一、部署说明
废话不多说,直接上链接。
下载完成后上传至服务器中,执行如下命令解压:
tar -zxvf xxx.tar.gz解压完成后,将安装路径加入到 /etc/profile 或者 .bashrc文件中,然后使用 source /etc/profile 或者 source ~/.bashrc 使环境生效。
export java_home=/usr/lib/jdk1.8.0_131
export path=$path:$java_home/bin
export flink_home=/home/web/zhangxiang/flink-1.18.1
export path=$path:$flink_home/bin
export hadoop_home=/home/web/zhangxiang/ha/hadoop-3.4.0
export hadoop_conf_dir=$hadoop_home/etc/hadoop
export path=${hadoop_home}/bin:$path
export path=$path:$hadoop_home/sbin:$path
export hadoop_classpath=`hadoop classpath`
export zookeeper_home=/home/web/zhangxiang/zookeeper-3.8.4
export path=$path:$zookeeper_home/bin
二、集群规划
2.1 flink ha
| r3 | s3 | s4 |
|
jobmanager
|
jobmanager
| |
|
taskmanager
|
taskmanager
|
taskmanager
|
|
historyserver
|
服务器之间要设置互免登录,具体操作可询问chatgpt或者通义千问,不在此赘述;并且更改 /etc/hosts 文件,命令如下:
vim /etc/hosts内容如下:
2.1.1 配置文件
2.1.1.1 flink-conf.yaml
jobmanager.rpc.address: r3
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 2048m
taskmanager.host: r3
taskmanager.memory.process.size: 4096m
taskmanager.numberoftaskslots: 3
parallelism.default: 3
high-availability.type: zookeeper
high-availability.storagedir: hdfs://mycluster/flink/ha/
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_one
high-availability.zookeeper.quorum: r3:2181,s3:2181,s4:2181
execution.checkpointing.interval: 30000
execution.checkpointing.externalized-checkpoint-retention: retain_on_cancellation
execution.checkpointing.max-concurrent-checkpoints: 2
execution.checkpointing.min-pause: 500
execution.checkpointing.mode: exactly_once
execution.checkpointing.timeout: 600000
execution.checkpointing.tolerable-failed-checkpoints: 3
restart-strategy.type: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10000
state.backend: filesystem
state.checkpoints.dir: hdfs://mycluster/flink-checkpoints
state.savepoints.dir: hdfs://mycluster/flink-savepoints
jobmanager.execution.failover-strategy: region
# 另外的高可用节点上关于此行不用更改,保持一致即可。
rest.port: 8081
rest.address: r3
jobmanager.archive.fs.dir: hdfs://mycluster/logs/flink-job
historyserver.web.address: r3
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://mycluster/logs/flink-job
historyserver.archive.fs.refresh-interval: 50002.1.1.2 master
2.1.1.3 workers
2.2 hadoop ha
| r3 | s3 | s4 |
|
namenode
|
namenode
| |
|
journalnode
|
journalnode
| |
|
datanode
|
datanode
|
datanode
|
|
zookeeper
|
zookeeper
|
zookeeper
|
|
zkfc
|
zkfc
| |
|
nodemanager
|
nodemanager
|
nodemanager
|
2.2.1 配置文件
2.2.1.1 hdfs-site.xml
<configuration>
<!-- namenode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- datanode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- journalnode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 namenode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- namenode 的 rpc 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>r3:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s4:8020</value>
</property>
<!-- namenode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>r3:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s4:9870</value>
</property>
<!-- 指定 namenode 元数据在 journalnode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://r3:8485;s4:8485/mycluster</value>
</property>
<!-- 访问代理类:client 用于确定哪个 namenode 为 active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/web/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
2.2.1.2 core-site.xml
<configuration>
<!-- 把多个 namenode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultfs</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/web/zhangxiang/ha/hadoop-3.4.0/data</value>
</property>
<!-- 指定 zkfc 要连接的 zkserver 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>r3:2181,s3:2181,s4:2181</value>
</property>
<!-- 配置hdfs网页端使用的静态用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>web</value>
</property>
</configuration>
2.2.1.3 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>r3</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>r3:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>r3:8032</value>
</property>
<!-- 指定 am 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>r3:8030</value>
</property>
<!-- 指定供 nm 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>r3:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>s4</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>s4:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>s4:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>s4:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>s4:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>r3:2181,s3:2181,s4:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.zkrmstatestore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>java_home,hadoop_common_home,hadoop_hdfs_home,hadoop_conf_dir,classpath_prepend_distcache,hadoop_yarn_home,hadoop_mapred_home</value>
</property>
</configuration>
2.3 zookeeper
| r3 | s3 | s4 |
| zookeeper | zookeeper | zookeeper |
2.3.1 配置文件
2.3.1.1 zoo.cfg
首先在安装目录 /home/web/zhangxiang/zookeeper-3.8.4/ 下分别创建:zkdata、logs 这两个目录,然后在 conf 目录下使用如下命令:
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg在 zoo.cfg 文件中修改以下内容即可
ticktime=2000
initlimit=10
synclimit=5
datadir=/home/web/zhangxiang/zookeeper-3.8.4/zkdata
clientport=2181
datalogdir=/home/web/zhangxiang/zookeeper-3.8.4/logs
server.1=r3:2888:3888
server.2=s3:2888:3888
server.3=s4:2888:3888然后在 zkdata 中创建 myid 文件,并在其中增加 id , id 即 server.x 中的 x ,这个是机器的唯一标识,具体内容如下:
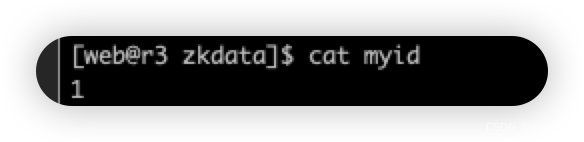
切记不同服务器节点需要按照上述中 server.x 以及 ip 对应关系设置
三、启动集群
3.1 启动zookeeper集群
必须先启动 zookeeper 集群否则会报错,一台台启动太麻烦,创建批量脚本 zk.sh :
#!/bin/bash
case $1 in
"start"){
for i in r3 s3 s4
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/home/web/zhangxiang/zookeeper-3.8.4/bin/zkserver.sh start"
done
};;
"stop"){
for i in r3 s3 s4
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/home/web/zhangxiang/zookeeper-3.8.4/bin/zkserver.sh stop"
done
};;
"status"){
for i in r3 s3 s4
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/home/web/zhangxiang/zookeeper-3.8.4/bin/zkserver.sh status"
done
};;
esac然后执行 chmod +x zk.sh 赋予其可执行权限,接下来执行以下命令就可以对集群进行 启动/停止/查看状态 操作了。
./zk.sh start/stop/status启动完成后,想要使用 jps 查看每台服务器上的进程,也可以创建批量执行脚本 jpsall.sh,然后赋予脚本可执行权限即可:
#! /bin/bash
for host in r3 s3 s4
do
echo ----------$host----------
ssh $host jps
done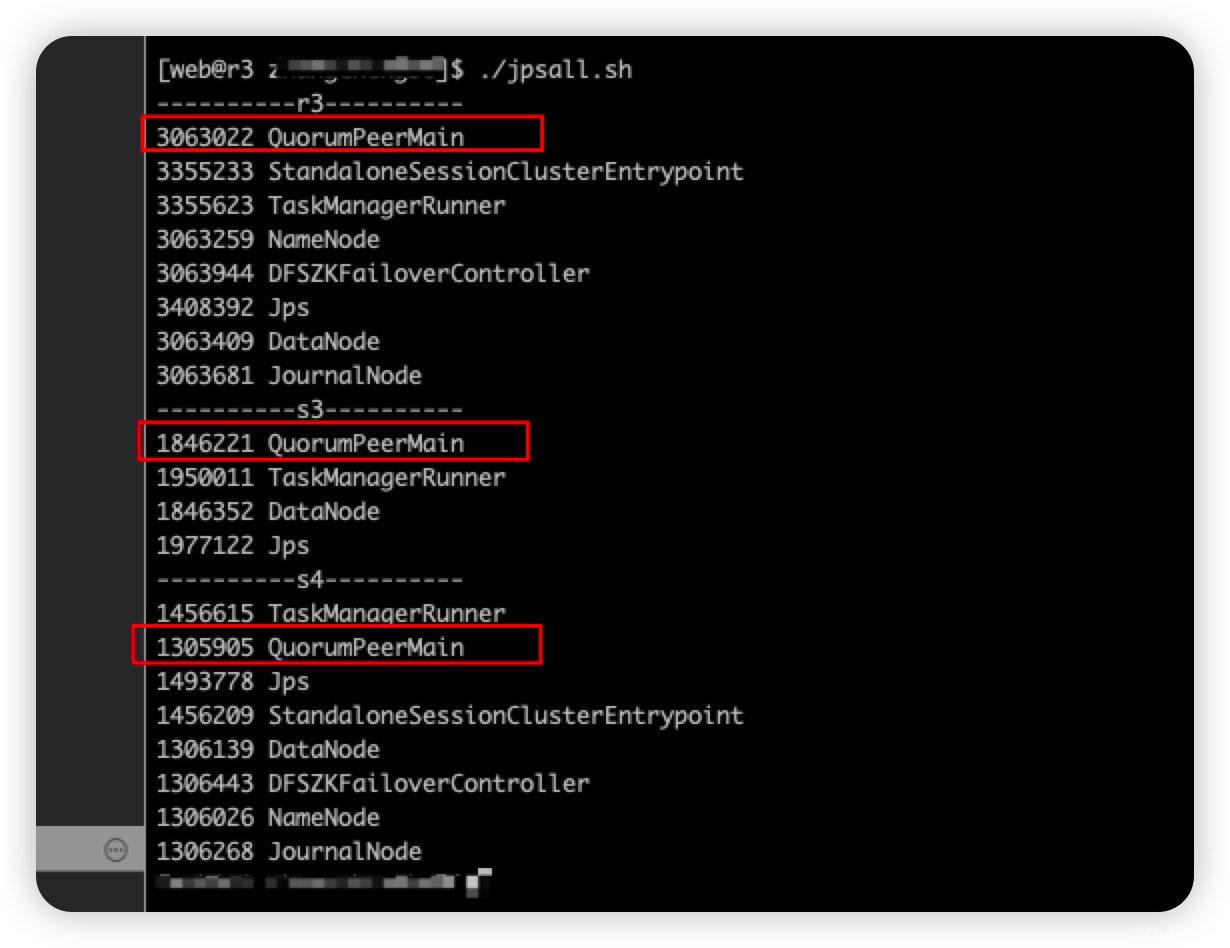
quorumpeermain 代表 zookeeper 集群在3台服务器上已经启动了。
3.2 启动hadoop集群
执行 start-dfs.sh 启动hadoop 集群。
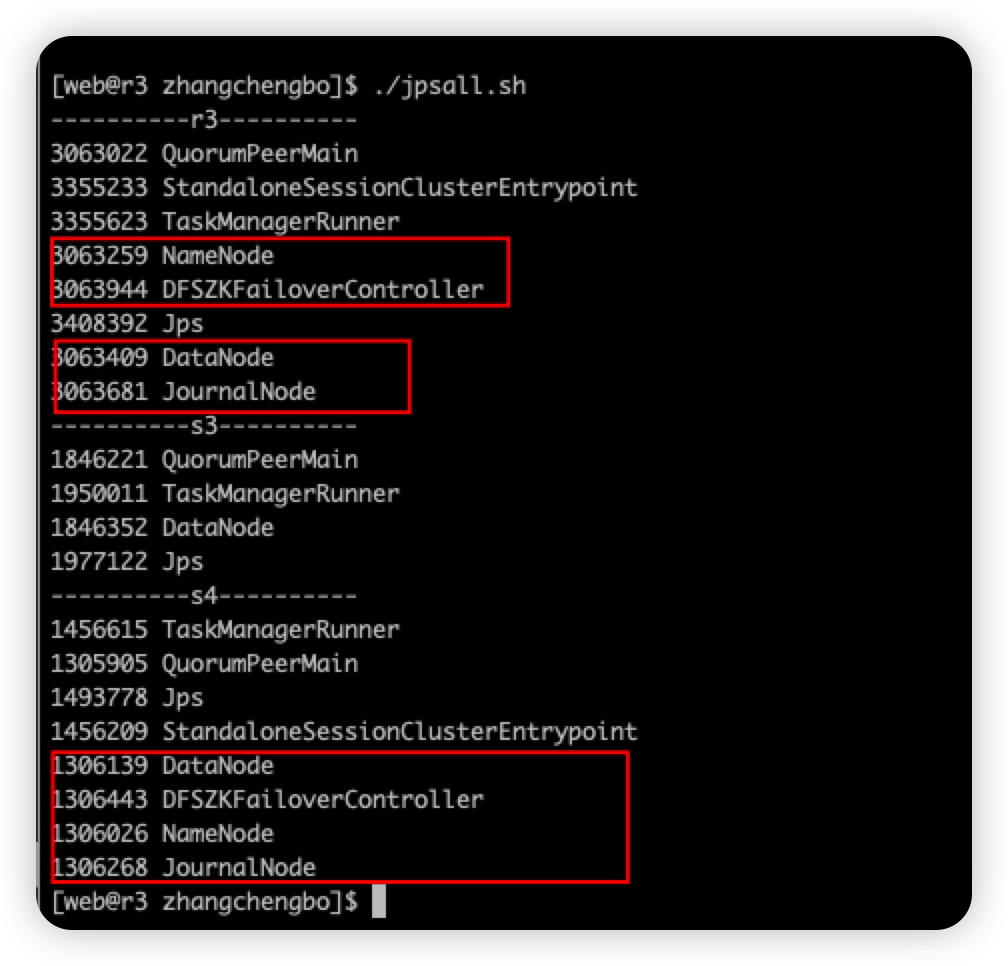
3.3 启动 flink 集群
执行 start-cluster.sh 启动 flink 集群




发表评论