很长时间,根据慢语句的特征判断是执行超时了。


而且这些会话都存在打开的事务,事务开始时间都在执行语句超时的时间之前。
通过对存储过程进行分析,发现里面在用try catch的方式处理事务,因此推断该方式无法捕获应用程序端的超时错误,导致事务和连接的泄露,因为存储过程比较复杂,下面用一个测试来模拟。
测试
首先创建一个存储过程,逻辑为先开始事务,然后依次对两个表进行update,通过try catch的方法处理事务。
create procedure dbo.usp_test
as
begin tran
begin try
update
dbo.table_2 with(rowlock)
set
a = 'wang'
update
dbo.table_1 with(rowlock)
set
a = 'wang'
end try
begin catch
if @@error = 0
begin
goto succeed
end
else
begin
goto error
end
end catch
succeed:
commit tran
return 1
error:
rollback tran
return 0
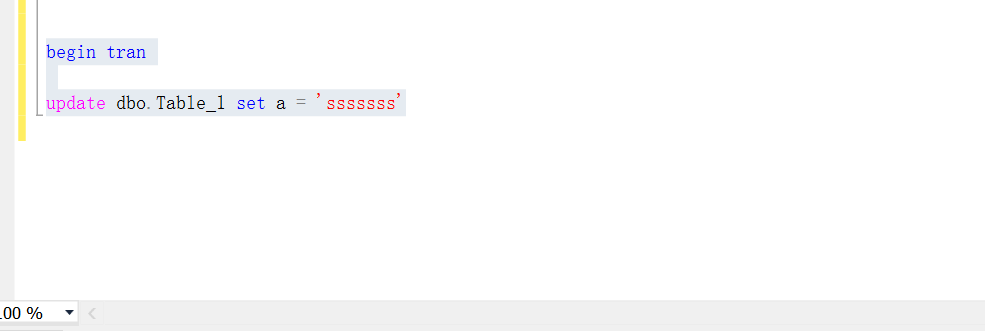
新建一个查询,开始一个事务,然后执行update table_1,不提交或者回滚事务,对表table_1的排他锁一直存在, 用来模拟对表table_1的锁定。
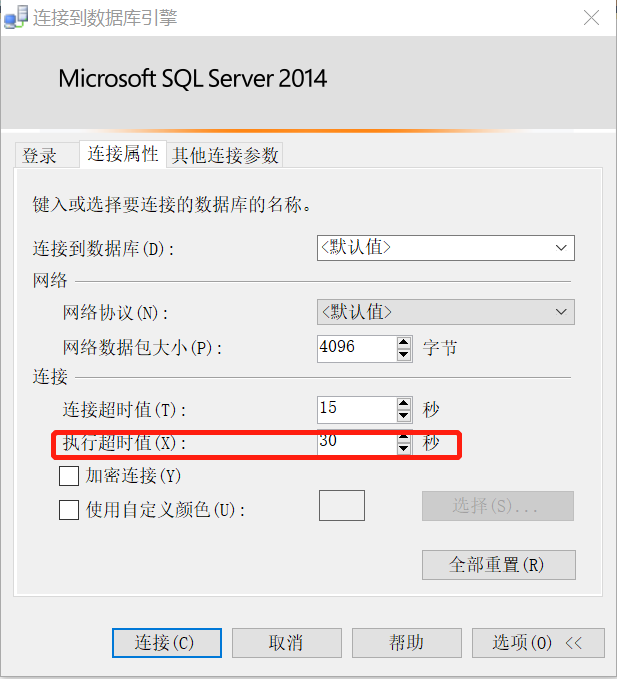
新建另一个查询,注意,执行超时值设置为30秒(默认是0,代表永不超时)。这个新建立的会话id是56。
执行存储过程usp_test。updat dbo.table_2很快执行完,在执行updat dbo.table_1时产生阻塞,等待30秒后出现超时的报错。
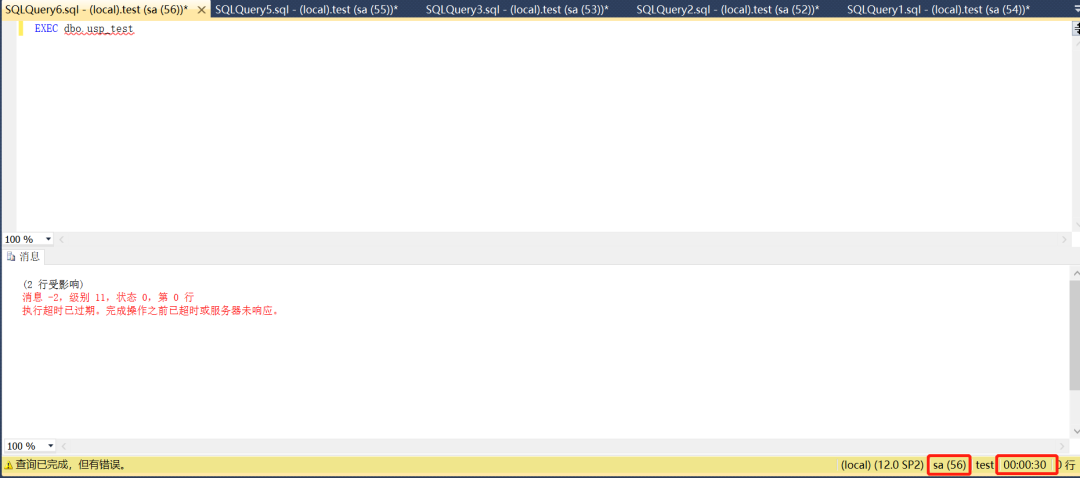
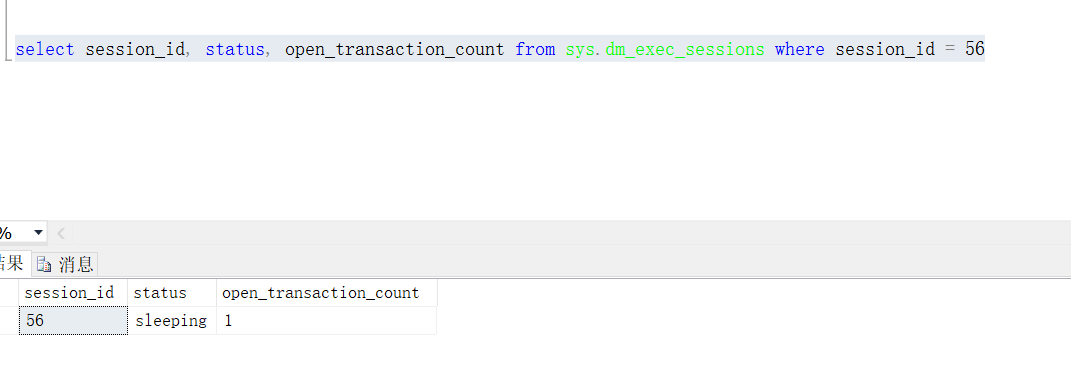
新建一个查询,查看会话56的事务信息,可以看到存在一个打开的事务。
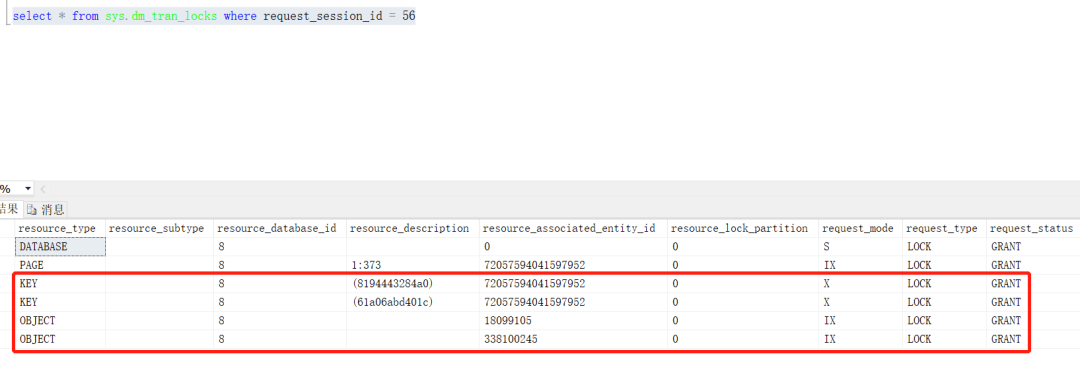
再通过sys.dm_tran_locks可以看到会话56还保持着对表table_2和table_1的意向排他锁以及table_2上更改的两行数据的排他锁。此时在其他会话中对table_2执行查询和修改,都被会话56阻塞。
总结:“超时”错误是应用程序端的异常,数据库驱动程序执行sql语句时等待服务器端的响应,等待时间达到设置的阈值后发送一个终止执行的信号给服务器端并向上层应用程序抛出异常。服务器端接收到该信号后终止语句的执行,并不会报错,try catch是无法捕获的,因此无法执行到succeed处的commit或者error处的rollback,导致了事务的泄露,该事务中的对表table_2的排他锁一直持有,其他会话对表table_2的操作会被阻塞,直到杀掉该会话。
解决
对于这类问题,根本的解决方法是修改应用程序,增加对于执行异常的捕获,检查是否存在事务并回滚,然后关闭数据库连接。
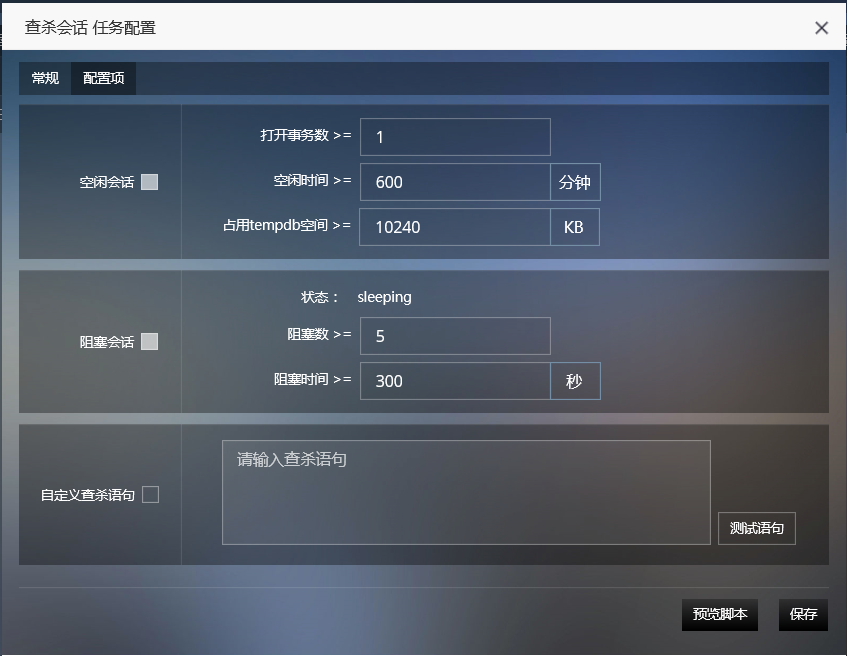
但是很多客户是购买软件厂商的产品,修改程序不容易实现或者周期很长。因此只能在数据库端进行补偿性的措施,就是配置一个自动查杀会话的作业,根据sleeping会话的特征定期kill掉。也可以在sql专家云中启用自动查杀会话的功能。




发表评论