目录
一、rebel解析非结构化数据
模型介绍
rebel模型是为端到端语言生成(rebel)关系提取而设计的。它利用基于 bart 模型的自回归 seq2seq 方法,对200多种不同的关系类型执行端到端关系提取。这种方法通过将三联体表示为一个文本序列来简化关系提取。该模型特别适用于从原始文本中提取关系三元组,这在填充知识库或事实核查等信息抽取任务中至关重要。
三元组
三元组是指由三个元素组成的有序组合,通常用于表示关系或事实。在自然语言处理中,三元组通常用于表示实体之间的关系,例如“约翰是玛丽的兄弟”可以表示为一个三元组(约翰,兄弟,玛丽)。在关系抽取任务中,目标是从文本中提取这样的三元组,以便将文本转换为结构化数据,例如知识库或图数据库。
核心代码
加载reble模型
triplet_extractor = pipeline('text2text-generation', model='babelscape/rebel-large', tokenizer='babelscape/rebel-large', device='cuda:0')提取三元组关系核心函数
def extract_triplets(input_text):
text = triplet_extractor.tokenizer.batch_decode([triplet_extractor(input_text, return_tensors=true, return_text=false)[0]["generated_token_ids"]])[0]
triplets = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
triplets.append((subject.strip(), relation.strip(), object_.strip()))
return triplets
二、llamaindex 构建知识图谱
rag框架llamaindex核心——各种索引应用分析-csdn博客
#用知识图谱索引从documents即paul_graham_essay.txt里读取内容
index = knowledgegraphindex.from_documents(documents, kg_triplet_extract_fn=extract_triplets, service_context=service_context)
paul_graham_essay.txt的主要内容如下:
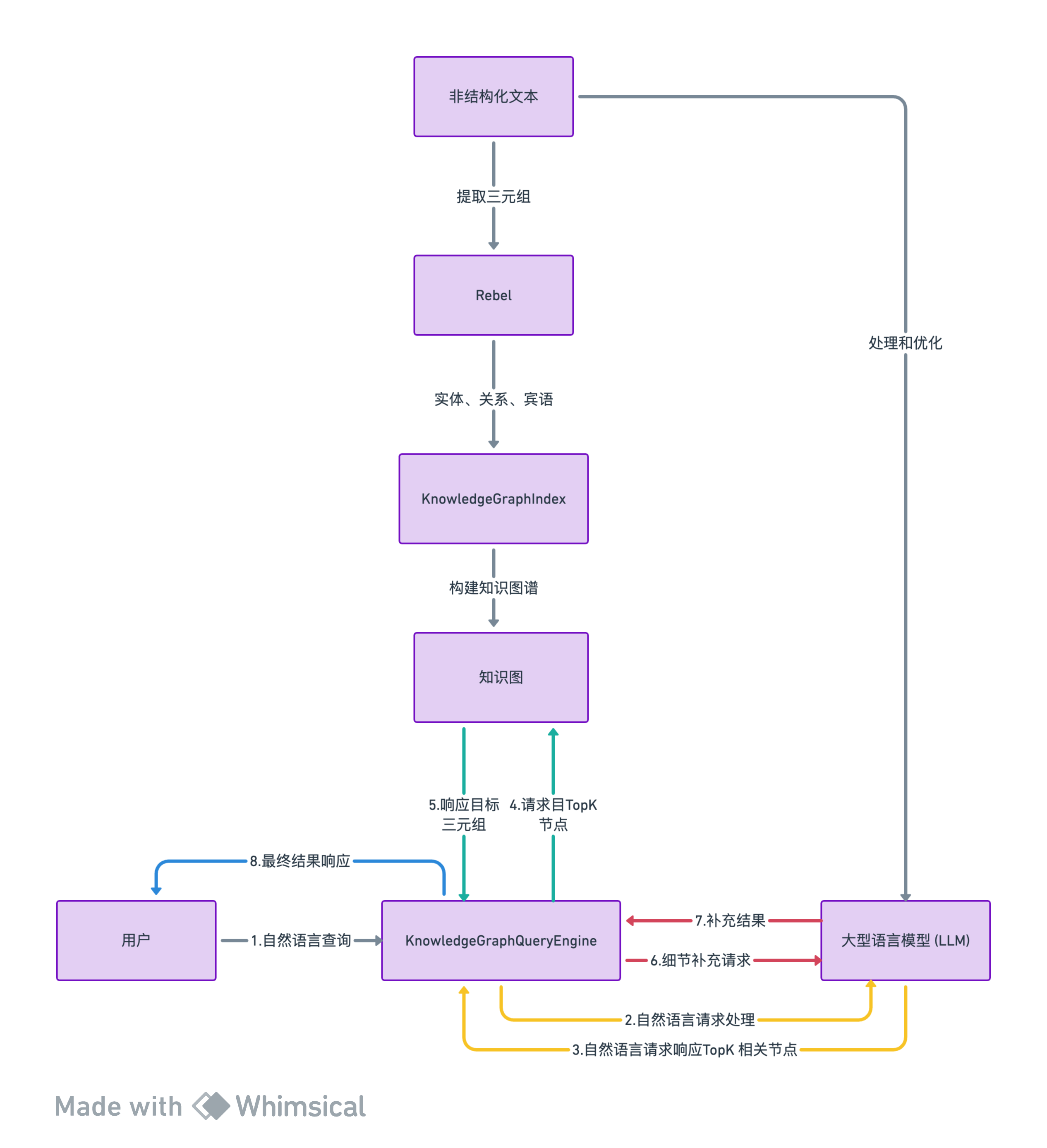
三、整体处理流程
-
提取三元组: 使用rebel模型提取文本中的三元组信息。rebel直接处理非结构化文本,识别出其中的实体(subjects)、关系(relations)和宾语(objects)。
-
构建知识图谱: 在
knowledgegraphindex中,这些三元组被用来构建知识图谱。 -
查询引擎:knowledgegraphqueryengine:作为统一的查询和响应入口
-
llm: llm在查询知识图谱时发挥作用。用户可以通过自然语言提问,llm帮助解析这些查询,找到与查询相关的三元组。
-
处理和优化: 在构建知识图谱时,llm可能用于进一步处理和优化rebel提取的三元组,例如,通过提炼、概括或补充信息来增强图谱的质量。
四、运行效果
五、完整代码
"""rebel + llamaindex 知识图谱查询引擎
llamaindex 支持构建和查询跨知识图谱。它通过提取和存储三元组(`(subject, relation, object)`)的形式工作。然后在查询时,使用查询文本中的关键词来获取三元组以及它们来自的文本片段来回答查询。
默认设置将使用 llm 来构建知识图谱,这可能
- 慢
- 使用大量 token
为了解决这个问题,你可以插入任何函数来替换默认的三元组提取函数!在这个笔记本中,我们演示使用 [babelscape/rebel-large]( 来为我们提取三元组。这是一个轻量级模型,专门为知识图谱提取三元组进行了微调。
了解更多关于使用 llamaindex 与知识图谱的信息,请访问我们的文档
- [基本知识图谱索引](
- [知识图谱索引 + 向量索引]
- [知识图谱索引 + nebula]
- [查询现有的 nebula kgs]
- [知识图谱索引 + kuzu]
:## 依赖
"""
#!sudo apt install python3.10-venv
#!python3 -m venv openai_env
!source openai_env/bin/activate
!pip install llama-index transformers pyvis networkx
!pip install fastapi kaleido python-multipart uvicorn cohere
!pip install openai
!wget
"""## rebel pipeline
我们实例化了 `rebel-large` 模型的 pipeline。遵循官方模型文档,我们还构建了一个函数,将输出解析为三元组列表,形式为 `(subj, rel, obj)`。
**注意:** 如果你不使用 `cuda`,请从 pipeline 构造函数中删除 `device` 参数。
"""
from transformers import pipeline
triplet_extractor = pipeline('text2text-generation', model='babelscape/rebel-large', tokenizer='babelscape/rebel-large', device='cuda:0')
# 函数用于解析生成的文本并提取三元组
# rebel 输出特定格式。这段代码大部分是从rebel模型复制过来的!
def extract_triplets(input_text):
text = triplet_extractor.tokenizer.batch_decode([triplet_extractor(input_text, return_tensors=true, return_text=false)[0]["generated_token_ids"]])[0]
triplets = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
triplets.append((subject.strip(), relation.strip(), object_.strip()))
return triplets
"""## 构建图谱
在这里,我们将构建索引,并利用 `rebel` 提取三元组。
"""
import openai
import os
# 使用 openai 生成自然语言响应,基于 paul graham 的文章
os.environ["openai_api_key"] = "sk-xxxxxx"
os.environ["openai_api_base"] = ""
openai.api_key = os.environ["openai_api_key"]
openai.api_base = os.environ["openai_api_base"]
from llama_index import simpledirectoryreader, knowledgegraphindex, servicecontext
documents = simpledirectoryreader(input_files=["./paul_graham_essay.txt"]).load_data()
from llama_index.llms import openai
# rebel 支持最多 512 个输入 tokens,但较短的序列也可以工作得很好
service_context = servicecontext.from_defaults(llm=openai(model_name="gpt-3.5-turbo"), chunk_size=256)
#用知识图谱索引从documents即paul_graham_essay.txt里读取内容
index = knowledgegraphindex.from_documents(documents, kg_triplet_extract_fn=extract_triplets, service_context=service_context)
"""## 查询
在查询期间,从查询文本中提取关键词,并用于查找具有相同 `subj` 的三元组(及其关联文本片段)。
"""
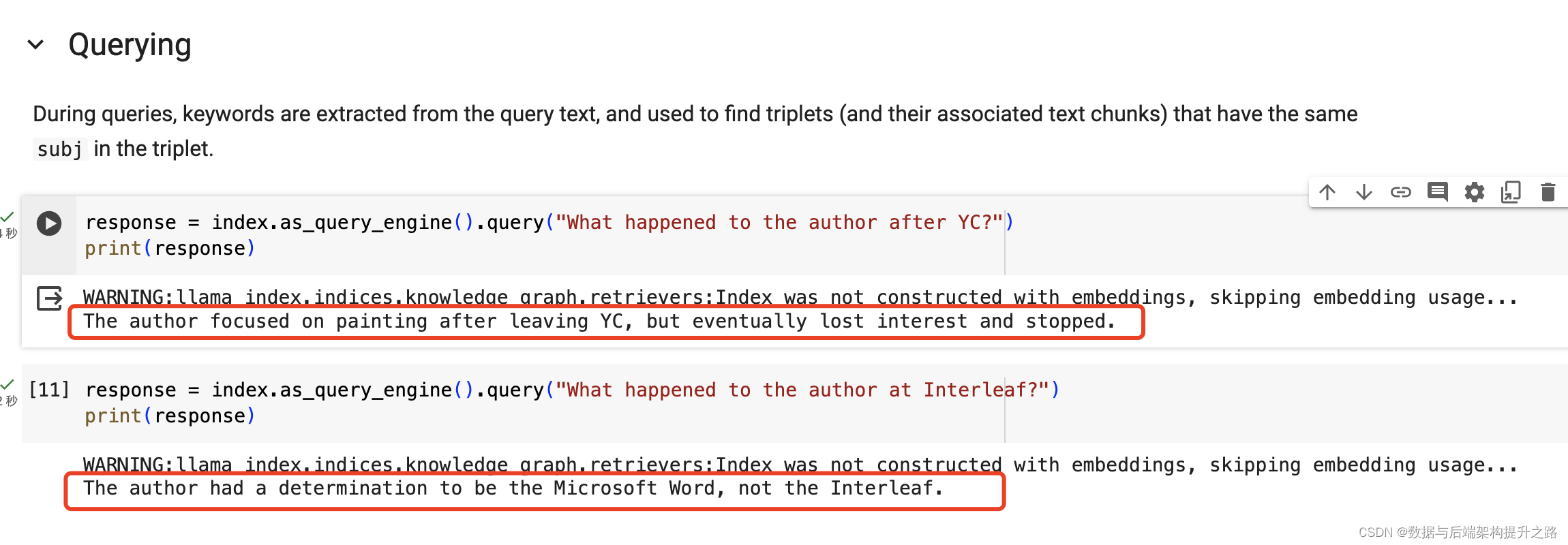
response = index.as_query_engine().query("yc 之后作者发生了什么?")
print(response)
response = index.as_query_engine().query("作者在 interleaf 发生了什么?")
print(response)
"""## 可视化
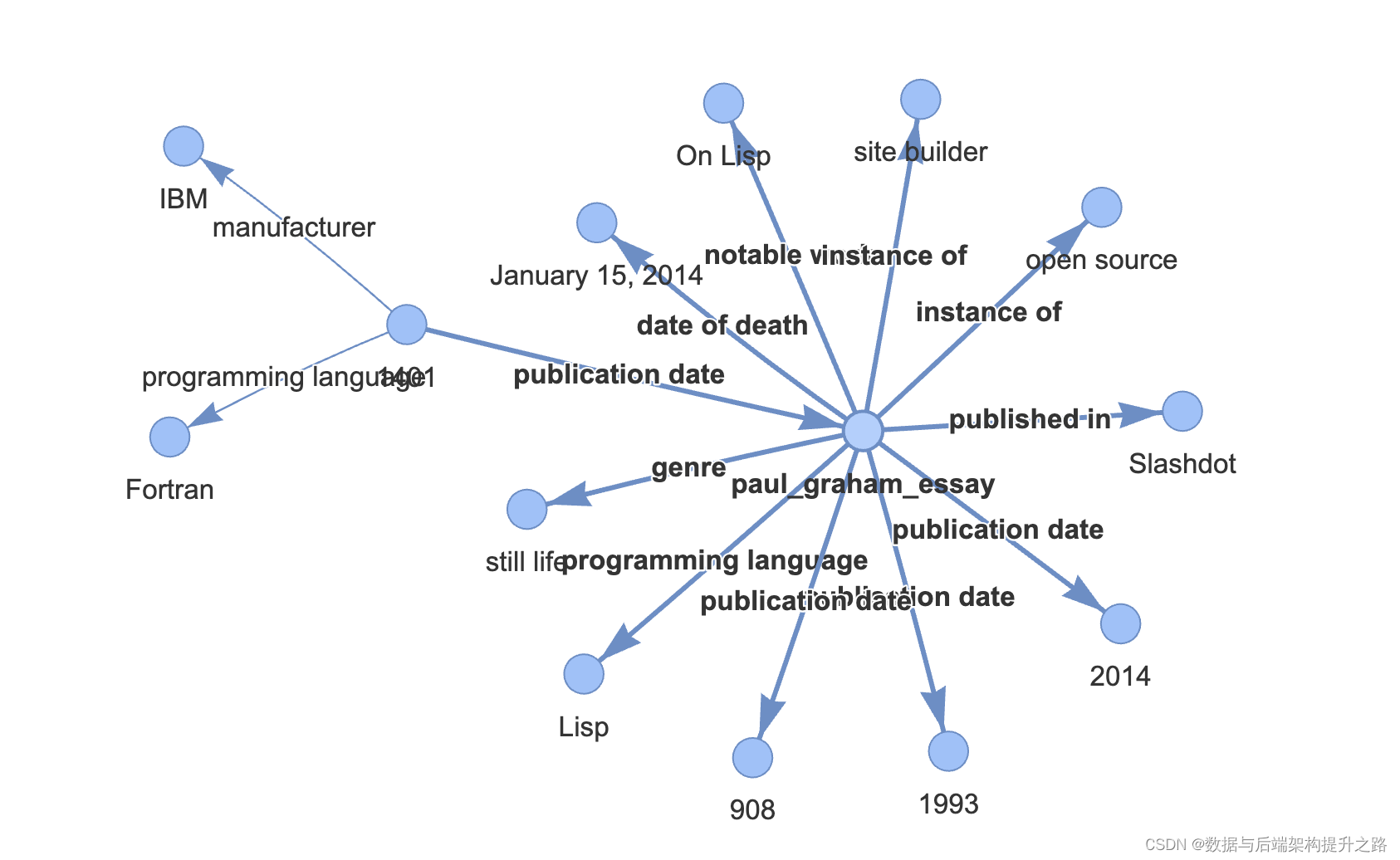
我们可以使用 networkx 在笔记本中显示图谱!
虽然并非所有三元组都是完美或正确的,但 `rebel` 在提取适当的 `subj` 值方面做得很好,这有助于查询引擎定位用于回答问题的文本片段!
"""
from pyvis.network import network
g = index.get_networkx_graph()
net = network(notebook=true, cdn_resources="in_line", directed=true)
net.from_nx(g)
net.show('/content/example.html')
import ipython
ipython.display.html(filename='/content/example.html')
```六、知识拓展
本文中用到了llamaindex内置的知识图谱,实际生产环境一般不这么干需要引入外部知识谱图库nebulagraph,知识图谱并非所有情况都有优势,知识图谱的答案非常简洁(仅使用三元组),但仍然提供了丰富的信息。许多问题并不包含大块的小颗粒知识。在这些情况下,额外的知识图检索器可能没有那么有用,可以考虑用vectorstoreindex。
vectorstoreindex更多关注于基于向量的数值计算和相似度搜索,knowledgegraphindex则侧重于图形数据的结构化查询和关系探索。
二者的选择取决于特定的应用需求和数据特点



发表评论