使用llama-factory微调大模型
github 地址
https://github.com/hiyouga/llama-factory
搭建环境
git clone --depth 1 https://github.com/hiyouga/llama-factory.git
cd llama-factory
在 llama-factory 路径下 创建虚拟环境
conda create -p ./venv python=3.10
激活环境
conda activate ./venv
在虚拟环境中安装依赖
python -m pip install -e .
下载数据集
我这里使用自带的数据
llama-factory/data/glaive_toolcall_zh_demo.json
下载模型
我这里使用 qwen-1_8b-chat
本地路径 /media/wmx/soft1/huggingface_cache/qwen-1_8b-chat
启动 webui
我这里是本地电脑 显卡是 gtx-4070ti-super 16g ,单卡
cuda_visible_devices=0 gradio_share=1 llamafactory-cli webui
配置参数
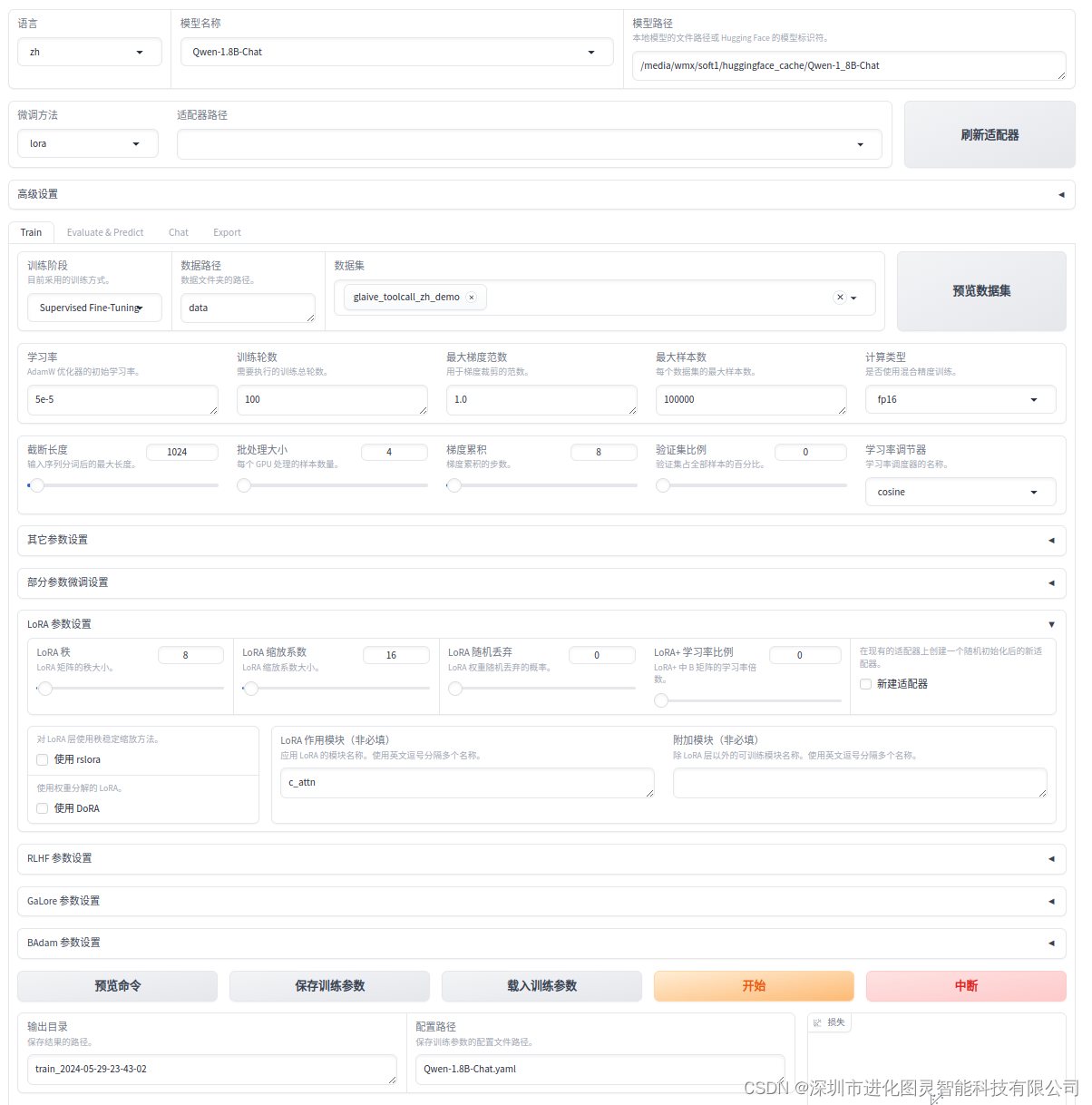
因为是qwen模型,不是qwen1.5及以后的模型 所以
train.lora_target: c_attn 这里必须这样,不然报错!!!
qwen-1.8b-chat.yaml:
top.adapter_path: []
top.booster: none
top.finetuning_type: lora
top.model_name: qwen1.5-1.8b-chat
top.quantization_bit: none
top.rope_scaling: none
top.template: qwen
top.visual_inputs: false
train.additional_target: ''
train.badam_mode: layer
train.badam_switch_interval: 50
train.badam_switch_mode: ascending
train.badam_update_ratio: 0.05
train.batch_size: 4
train.compute_type: fp16
train.create_new_adapter: false
train.cutoff_len: 1024
train.dataset:
- glaive_toolcall_zh_demo
train.dataset_dir: data
train.device_count: '1'
train.ds_offload: false
train.ds_stage: none
train.freeze_extra_modules: ''
train.freeze_trainable_layers: 2
train.freeze_trainable_modules: all
train.galore_rank: 16
train.galore_scale: 0.25
train.galore_target: all
train.galore_update_interval: 200
train.gradient_accumulation_steps: 8
train.learning_rate: 5e-5
train.logging_steps: 5
train.lora_alpha: 16
train.lora_dropout: 0
train.lora_rank: 8
train.lora_target: c_attn
train.loraplus_lr_ratio: 0
train.lr_scheduler_type: cosine
train.max_grad_norm: '1.0'
train.max_samples: '100000'
train.neftune_alpha: 0
train.num_train_epochs: '100'
train.optim: adamw_torch
train.packing: false
train.ppo_score_norm: false
train.ppo_whiten_rewards: false
train.pref_beta: 0.1
train.pref_ftx: 0
train.pref_loss: sigmoid
train.report_to: false
train.resize_vocab: false
train.reward_model: null
train.save_steps: 100
train.shift_attn: false
train.training_stage: supervised fine-tuning
train.upcast_layernorm: false
train.use_badam: false
train.use_dora: false
train.use_galore: false
train.use_llama_pro: false
train.use_rslora: false
train.val_size: 0
train.warmup_steps: 0
然后保存配置参数,然后点击开始微调



发表评论