aigc 009-dalle2遇见达利!文生图过程中另外一种思路。
0 论文工作
首先,遇见达利是我很喜欢的名字,达利是跟毕加索同等优秀的画家。这个名字就很有意思。
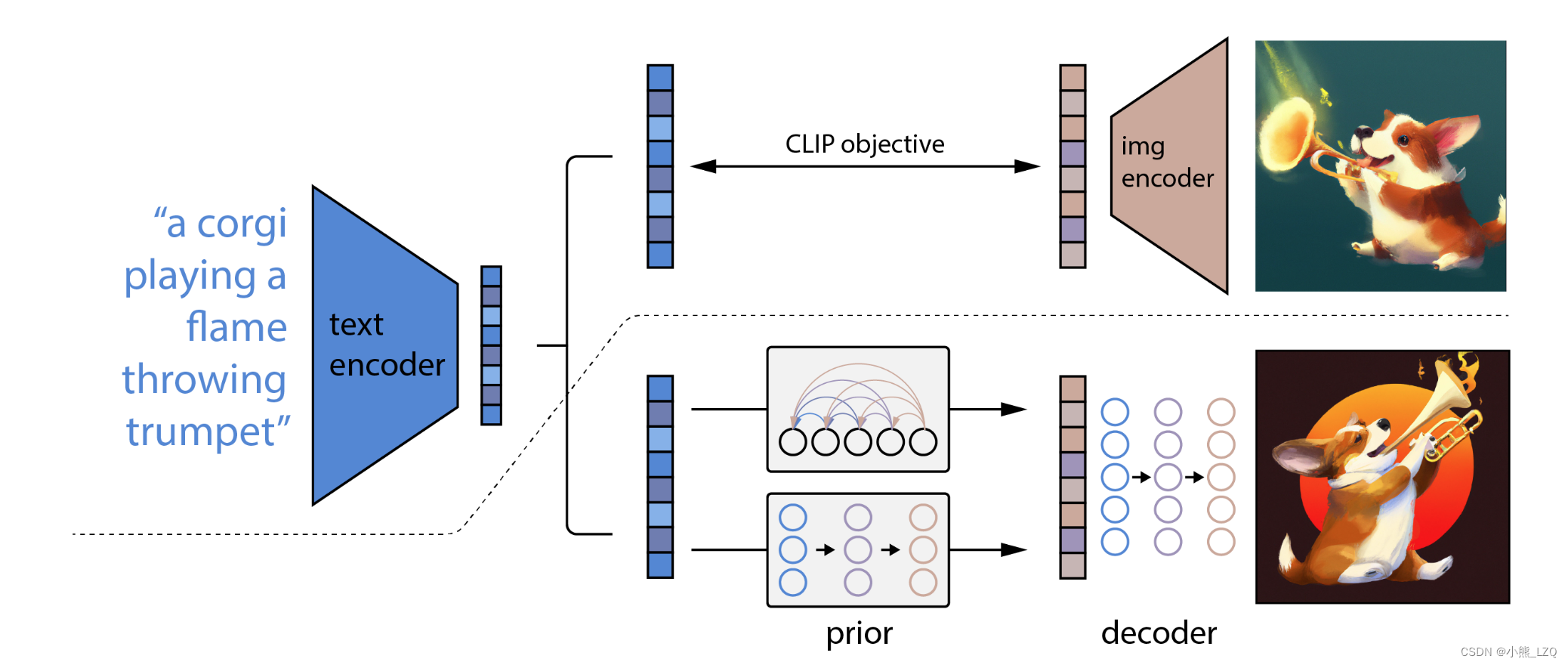
这篇论文提出了一种新颖的分层文本条件图像生成方法,该方法利用 clip(对比语言-图像预训练)的潜变量。核心思想是利用 clip 强大的图像-文本对齐能力来指导分层生成过程。该方法利用分层生成器结构,其中第一阶段根据文本提示生成低分辨率图像。后续阶段基于文本条件上采样模块逐步细化图像,最终生成与输入文本对齐的具有详细特征的高分辨率图像。
像clip这样的对比模型已经被证明可以学习同时捕获语义和风格的图像的鲁棒表示。为了利用这些表示方式进行图像生成,论文提出了一个两个-阶段模型:根据给定的文本标题生成clip图像嵌入的先验,以及根据图像嵌入生成有条件的图像的解码器。作者展示了它显式地生成图像repr插图提高了图像多样性,最小的损失在摄影真实性和标题相似性。以图像表示为条件的解码器也可以产生图像的变化,同时保留其语义和风格,但改变图像中缺少的非必要细节。此外,clip的联合嵌入空间使语言引导的图像操作零射击的方式。
openai的论文特点万物皆可自回归 对标.
论文链接
github
1 论文方法
论文中的方法包含以下关键部分:
clip 潜变量引导: 使用 clip 的文本编码器对文本提示进行编码,获得文本嵌入。此嵌入指导生成过程,确保生成的图像与输入文本的语义内容一致。
分层生成器: 生成过程是分层的,从低分辨率图像开始,并在后续阶段逐步上采样。每个阶段都使用文本条件上采样模块,根据文本嵌入和上一阶段的输出来细化图像。
多阶段细化: 分层结构允许模型逐步细化细节,捕捉输入文本的细微差别,最终产生更准确、更具视觉吸引力的结果。
这早第二行文本特征生成图像特征的过程中有两种方式,一种就是自回归,另外一种是扩散模型。现在通常认为扩散模型在图像这块给出的答案暂时比自回归好。
实现:
论文通过对各种图像生成任务进行广泛的实验来证明所提出方法的有效性。实现中利用了预训练的 clip 模型进行文本编码,以及自定义设计的分层生成器。
优点:
高质量图像生成: 分层结构和 clip 引导有助于生成高质量的图像,准确地反映输入文本。
文本保真度: 该方法确保了对输入文本提示的高保真度,捕捉语义和风格特征。
可控性: 分层结构提供了对生成过程的更大控制,可以对图像细节进行微调。
缺点:
计算成本: 由于多个上采样阶段,分层生成过程的计算量可能很大。
对细节的控制有限: 该方法虽然可以有效地捕捉一般的文本特征,但可能难以精确控制特定的视觉元素。
对 clip 的依赖: 该方法的性能高度依赖于预训练的 clip 模型的质量。
2 效果


发表评论