前言
默认情况下,elasticsearch集群中每个分片的搜索结果数量限制为10000。这是为了避免潜在的性能问题。
但是我们 在实际工作过程中时常会遇到 需要深度分页,以及查询批量数据更新的情况
问题:当请求form + size >10000 时,请求直接报错
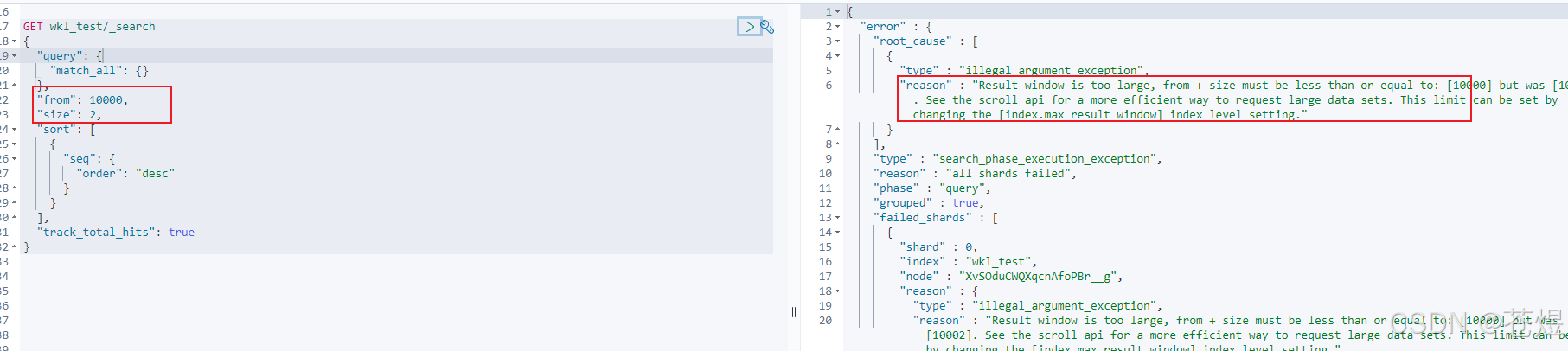
1:修改max_result_window 参数(不推荐)
在此方案中,我们建议仅限于测试用,生产禁用,毕竟当数据量大的时候,过大的数据量可能导致es的内存溢出,直接崩掉,一年绩效白干。
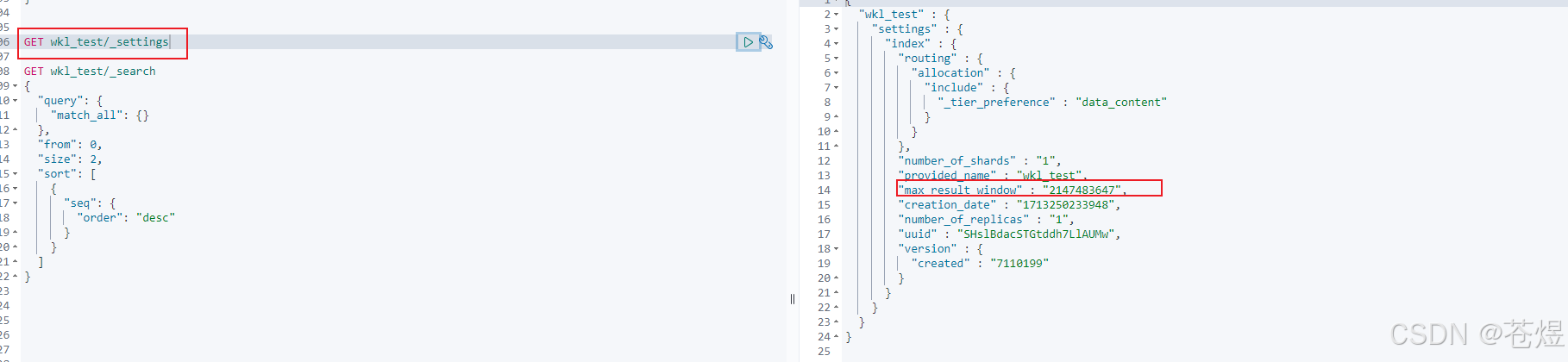
put wkl_test/_settings
{
"index":{
"max_result_window":2147483647
}
}
查看索引的 settings
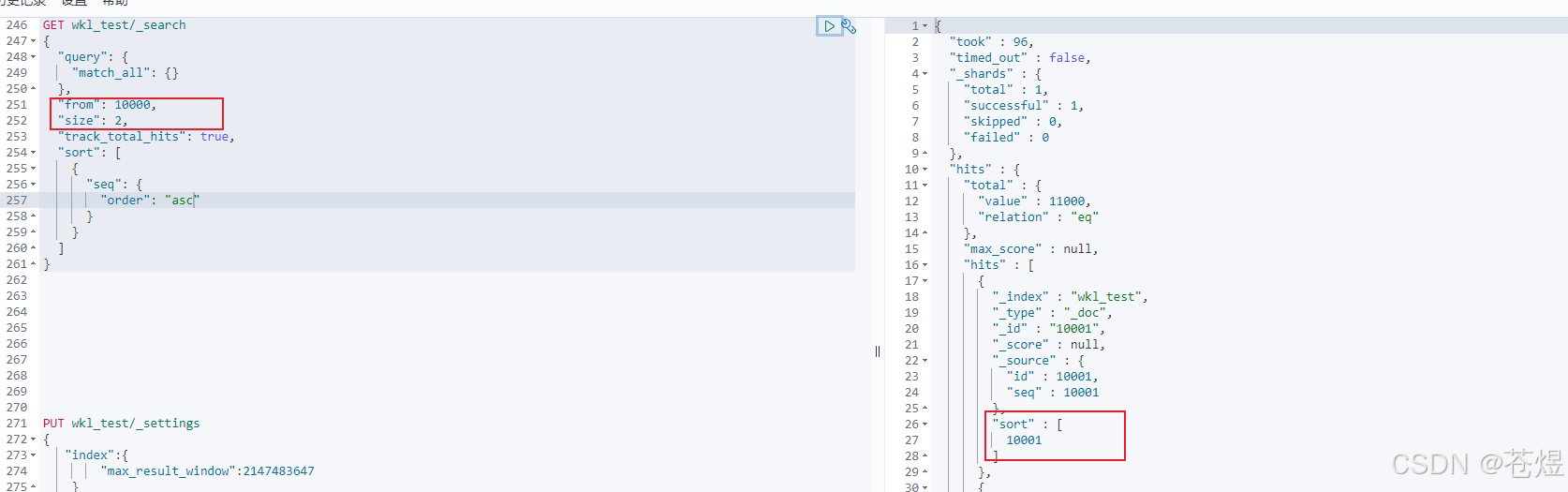
重新查数据:
2:使用游标 scroll api
使用scroll api:scroll api可以帮助我们在不加载所有数据的情况下获取所有结果。它会在后台执行查询以获取滚动id,并将其用于进行后续查询。这样就可以一次性获取所有结果,而不必担心限制
es语句查询
在游标方案中,我们只需要在第一次拿到游标id,之后通过游标就能唯一确定查询,在这个查询中通过我们指定的 size 移动游标,具体操作看看下面实操。
- 游标查询,设置游标有效时间,有效时间内,游标都可以使用,过期就不行了
get wkl_test/_search?scroll=5m
{
"query": {
"match_all": {}
},
"sort": [
{
"seq": {
"order": "asc"
}
}
],
"size": 200
}
- 上面操作中通过游标的结果返回
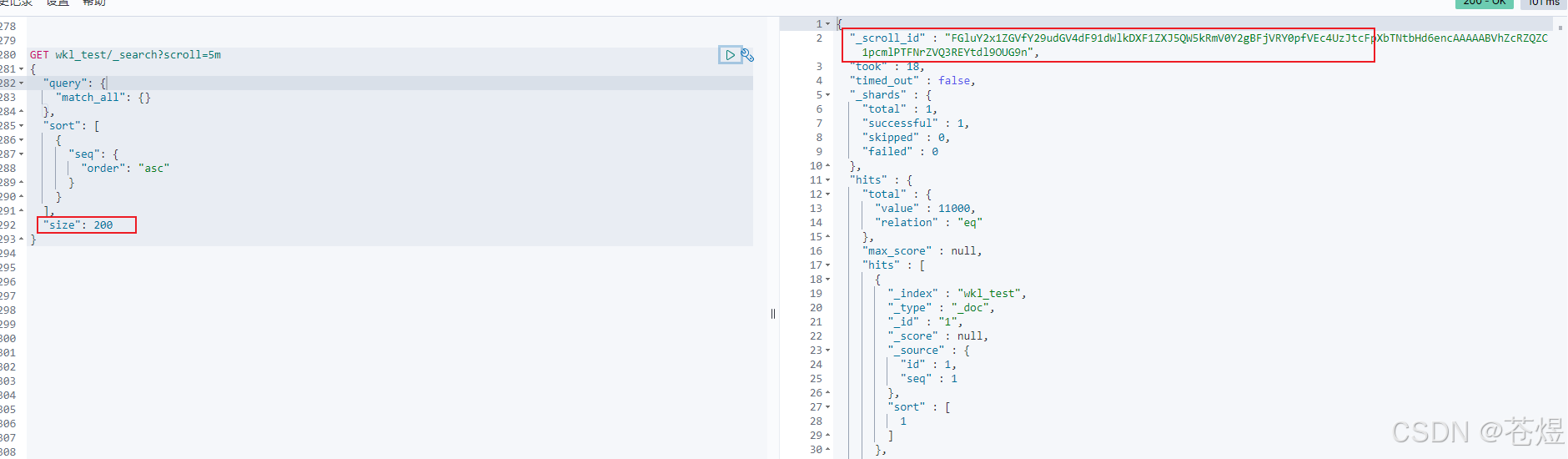
- 之后将_scroll_id 复制到窗口,就可以不端通过这个_scroll_id 进行之前设置的页数不断翻页
以此类推,后面每次滚屏都把前一个的scroll_id复制过来。注意到,后续请求时没有了index信息,size信息等,这些都在初始请求中,只需要使用scroll_id和scroll两个参数即可。
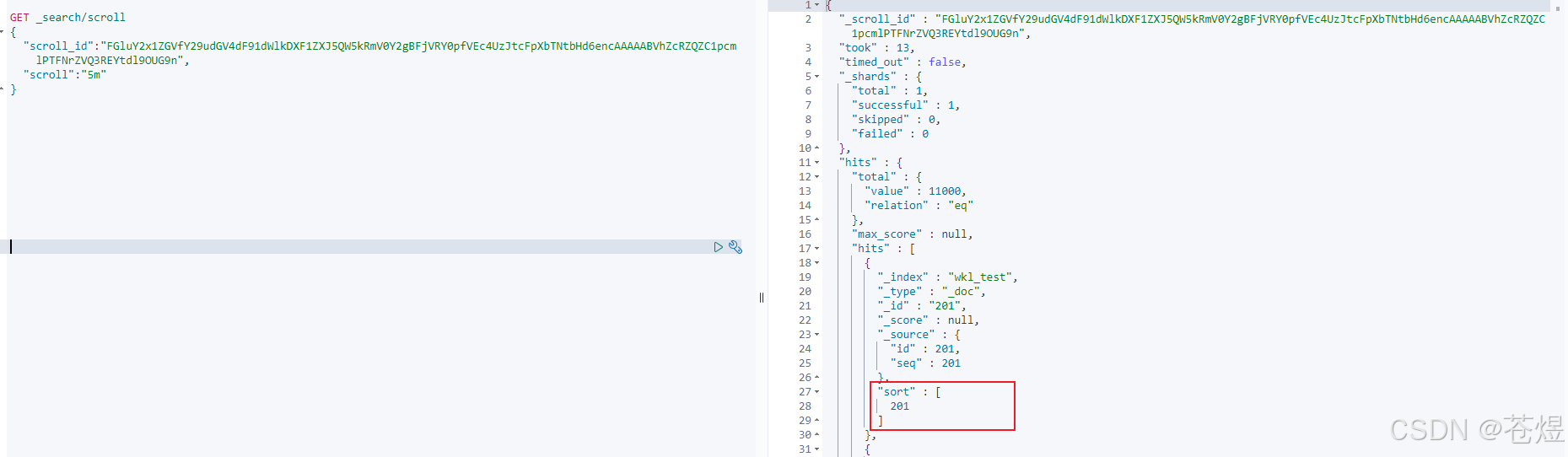
注意,此时游标移动了,所以我们可以通过游标的方式不断后移,直到移动到我们想要的 from+size 范围内。再次点击
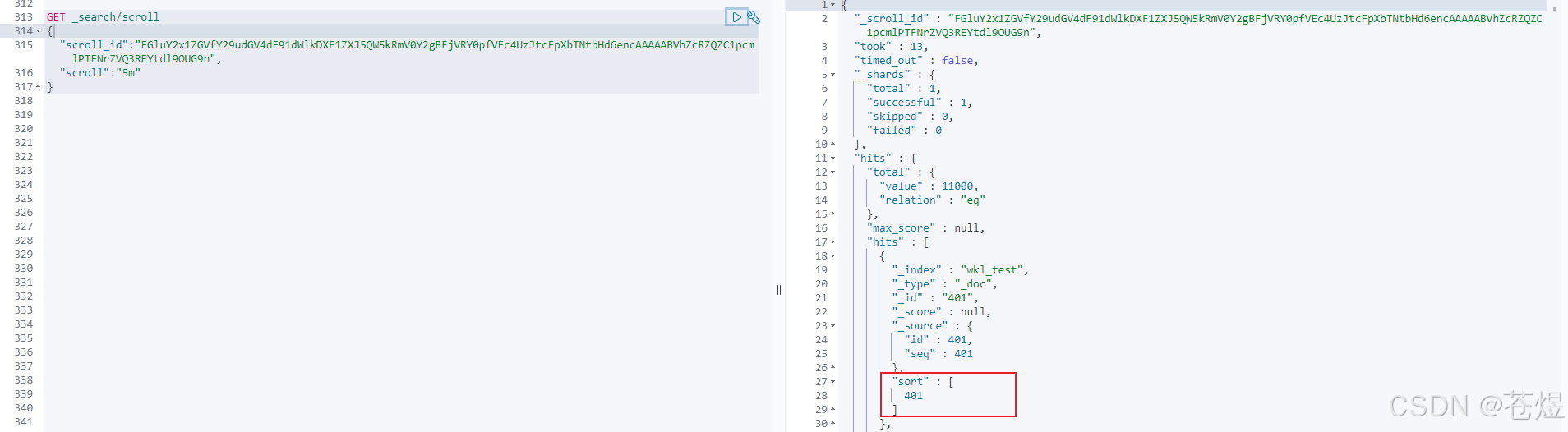
java实现
@test
public void testscroll(){
resthighlevelclient resthighlevelclient ;
boolquerybuilder boolquerybuilder = querybuilders.boolquery();
boolquerybuilder.mustnot(querybuilders.existsquery("seq"));
try {
//滚动查询的scroll,设置请求滚动时间窗口时间
scroll scroll = new scroll(timevalue.timevaluemillis(180000));
searchsourcebuilder sourcebuilder = new searchsourcebuilder();
//加入query语句
sourcebuilder.query(boolquerybuilder);
//每次滚动的长度
sourcebuilder.size(size);
//加入排序字段
sourcebuilder.sort("id", sortorder.desc);
//构建searchrequest
//加入scroll和构造器
searchrequest searchrequest = new searchrequest()
.indices("wkl_test")
.source(sourcebuilder)
.scroll(scroll);
//存储scroll的list
list<string> scrollidlist = new arraylist<>();
//执行首次检索
searchresponse searchresponse = resthighlevelclient.search(searchrequest, requestoptions.default);
//首次检索返回scrollid,用于下一次的滚动查询
string scrollid = searchresponse.getscrollid();
//拿到hits结果
searchhit[] hits = searchresponse.gethits().gethits();
long value = searchresponse.gethits().gettotalhits().value;
//保存返回结果list大小
long resultsize = 0l;
scrollidlist.add(scrollid);
try {
//滚动查询将searchhit封装到result中
while (arrayutils.isnotempty(hits) && hits.length > 0) {
bulkrequest bulkrequest = new bulkrequest();
jsonarray esarray = new jsonarray();
for (searchhit hit : hits) {
string sourceasstring = hit.getsourceasstring();
string index = hit.getindex();
jsonobject jsonobject = jsonobject.parseobject(sourceasstring);
string seq = jsonobject.getstring("seq");
if(stringutils.isblank(seq) ){
esarray.add(jsonobject);
string uuid = jsonobject.getstring("id");
jsonobject.put("is_del",1);
bulkrequest.add(new updaterequest(index, uuid).doc(jsonobject));
}
}
resultsize = resultsize+hits.length;
//发送请求
//实时更新
bulkrequest.setrefreshpolicy(writerequest.refreshpolicy.immediate);
bulkresponse bulk = resthighlevelclient.bulk(bulkrequest, requestoptions.default);
system.out.println(bulk.gettook()+"-------"+bulk.getitems().length);
//说明滚动完了,返回结果即可
if (resultsize > 20000) {
break;
}
//继续滚动,根据上一个游标,得到这次开始查询位置
searchscrollrequest searchscrollrequest = new searchscrollrequest(scrollid);
searchscrollrequest.scroll(scroll);
//得到结果
searchresponse searchscrollresponse = resthighlevelclient.scroll(searchscrollrequest, requestoptions.default);
//定位游标
scrollid = searchscrollresponse.getscrollid();
hits = searchscrollresponse.gethits().gethits();
scrollidlist.add(scrollid);
}
system.out.println("----彻底结束了-----");
} finally {
//清理scroll,释放资源
clearscrollrequest clearscrollrequest = new clearscrollrequest();
clearscrollrequest.setscrollids(scrollidlist);
resthighlevelclient.clearscroll(clearscrollrequest, requestoptions.default);
}
} catch (exception e) {
throw new runtimeexception(e);
}
}
scroll api 的优缺点和总结
优缺点:
- scroll查询的相应数据是非实时的,如果遍历过程中插入新的数据,是查询不到的。并且保留上下文需要足够的堆内存空间。
- 相比于 from/size 和 search_after 返回一页数据,scroll api 可用于从单个搜索请求中检索大量结果。但是 scroll 滚动遍历查询是非实时的,数据量大的时候,响应时间可能会比较长
适用场景
- 全量或数据量很大时遍历结果数据,而非分页查询。
- scroll方案基于快照,不能用在高实时性的场景下,建议用在类似数据导出场景下使用
3: search_after + pit 深度查询
- search_after是 es 5 新引入的一种分页查询机制,其原理几乎就是和scroll一样,因此代码也几乎是一样的。
- 官方文档说明不再建议使用scroll滚动分页和from size分页,建议使用search_after
- search_after 分页的方式和 scroll 搜索有一些显著的区别,首先它是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
不带pit
es语句实现
检索第一页的查询如下所示:
get wkl_test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"seq": {
"order": "asc"
}
}
],
"size": 200
}
上述请求的结果包括每个文档的 sort 值数组。
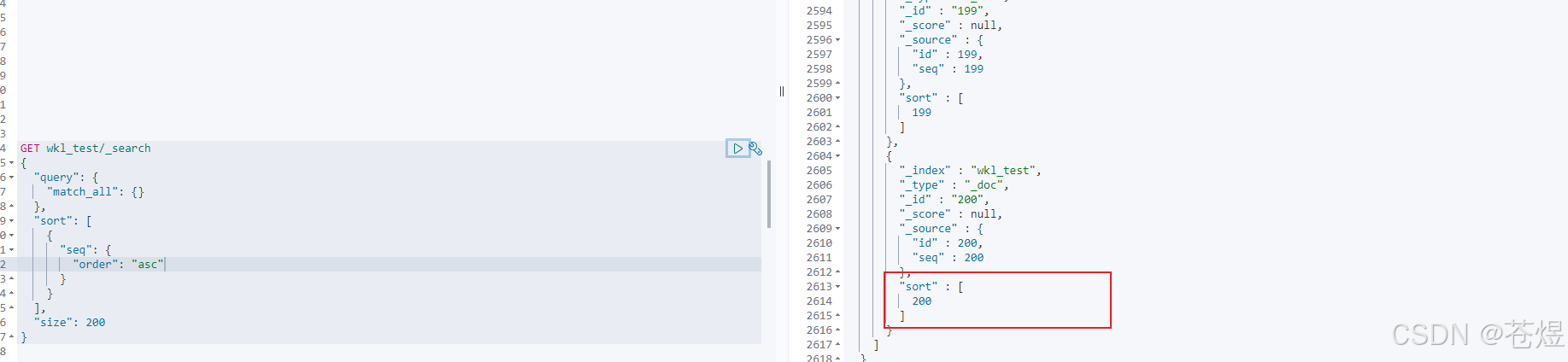
这些 sort 值可以与 search_after 参数一起使用,以开始返回在这个结果列表之后的任何文档。例如,我们可以使用上一个文档的 sort 值并将其传递给 search_after 以检索下一页结果:
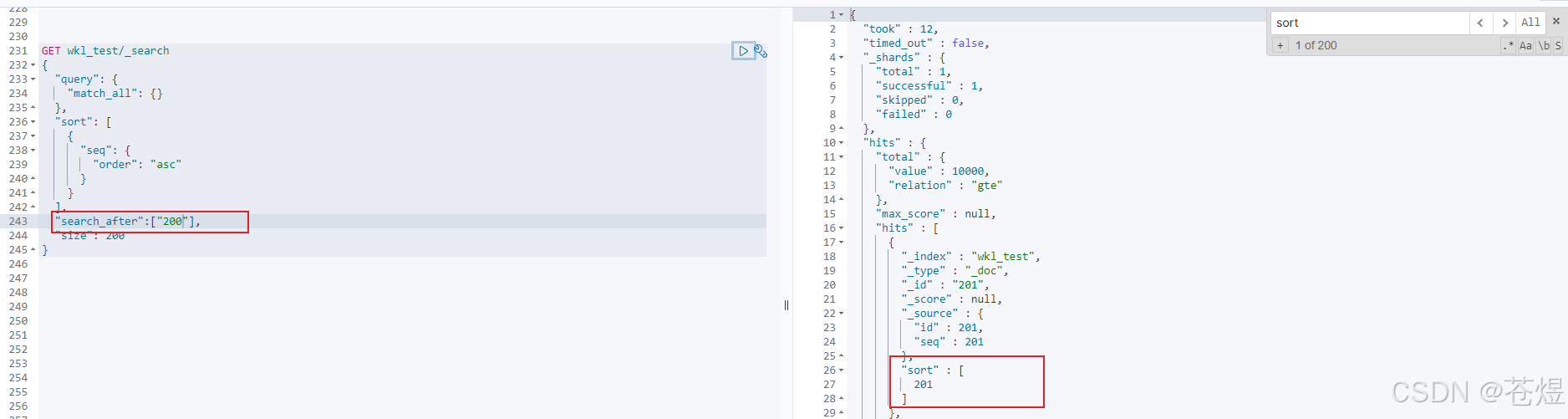
java 实现
@test
public void testsearchafter() throws ioexception {
resthighlevelclient resthighlevelclient = es7utilapi.getresthighlevelclient();
matchallquerybuilder matchallquerybuilder = querybuilders.matchallquery();
searchsourcebuilder searchsourcebuilder = new searchsourcebuilder();
searchsourcebuilder.query(matchallquerybuilder);
searchsourcebuilder.from(0);
searchsourcebuilder.size(200);
searchsourcebuilder.sort("seq", sortorder.asc);
searchsourcebuilder.tracktotalhits(true);
searchrequest searchrequest = new searchrequest()
.indices("wkl_test")
.source(searchsourcebuilder);
searchresponse searchresponse = resthighlevelclient.search(searchrequest, requestoptions.default);
searchhits hits = searchresponse.gethits();
long value = hits.gettotalhits().value;
system.out.println("查询到记录数=" + value);
list<jsonobject> list = new arraylist<>();
searchhit[] searchhists = hits.gethits();
object[] sortvalues = searchhists[searchhists.length - 1].getsortvalues();
if (searchhists.length > 0) {
for (searchhit hit : searchhists) {
string sourceasstring = hit.getsourceasstring();
jsonobject jsonobject = json.parseobject(sourceasstring);
jsonobject.put("_id", hit.getid());
list.add(jsonobject);
}
}
//往后的每次请求都携带上一次的sort_id进行访问。
while (arrayutils.isnotempty(searchhists) && searchhists.length > 0){
searchsourcebuilder.searchafter(sortvalues);
searchrequest.source(searchsourcebuilder);
searchresponse searchresponseafter = resthighlevelclient.search(searchrequest, requestoptions.default);
hits = searchresponseafter.gethits();
searchhists = hits.gethits();
sortvalues = searchhists[searchhists.length - 1].getsortvalues();
if (searchhists.length > 0) {
for (searchhit hit : searchhists) {
string sourceasstring = hit.getsourceasstring();
jsonobject jsonobject = json.parseobject(sourceasstring);
jsonobject.put("_id", hit.getid());
list.add(jsonobject);
}
}
if(list.size()>20000){
break;
}
system.out.println("-----彻底结束了-------");
}
}
问题
「优点:」
-
无状态查询,可以防止在查询过程中,数据的变更无法及时反映到查询中。
-
不需要维护scroll_id,不需要维护快照,因此可以避免消耗大量的资源。
「缺点:」
-
由于无状态查询,因此在查询期间的变更可能会导致跨页面的不一值。
-
排序顺序可能会在执行期间发生变化,具体取决于索引的更新和删除。
-
至少需要制定一个唯一的不重复字段来排序。
-
它不适用于大幅度跳页查询,或者全量导出,对第n页的跳转查询相当于对es不断重复的执行n次search after,而全量导出则是在短时间内执行大量的重复查询。
带pit
关于pit
-
在7.*版本中,es官方不再推荐使用scroll方法来进行深分页,而是推荐使用带pit的search_after来进行查询;
-
从7.*版本开始,您可以使用search_after参数通过上一页中的一组排序值检索下一页命中。
-
使用search_after需要多个具有相同查询和排序值的搜索请求。
-
如果这些请求之间发生刷新,则结果的顺序可能会更改,从而导致页面之间的结果不一致。
为防止出现这种情况,您可以创建一个时间点(pit)来在搜索过程中保留当前索引状态。
es语句实现
1:生成pit
#keep_alive必须要加上,它表示这个pit能存在多久,这里设置的是1分钟
post wkl_test/_pit?keep_alive=1m

2:在搜索请求中指定pit:
在每个搜索请求中添加 keep_alive 参数来延长 pit 的保留期,相当于是重置了一下时间
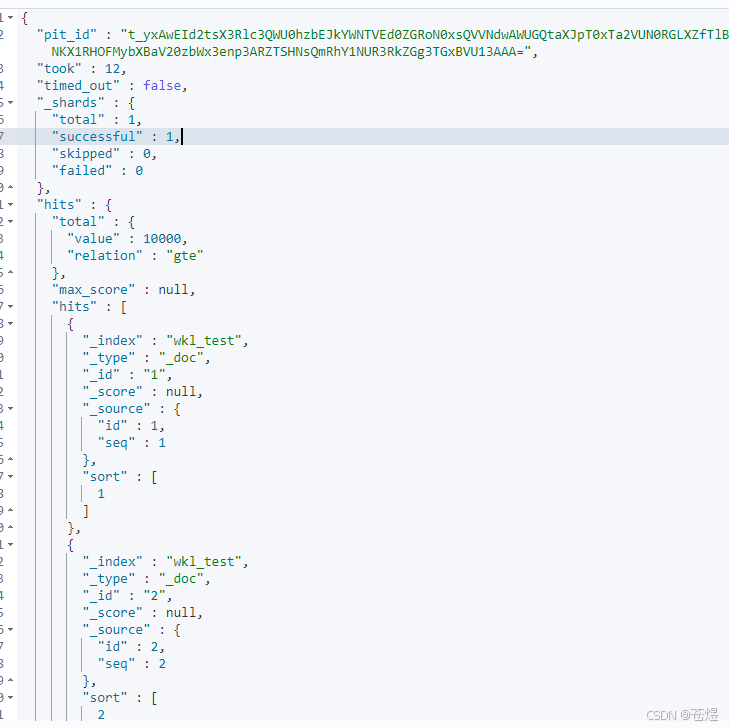
get _search
{
"query": {
"match_all": {}
},
"pit":{
"id":"t_yxaweid2tsx3rlc3qwu0hzbejkywntved0zgron0xsqvvndwawugqtaxjpt0xta2vun0rglxzftlbvzwaaaaaachg1fxy1uwnkx1rhofmybxbav20zbwx3enp3arztshnsqmrhy1nur3rkzgg3tgxbvu13aaa=",
"keep_alive":"5m"
},
"sort": [
{
"seq": {
"order": "asc"
}
}
],
"size": 200
}
3:删除pit
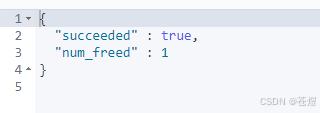
delete _pit
{
"id":"t_yxaweid2tsx3rlc3qwu0hzbejkywntved0zgron0xsqvvndwawugqtaxjpt0xta2vun0rglxzftlbvzwaaaaaachg1fxy1uwnkx1rhofmybxbav20zbwx3enp3arztshnsqmrhy1nur3rkzgg3tgxbvu13aaa="
}
总结
-
如果数据量小(from+size在10000条内),或者只关注结果集的topn数据,可以使用from/size 分页,简单粗暴
-
数据量大,深度翻页,后台批处理任务(数据迁移)之类的任务,使用 scroll 方式
-
数据量大,深度翻页,用户实时、高并发查询需求,使用 search after 方式

发表评论