网上大多分析llm参数的文章都比较粗粒度,对于llm的精确部署不太友好,在这里记录一下分析llm参数的过程。
首先看qkv。先上transformer原文

也就是说,当h(heads) = 1时,在默认情况下,
w
i
q
w_i^q
wiq、
w
i
k
w_i^k
wik、
w
i
v
w_i^v
wiv都是2维方阵,方阵维度是
d
m
o
d
e
l
×
d
m
o
d
e
l
d_{model} \times d_{model}
dmodel×dmodel.
结合llama源码 (https://github.com/facebookresearch/llama/blob/main/llama/model.py)
class modelargs:
dim: int = 4096
n_layers: int = 32
n_heads: int = 32
n_kv_heads: optional[int] = none
vocab_size: int = -1 # defined later by tokenizer
multiple_of: int = 256 # make swiglu hidden layer size multiple of large power of 2
ffn_dim_multiplier: optional[float] = none
norm_eps: float = 1e-5
max_batch_size: int = 32
max_seq_len: int = 2048
# ...
class attention(nn.module):
"""multi-head attention module."""
def __init__(self, args: modelargs):
"""
initialize the attention module.
args:
args (modelargs): model configuration parameters.
attributes:
n_kv_heads (int): number of key and value heads.
n_local_heads (int): number of local query heads.
n_local_kv_heads (int): number of local key and value heads.
n_rep (int): number of repetitions for local heads.
head_dim (int): dimension size of each attention head.
wq (columnparallellinear): linear transformation for queries.
wk (columnparallellinear): linear transformation for keys.
wv (columnparallellinear): linear transformation for values.
wo (rowparallellinear): linear transformation for output.
cache_k (torch.tensor): cached keys for attention.
cache_v (torch.tensor): cached values for attention.
"""
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is none else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
计算出
self.n_kv_heads = h = 32
self.head_dim = 4096/32=128
所以
w
i
q
w_i^q
wiq、
w
i
k
w_i^k
wik、
w
i
v
w_i^v
wiv 大小都为(4096, 128).(在未拆分前
w
q
w^q
wq,
w
k
w^k
wk和
w
v
w^v
wv都是
(
d
i
m
,
d
i
m
)
=
(
4096
,
4096
)
(dim, dim) = (4096,4096)
(dim,dim)=(4096,4096)大小)。
q
,
k
,
v
q,k,v
q,k,v的大小都是
(
n
c
t
x
,
d
i
m
)
=
(
2048
,
4096
)
(n_{ctx}, dim) = (2048,4096)
(nctx,dim)=(2048,4096) (在多头公式里。在self-attention里,其实他们都是同一个值:输入x),所以
q
×
w
i
q
q×w_i^q
q×wiq 和
k
×
w
i
k
k×w_i^k
k×wik 和
q
×
w
i
q
q×w_i^q
q×wiq 都是
(
n
c
t
x
,
d
k
)
=
(
2048
,
128
)
(n_{ctx}, d_k)=(2048,128)
(nctx,dk)=(2048,128)。带入原文attention公式后,大小为(2048, 128)不变。attention不改变大小(在默认
d
k
=
d
v
d_k=d_v
dk=dv情况下)。
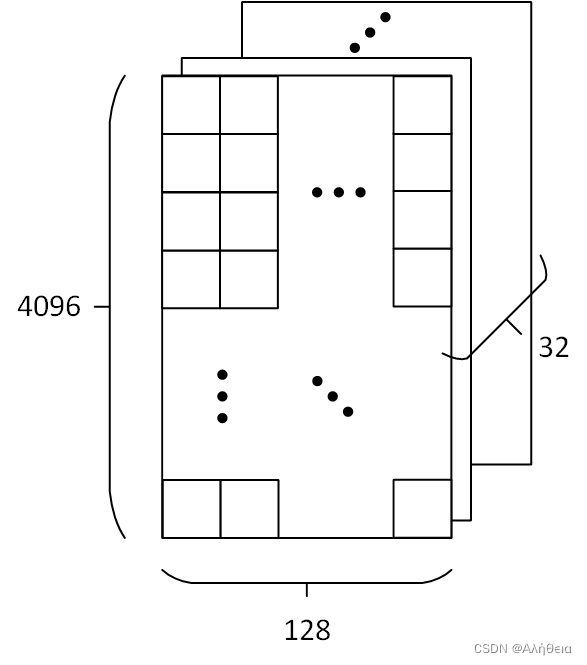
经过cancat,分开的头又合并,大小变为(2048, 4096)矩阵,经过 w o w^o wo (大小是(4096,4096))全连接,还是(2048, 4096)矩阵。
然后看feed forward.根据源码,
class feedforward(nn.module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: optional[float],
):
"""
initialize the feedforward module.
args:
dim (int): input dimension.
hidden_dim (int): hidden dimension of the feedforward layer.
multiple_of (int): value to ensure hidden dimension is a multiple of this value.
ffn_dim_multiplier (float, optional): custom multiplier for hidden dimension. defaults to none.
attributes:
w1 (columnparallellinear): linear transformation for the first layer.
w2 (rowparallellinear): linear transformation for the second layer.
w3 (columnparallellinear): linear transformation for the third layer.
"""
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not none:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = columnparallellinear(
dim, hidden_dim, bias=false, gather_output=false, init_method=lambda x: x
)
self.w2 = rowparallellinear(
hidden_dim, dim, bias=false, input_is_parallel=true, init_method=lambda x: x
)
self.w3 = columnparallellinear(
dim, hidden_dim, bias=false, gather_output=false, init_method=lambda x: x
)
def forward(self, x):
return self.w2(f.silu(self.w1(x)) * self.w3(x))
multiattention layer过后,经过加法和normlayer(rms norm),进入feed_forward前馈网络。注意这里的前馈网络其中一个维度会有8/3≈2.7的放缩,然后multiple_of又保证必须是256的倍数,所以这里算出来hidden_dim是256的倍数中与8/3*4096最接近的,是11008。以这里的w1,w3大小为(4096,11008),w2大小为(11008,4096). 输出结果大小
整个decode layer计算如图所示,
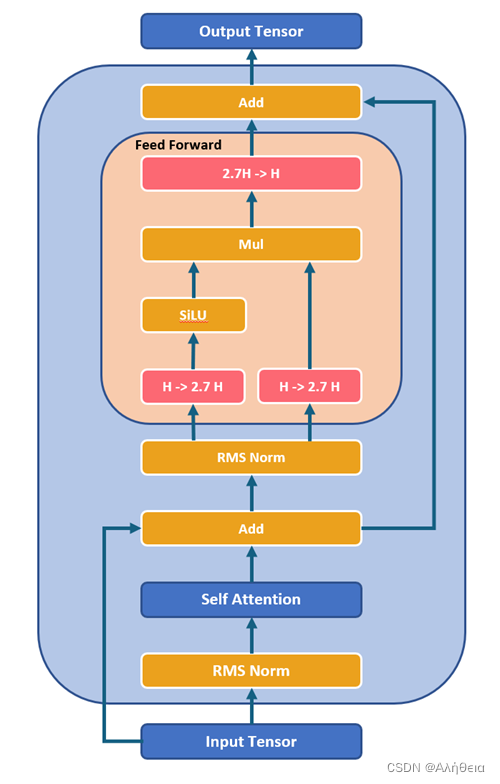
来源:https://github.com/microsoft/llama-2-onnx/blob/main/images/decoderlayer.png


{kind=link}
发表评论