自然语言处理(nlp)和大规模语言模型(llm)是理解和生成人类语言的两种主要方法。本文将介绍传统nlp和llm的介绍、运行步骤以及它们之间的比较,帮助新手了解这两个领域的基础知识。

传统自然语言处理(nlp)

定义: 是一种利用计算机科学和语言学的技术,通过规则和算法来理解和生成人类语言的方法。传统nlp方法注重使用手工构建的规则和特征来分析和处理文本。这种方法主要依赖于语言学家的知识和经验。
主要技术:
- 词法分析(tokenization): 将文本拆分为单词或词组。
- 词性标注(pos tagging): 给每个词分配词性标签,如名词、动词等。
- 命名实体识别(ner): 识别文本中的专有名词,如人名、地名等。
- 句法分析(parsing): 分析句子的语法结构。
- 语义分析(semantic analysis): 理解句子的含义,包括词义消歧和语义角色标注。
- 情感分析(sentiment analysis): 分析文本中的情感倾向。
- 机器翻译(machine translation): 将一种语言翻译成另一种语言。
运行步骤:(为了更容易理解,我们可以把传统nlp的步骤比作一系列处理文本的流程,就像加工原材料一样,逐步将生涩的文本加工成计算机可以理解和使用的格式。以下是对这些步骤的详细解释:)
-
文本预处理:
-
特征提取:
-
语法和语义分析:
-
高级任务:
过程: 传统nlp通常涉及多个模块,每个模块使用不同的算法和规则来处理特定任务。这种方法需要语言学专家的参与来设计和优化各个模块的规则和算法。
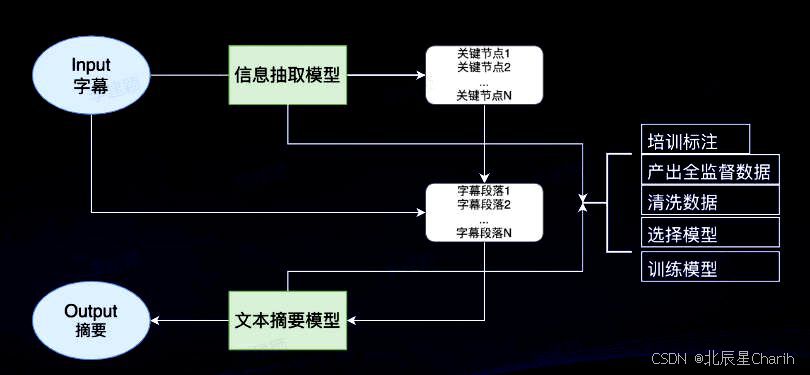
应用: 传统nlp应用广泛,包括文本分类、信息检索、问答系统、语音识别和合成等。
大规模语言模型(llm)

定义: 大规模语言模型是一种基于深度学习和神经网络技术,通过在海量文本数据上进行训练来生成和理解人类语言的模型。与传统nlp依赖手工构建的规则和特征不同,llm依赖于数据驱动的方法,通过自动学习数据中的语言模式和结构来实现对语言的处理。代表性的模型有openai的gpt系列和google的bert。
主要技术:
- 神经网络(neural networks): 特别是深度学习中的递归神经网络(rnns)和变换模型(transformers)。
- 预训练和微调(pre-training and fine-tuning): 先在大量文本上进行无监督预训练,然后在特定任务上进行有监督微调。
- 自注意力机制(self-attention mechanism): 允许模型关注输入序列中的不同部分,捕捉长距离依赖关系。
- 大规模训练数据: 使用海量文本数据进行训练,覆盖广泛的知识和语言现象。
运行步骤:(为了更容易理解,我们可以把大规模语言模型的工作过程比作一个学习语言的大脑,逐步从大量的阅读和实践中学会理解和生成语言。以下是对这些步骤的详细解释:)
-
预训练(pre-training):
-
微调(fine-tuning):
-
推理(inference):
过程: llm依赖于大规模数据和计算资源,通过深度学习模型自动学习语言特征和知识。训练和微调过程通常需要大量计算能力和时间。
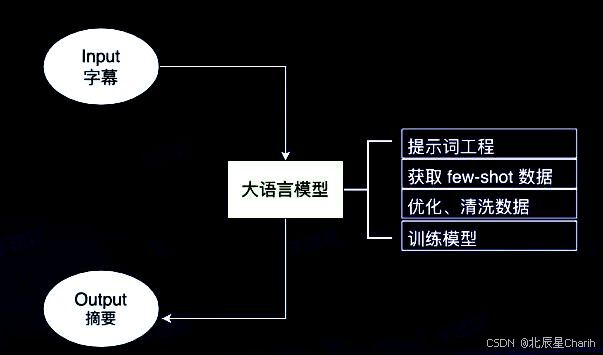
应用: llm广泛应用于生成文本、对话系统、机器翻译、文本摘要、情感分析和其他nlp任务。
传统nlp与llm的比较
| 特点 | 传统nlp | 大规模语言模型(llm) |
|---|---|---|
| 技术基础 | 规则和手工算法 | 深度学习和神经网络 |
| 依赖 | 语言学理论和人工特征提取 | 海量数据和计算资源 |
| 性能 | 在特定任务上表现较好 | 通用性强,多任务性能优越 |
| 灵活性 | 需要为不同任务定制方法 | 通过微调适应不同任务 |
| 可解释性 | 具有一定可解释性 | 难以解释内部工作机制 |
| 数据需求 | 对数据需求较低 | 对数据需求巨大 |
| 开发复杂度 | 需要领域专家设计规则和特征 | 需要大量计算资源和数据 |
| 应用范围 | 专用于特定任务 | 广泛适用于多种任务 |
总结
传统nlp和大规模语言模型各有优势和劣势。传统nlp方法依赖于语言学家的知识和经验,通过手工构建的规则和特征来实现对文本的处理,适用于特定任务,但在处理复杂语言现象时可能表现不足。与传统nlp方法依赖手工构建的规则和特征不同,llm依赖数据驱动的方法,通过预训练和微调实现对语言的理解和生成。llm通过深度学习和大量数据训练,具有更强的通用性和表现力,但需要大量的计算资源和数据支持。随着技术的发展,llm在很多应用中已经逐渐取代了传统nlp方法,但在某些需要高可解释性和低资源消耗的场景下,传统nlp仍然具有其优势。


发表评论