深入探秘hadoop生态系统:全面解析各组件及其实际应用
引言
在大数据时代,如何高效处理和存储海量数据成为企业面临的重大挑战。根据gartner的统计,到2025年,全球数据量将达到175泽字节(zb),传统的数据处理技术已经无法满足这一需求。hadoop生态系统作为一种强大的大数据处理解决方案,广泛应用于各个行业。本文将深入探讨hadoop生态系统中的各个组件及其实际应用,帮助企业解决大数据处理的难题。
问题提出
- 如何高效存储和管理海量数据?
- 如何进行大规模数据的并行处理和分析?
- 如何实现实时数据的采集和传输?
解决方案
hdfs:高效存储和管理海量数据
问题:如何高效存储和管理海量数据?
解决方案:
hdfs(hadoop分布式文件系统)是hadoop的核心存储系统,具有高容错性和高可扩展性。hdfs通过将数据分块存储在多个节点上,实现了数据的并行读写和快速访问。
实际操作:
在ubuntu上安装hdfs
# 更新系统
sudo apt-get update
# 安装java
sudo apt-get install openjdk-8-jdk -y
# 下载hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
# 解压hadoop
tar -xzvf hadoop-3.3.1.tar.gz
# 配置hadoop环境变量
echo 'export hadoop_home=/path/to/hadoop' >> ~/.bashrc
echo 'export path=$path:$hadoop_home/bin' >> ~/.bashrc
source ~/.bashrc
# 配置hdfs
cd $hadoop_home/etc/hadoop
cp hadoop-env.sh hadoop-env.sh.bak
echo 'export java_home=/usr/lib/jvm/java-8-openjdk-amd64' >> hadoop-env.sh
# 启动hdfs
hdfs namenode -format
start-dfs.sh
应用场景:大规模数据存储和管理,适用于数据密集型计算任务,如日志分析和数据挖掘。
mapreduce:大规模数据的并行处理
问题:如何进行大规模数据的并行处理和分析?
解决方案:
mapreduce是hadoop的核心数据处理模型,通过map和reduce两个阶段,将任务分解为多个子任务并行执行,提高数据处理效率。
实际操作:
mapreduce任务示例
import java.io.ioexception;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.intwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.reducer;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
public class wordcount {
public static class tokenizermapper extends mapper<object, text, text, intwritable> {
private final static intwritable one = new intwritable(1);
private text word = new text();
public void map(object key, text value, context context) throws ioexception, interruptedexception {
string[] words = value.tostring().split("\\s+");
for (string w : words) {
word.set(w);
context.write(word, one);
}
}
}
public static class intsumreducer extends reducer<text, intwritable, text, intwritable> {
public void reduce(text key, iterable<intwritable> values, context context) throws ioexception, interruptedexception {
int sum = 0;
for (intwritable val : values) {
sum += val.get();
}
context.write(key, new intwritable(sum));
}
}
public static void main(string[] args) throws exception {
configuration conf = new configuration();
job job = job.getinstance(conf, "word count");
job.setjarbyclass(wordcount.class);
job.setmapperclass(tokenizermapper.class);
job.setcombinerclass(intsumreducer.class);
job.setreducerclass(intsumreducer.class);
job.setoutputkeyclass(text.class);
job.setoutputvalueclass(intwritable.class);
fileinputformat.addinputpath(job, new path(args[0]));
fileoutputformat.setoutputpath(job, new path(args[1]));
system.exit(job.waitforcompletion(true) ? 0 : 1);
}
}
应用场景:大规模数据处理和分析任务,如数据清洗、转换和聚合,适用于批处理任务。
hive:数据仓库和bi应用
问题:如何进行大规模数据的查询和分析?
解决方案:
hive是一个数据仓库系统,提供类似sql的查询语言(hiveql),方便用户进行数据分析。
实际操作:
使用hive进行数据查询
-- 创建表
create table if not exists logs (
id int,
timestamp string,
level string,
message string
)
row format delimited
fields terminated by '\t';
-- 加载数据
load data inpath '/path/to/logs.txt' into table logs;
-- 查询数据
select level, count(*) as count
from logs
group by level;
应用场景:大规模数据的查询和分析,适用于数据仓库和bi(商业智能)应用。
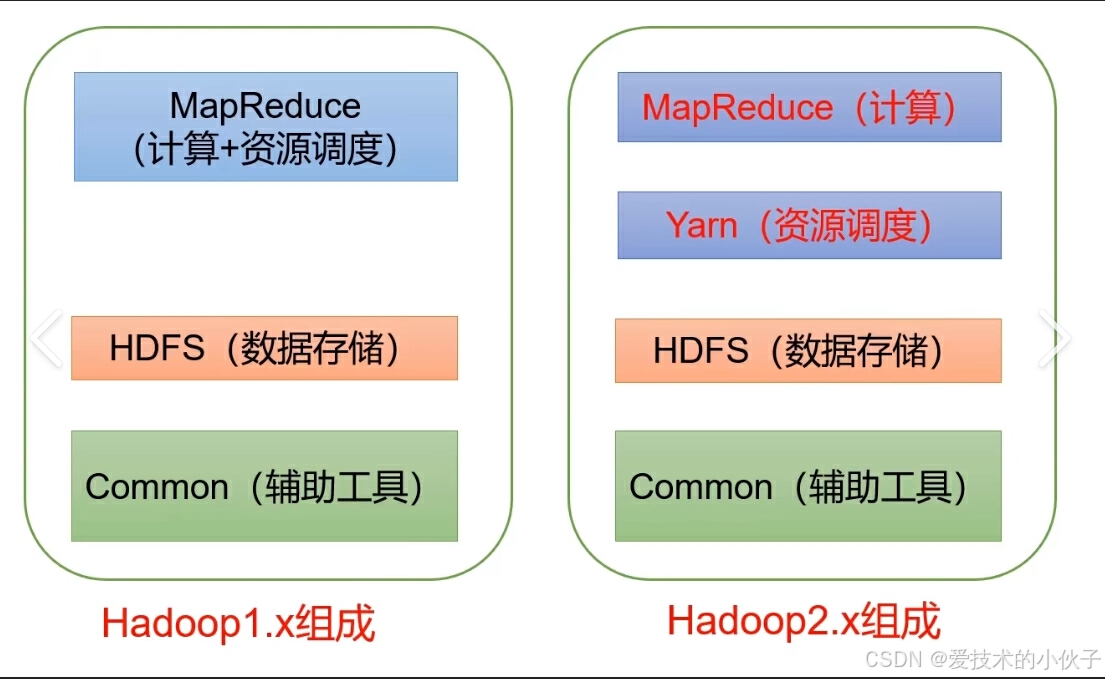
图表和示意图
hadoop生态系统架构图
案例分析
twitter的大数据处理
twitter通过hadoop生态系统,实现了海量用户数据的高效处理和分析。
数据采集:使用flume进行实时数据采集,将用户行为数据和日志数据传输到hdfs。
数据存储:采用hdfs和hbase进行数据存储,确保海量数据的高效存储和访问。
数据处理:使用spark和mapreduce进行数据清洗、转换和分析,实现高效的数据处理和分析。
数据分析:采用hive进行数据查询和分析,支持灵活的数据分析和报表生成。
数据展示:使用tableau进行数据可视化,将分析结果以图表、报表等形式展示,支持业务决
策。
最佳实践
- 数据治理:通过数据治理确保数据的一致性和准确性,包括数据标准化、数据质量控制和数据安全管理。
- 自动化运维:采用自动化运维工具进行系统监控和管理,提高系统的稳定性和可靠性。
- 性能优化:通过性能调优和优化,提升系统的吞吐量和响应速度,确保在大数据量下的高性能。
- 持续集成和部署:采用持续集成和部署(ci/cd)流程,提高系统的开发和部署效率,确保系统的快速迭代和发布。
结论
hadoop生态系统提供了一套完整的大数据处理解决方案,涵盖了数据采集、存储、处理、分析和管理等各个方面。通过合理的架构设计和技术选型,企业可以构建高效的大数据处理系统,实现海量数据的高效处理和分析,支持业务决策和发展。
希望这篇文章对你有所帮助,推动hadoop生态系统在你的企业中成功落地和实施。如果你在实际操作中遇到问题,请参考hadoop社区资源和实践经验,以获取更多帮助。




发表评论