
作为一名大数据开发,我深知学习新技术的重要性。今天,我想和大家分享如何高效学习flink这个强大的流处理框架。
目录
flink是什么?

apache flink是一个开源的分布式大数据处理引擎,用于对无界和有界数据流进行有状态的计算。它提供了数据流上的精确一次处理语义,以及事件时间和处理时间的灵活窗口机制。
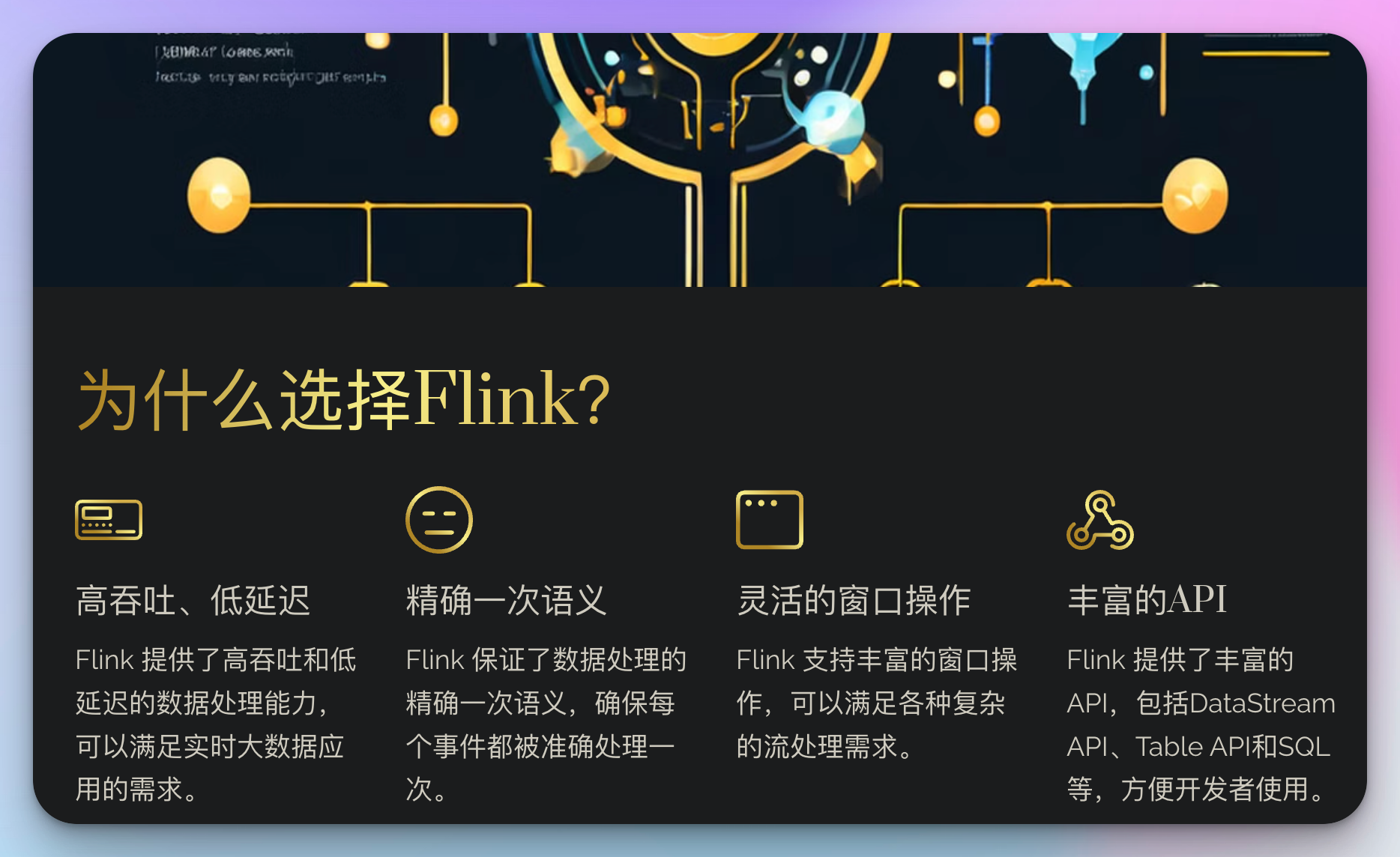
为什么选择flink?
- 高吞吐、低延迟
- 精确一次语义
- 灵活的窗口操作
- 丰富的api
学习flink的糙快猛之路
1. 建立概念框架
首先,我们需要对flink的核心概念有一个大致了解:
- datastream api
- 窗口操作
- 状态管理
- 时间语义

不要一开始就追求完全理解每个细节,先建立一个框架,后续再填充。
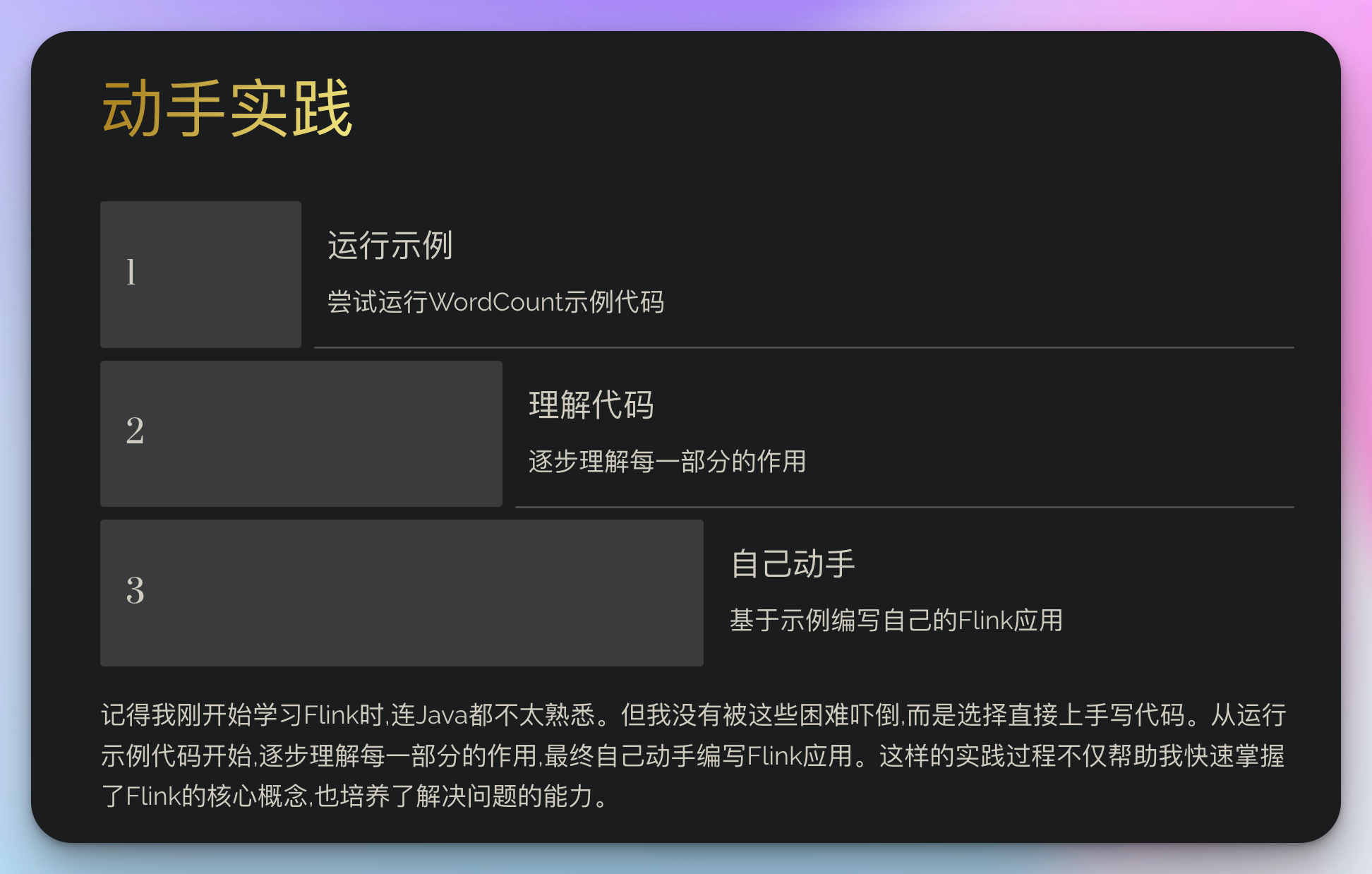
2. 动手实践
记得我刚开始学习flink时,连java都不太熟悉。但我没有被这些困难吓倒,而是选择直接上手写代码。
这里有一个简单的wordcount示例:
public class wordcount {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
datastream<string> text = env.fromelements(
"to be, or not to be,--that is the question:--",
"whether 'tis nobler in the mind to suffer"
);
datastream<tuple2<string, integer>> counts = text
.flatmap(new flatmapfunction<string, tuple2<string, integer>>() {
@override
public void flatmap(string value, collector<tuple2<string, integer>> out) {
for (string word : value.tolowercase().split("\\w+")) {
out.collect(new tuple2<>(word, 1));
}
}
})
.keyby(0)
.sum(1);
counts.print();
env.execute("word count example");
}
}
这段代码可能看起来很复杂,但不要被吓到。先运行起来,看看结果,然后逐步理解每一部分的作用。
3. 利用大模型助手

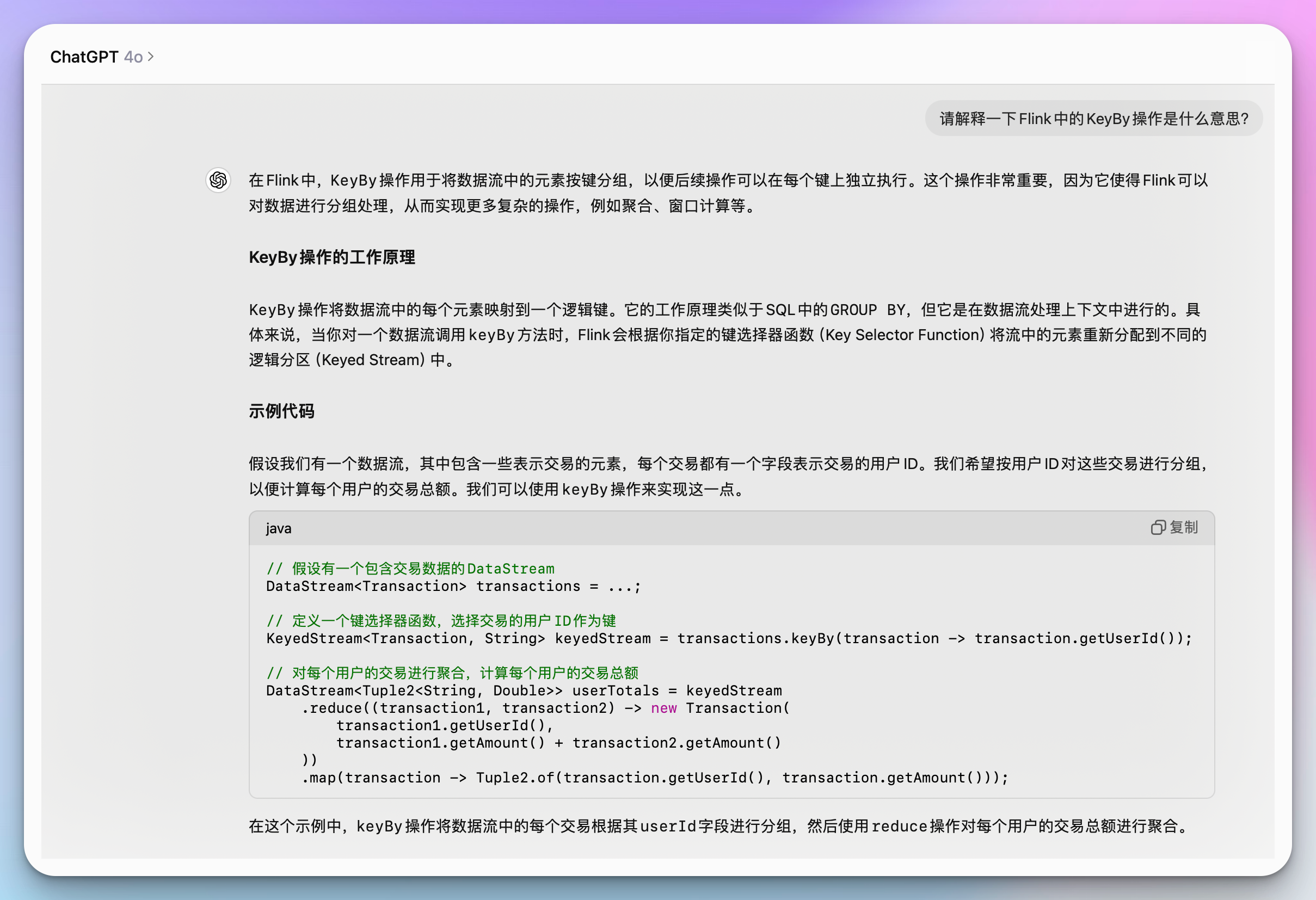
在学习过程中,遇到不懂的概念或代码,可以随时询问ai助手。比如:
“请解释一下flink中的keyby操作是什么意思?”
ai助手可以给出清晰的解释,帮助你快速理解概念。
4. 构建小项目
学习了基础知识后,尝试构建一个小项目。比如,一个实时统计网站访问量的应用。这将帮助你将零散的知识点串联起来。

5. 阅读官方文档
在实践中遇到问题时,查阅官方文档。这不仅能解决问题,还能加深对flink的理解。

6. 参与社区
加入flink的github仓库,阅读issues和pr,甚至尝试解决一些简单的bug。这将极大地提升你的技能。

进阶学习:深入flink核心概念
让我们继续深入探讨如何更有效地学习和应用flink。
1. 时间语义
flink提供了三种时间语义:事件时间、摄入时间和处理时间。理解这些概念对于处理实时数据流至关重要。

例如,考虑一个实时订单处理系统:
datastream<order> orders = ...
datastream<order> lateorders = orders
.assigntimestampsandwatermarks(
watermarkstrategy
.<order>forboundedoutoforderness(duration.ofminutes(5))
.withtimestampassigner((order, timestamp) -> order.geteventtime())
)
.keyby(order::getuserid)
.window(tumblingeventtimewindows.of(time.hours(1)))
.process(new lateorderdetector());
这段代码使用事件时间语义,允许处理最多5分钟的乱序数据,并在1小时的滚动窗口内检测迟到订单。
2. 状态管理

flink的状态管理是其强大功能之一。理解如何使用和管理状态可以帮助你构建复杂的流处理应用。
这里有一个使用状态的简单示例:
public class statefulcounter extends keyedprocessfunction<string, long, long> {
private valuestate<long> countstate;
@override
public void open(configuration parameters) {
countstate = getruntimecontext().getstate(new valuestatedescriptor<>("count", long.class));
}
@override
public void processelement(long value, context ctx, collector<long> out) throws exception {
long currentcount = countstate.value();
if (currentcount == null) {
currentcount = 0l;
}
currentcount += value;
countstate.update(currentcount);
out.collect(currentcount);
}
}
这个例子展示了如何使用valuestate来维护每个key的计数。
实战项目:实时用户行为分析
让我们通过一个稍微复杂一点的项目来巩固所学知识。假设我们要为一个电商平台构建实时用户行为分析系统。
项目需求
- 实时统计每个商品类别的浏览量
- 检测用户的异常行为(如短时间内多次加入购物车)
- 计算每小时的销售额

代码框架
public class userbehavioranalysis {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
// 假设我们有一个用户行为事件流
datastream<userbehaviorevent> events = env.addsource(new userbehaviorsource());
// 1. 实时统计每个商品类别的浏览量
datastream<tuple2<string, long>> categoryviews = events
.filter(event -> event.geteventtype() == eventtype.view)
.keyby(userbehaviorevent::getcategory)
.window(tumblingprocessingtimewindows.of(time.minutes(5)))
.sum("count");
// 2. 检测用户的异常行为
datastream<string> suspicioususers = events
.keyby(userbehaviorevent::getuserid)
.process(new suspiciousbehaviordetector());
// 3. 计算每小时的销售额
datastream<double> hourlysales = events
.filter(event -> event.geteventtype() == eventtype.purchase)
.keyby(event -> event.gettimestamp().gethour())
.window(tumblingeventtimewindows.of(time.hours(1)))
.process(new hourlysalescalculator());
// 输出结果
categoryviews.print("category views");
suspicioususers.print("suspicious users");
hourlysales.print("hourly sales");
env.execute("user behavior analysis");
}
}
这个项目框架涵盖了flink的多个核心概念,包括数据流转换、窗口操作、处理函数等。

高级特性:flink的精华所在
让我们继续深入探讨flink的学习之路,着重关注一些更高级的主题和实际应用场景。
1. 复杂事件处理(cep)
flink的复杂事件处理库允许你在数据流中检测复杂的事件模式。这在欺诈检测、交易监控等场景中非常有用。

来看一个简单的例子,我们检测用户的连续登录失败:
pattern<logevent, logevent> pattern = pattern.<logevent>begin("first")
.where(new simplecondition<logevent>() {
@override
public boolean filter(logevent event) {
return event.gettype().equals("login_failed");
}
})
.next("second")
.where(new simplecondition<logevent>() {
@override
public boolean filter(logevent event) {
return event.gettype().equals("login_failed");
}
})
.within(time.seconds(10));
patternstream<logevent> patternstream = cep.pattern(input, pattern);
datastream<alert> alerts = patternstream.process(
new patternprocessfunction<logevent, alert>() {
@override
public void processmatch(map<string, list<logevent>> match, context ctx, collector<alert> out) {
out.collect(new alert("two consecutive login failures detected"));
}
});
这段代码检测10秒内的两次连续登录失败,并生成一个警报。
2. 表api和sql
flink的表api和sql支持为开发人员提供了更高级的抽象,使得某些复杂的数据处理任务变得简单。

例如,我们可以使用sql来实现earlier的用户行为分析:
streamtableenvironment tableenv = streamtableenvironment.create(env);
// 注册表
tableenv.createtemporaryview("user_behaviors", events);
// sql查询
table result = tableenv.sqlquery(
"select category, count(*) as view_count " +
"from user_behaviors " +
"where event_type = 'view' " +
"group by category, " +
" tumble(event_time, interval '5' minute)"
);
// 转换回datastream
tableenv.toretractstream(result, row.class).print();
这个例子展示了如何使用sql查询来计算每5分钟的商品类别浏览量。
3. 机器学习集成

flink还可以与机器学习框架集成,实现实时预测和模型更新。例如,我们可以使用flink和tensorflow结合,实现实时推荐系统:
public class realtimerecommender extends richflatmapfunction<useraction, recommendation> {
private transient predictor predictor;
@override
public void open(configuration parameters) {
// 加载tensorflow模型
predictor = new predictor(getruntimecontext().getdistributedcache().getfile("model"));
}
@override
public void flatmap(useraction action, collector<recommendation> out) {
// 使用模型进行预测
float[] features = action.tofeatures();
float[] predictions = predictor.predict(features);
// 输出推荐结果
out.collect(new recommendation(action.getuserid(), predictions));
}
}
实战项目:实时数据湖构建
让我们通过一个更复杂的项目来巩固所学知识:构建一个实时数据湖系统。
项目需求
- 从多个来源实时接入数据
- 对数据进行实时etl处理
- 将处理后的数据写入到hudi表中
- 提供实时查询接口

代码框架
public class realtimedatalake {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
streamtableenvironment tableenv = streamtableenvironment.create(env);
// 1. 从kafka读取数据
datastream<string> kafkastream = env
.addsource(new flinkkafkaconsumer<>("topic", new simplestringschema(), properties));
// 2. 实时etl处理
datastream<row> processedstream = kafkastream
.map(new jsontorowmapper())
.keyby(row -> row.getfield(0))
.process(new etlprocessor());
// 3. 写入hudi
hoodiestreamer<row> streamer = hoodieflinkstreamer
.builder()
.config(gethoodieconfig())
.source(processedstream)
.build();
streamer.schedulecompaction();
streamer.scheduleclustering();
// 4. 提供实时查询接口
table huditable = tableenv.sqlquery("select * from hudi_table");
tableenv.toretractstream(huditable, row.class).print();
env.execute("real-time data lake");
}
}
这个项目涵盖了数据接入、处理、存储和查询的全流程,是一个典型的实时数据湖应用场景。

flink 生态系统:beyond 核心 api
让我们继续深入探讨flink的学习之路,这次我们将聚焦于一些更加高级和实用的主题。
1. flink cdc (change data capture)
flink cdc 是一个强大的工具,用于捕获数据库的变更并将其转换为 flink 数据流。这在构建实时数据管道时特别有用。

示例:从 mysql 读取变更数据
public class mysqlcdcexample {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
sourcefunction<string> sourcefunction = mysqlsource.<string>builder()
.hostname("localhost")
.port(3306)
.databaselist("mydb")
.tablelist("mydb.users")
.username("root")
.password("password")
.deserializer(new stringdebeziumdeserializationschema())
.build();
env
.addsource(sourcefunction)
.print().setparallelism(1);
env.execute("mysql cdc example");
}
}
这个例子展示了如何使用 flink cdc 从 mysql 数据库捕获变更数据。
2. flink ml (machine learning)
flink ml 提供了在 flink 中进行机器学习的能力。它支持训练和推理,使得在流处理中集成机器学习变得更加容易。

示例:使用 flink ml 进行在线学习
public class onlinelearningexample {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
datastream<labeledvector> trainingdata = env.addsource(new trainingdatasource());
onlinelogisticregression learner = new onlinelogisticregression()
.setlearningrate(0.1)
.setregularizationconstant(0.01);
datastream<model> model = learner.fit(trainingdata);
model.print();
env.execute("online learning example");
}
}
这个例子展示了如何使用 flink ml 进行在线逻辑回归学习。
高级优化技巧
1. 背压处理

背压是流处理系统中常见的问题。理解和处理背压对于构建高性能的 flink 应用至关重要。
public class backpressurehandling {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
// 设置缓冲超时,有助于减少背压
env.setbuffertimeout(100);
datastream<string> stream = env.addsource(new fastsource())
.map(new heavymapper())
.setparallelism(4) // 增加并行度来处理背压
.filter(new backpressurefilter());
stream.print();
env.execute("backpressure handling example");
}
static class backpressurefilter implements filterfunction<string> {
@override
public boolean filter(string value) throws exception {
// 模拟一个耗时的操作
thread.sleep(100);
return true;
}
}
}
这个例子展示了几种处理背压的方法,包括设置缓冲超时和增加并行度。
2. 状态优化
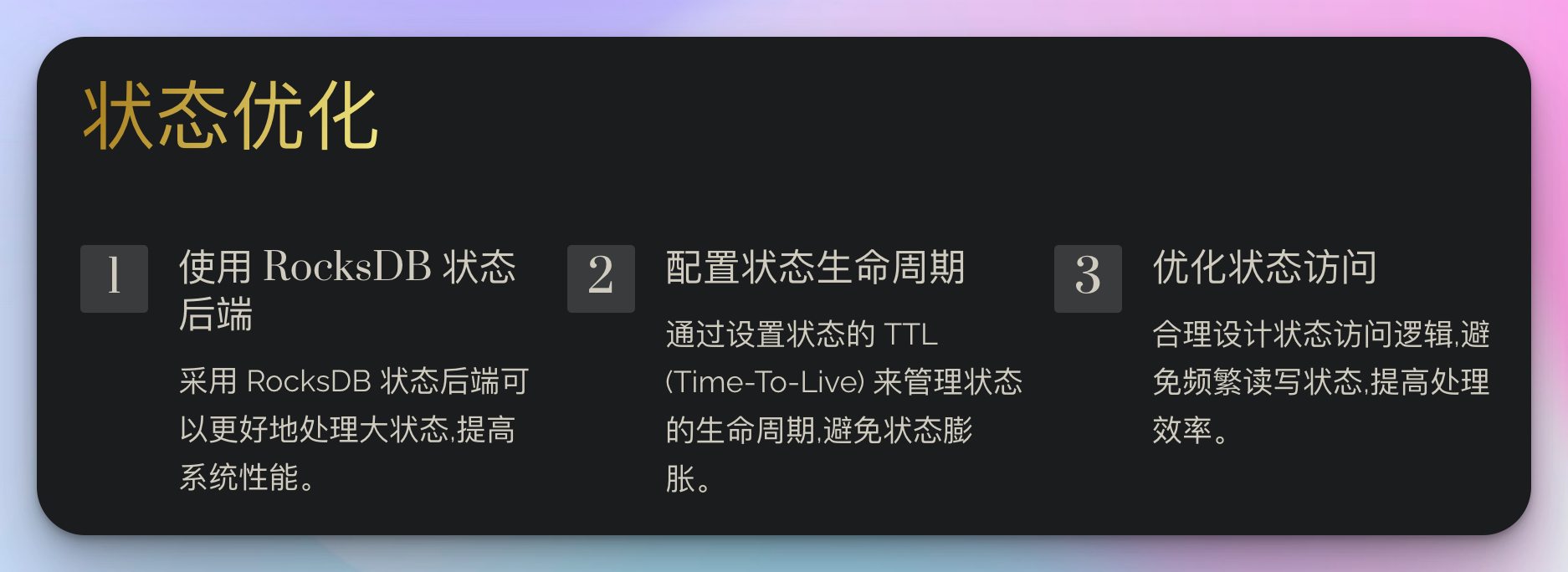
对于有状态的操作,正确管理状态大小对于性能至关重要。
public class stateoptimizationexample {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
// 使用 rocksdb 状态后端来处理大状态
env.setstatebackend(new embeddedrocksdbstatebackend());
datastream<tuple2<string, integer>> stream = env.addsource(new datasource())
.keyby(t -> t.f0)
.process(new statefulprocessor());
stream.print();
env.execute("state optimization example");
}
static class statefulprocessor extends keyedprocessfunction<string, tuple2<string, integer>, tuple2<string, integer>> {
private valuestate<integer> state;
@override
public void open(configuration parameters) {
// 使用 ttl 来管理状态生命周期
statettlconfig ttlconfig = statettlconfig
.newbuilder(time.hours(1))
.setupdatetype(statettlconfig.updatetype.oncreateandwrite)
.setstatevisibility(statettlconfig.statevisibility.neverreturnexpired)
.build();
valuestatedescriptor<integer> descriptor = new valuestatedescriptor<>("mystate", integer.class);
descriptor.enabletimetolive(ttlconfig);
state = getruntimecontext().getstate(descriptor);
}
@override
public void processelement(tuple2<string, integer> value, context ctx, collector<tuple2<string, integer>> out) throws exception {
integer current = state.value();
if (current == null) {
current = 0;
}
current += value.f1;
state.update(current);
out.collect(new tuple2<>(value.f0, current));
}
}
}
这个例子展示了如何使用 rocksdb 状态后端和 ttl 配置来优化状态管理。
实战项目:实时异常检测系统
让我们通过一个更加复杂的项目来综合运用我们所学的知识:构建一个实时异常检测系统。
项目需求
- 从多个数据源实时接入日志数据
- 使用 flink cep 检测复杂的异常模式
- 利用 flink ml 进行异常评分
- 将检测结果实时写入到 kafka 和 elasticsearch
代码框架
public class realtimeanomalydetection {
public static void main(string[] args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
// 1. 数据接入
datastream<logevent> logstream = env
.addsource(new flinkkafkaconsumer<>("logs", new logeventdeserializationschema(), properties));
// 2. cep 异常模式检测
pattern<logevent, logevent> pattern = pattern.<logevent>begin("start")
.where(new simplecondition<logevent>() {
@override
public boolean filter(logevent event) {
return event.getseverity().equals("error");
}
})
.next("middle")
.where(new simplecondition<logevent>() {
@override
public boolean filter(logevent event) {
return event.getseverity().equals("error");
}
})
.within(time.seconds(10));
patternstream<logevent> patternstream = cep.pattern(logstream, pattern);
datastream<anomalyevent> anomalies = patternstream.process(
new patternprocessfunction<logevent, anomalyevent>() {
@override
public void processmatch(map<string, list<logevent>> match, context ctx, collector<anomalyevent> out) {
out.collect(new anomalyevent(match));
}
});
// 3. 机器学习评分
onlinelogisticregression model = new onlinelogisticregression()
.setlearningrate(0.1)
.setregularizationconstant(0.01);
datastream<scoredanomalyevent> scoredanomalies = model.transform(anomalies);
// 4. 结果输出
flinkkafkaproducer<scoredanomalyevent> kafkaproducer = new flinkkafkaproducer<>(
"anomalies",
new anomalyeventserializationschema(),
properties,
flinkkafkaproducer.semantic.exactly_once
);
elasticsearchsink.builder<scoredanomalyevent> essinkbuilder = new elasticsearchsink.builder<>(
httphosts,
new elasticsearchsinkfunction<scoredanomalyevent>() {
@override
public void process(scoredanomalyevent element, runtimecontext ctx, requestindexer indexer) {
indexer.add(createindexrequest(element));
}
}
);
scoredanomalies
.addsink(kafkaproducer)
.name("kafka sink");
scoredanomalies
.addsink(essinkbuilder.build())
.name("elasticsearch sink");
env.execute("real-time anomaly detection");
}
}
这个项目综合了我们之前讨论的多个高级特性,包括 cep、机器学习、多种 sink 等。
结语
通过这个系列的探讨,我们从 flink 的基础概念,一直深入到了高级特性和实战项目。记住,成为一个优秀的 flink 开发者是一个持续学习和实践的过程。
"糙快猛"的学习方式让我们能够快速上手,但真正的掌握需要不断的思考和实践。。
最后,我想用一句话来总结我们的 flink 学习之旅:
“在数据的海洋中,flink 是你的航船。熟悉它,运用它,你将能够驾驭任何数据的风浪。”
祝你在 flink 的学习之路上一帆风顺,早日成为独当一面的大数据工程师!加油!




发表评论