我的博客:我的博客
原文:某电大三网络安全智能终端实验一
xxxxx
智能终端实验
实验报告(一)
班级:xxxxx
学号:xxxxxxxxx
日期:xxxxxxx
一、实验摘要
研究不断推动机器学习模型更快,更精确,更有效。然而,设计和训练模型的一个经常被忽视的方面是安全性和鲁棒性,特别是在面对希望欺骗模型的对手时。向图像添加不可察觉的扰动可以导致完全不同的模型性能。我们将通过一个图像分类器的例子来探讨这个主题。具体来说,我们将使用第一个和最流行的攻击方法之一,快速梯度符号攻击(fgsm) ,以欺骗 mnist 分类器。(摘自https://pytorch.org/tutorials/beginner/ fgsm_tutorial.htm l?highlight=a dversarial% 20example%20generation)
二、实验内容
a) 实验思路
#### 简述
有许多类别的对抗性攻击,每种攻击都有不同的目标和对攻击者知识的假设。然而,一般来说,总体目标是向输入数据添加最少量的扰动,从而导致所需的错误分类。有几种假设攻击者的知识,其中两个是: 白盒和黑盒。白盒攻击假设攻击者对模型有完整的知识和访问权限,包括体系结构、输入、输出和权重。黑盒攻击假设攻击者只能访问模型的输入和输出,并且对底层架构或权重一无所知。还有几种类型的目标,包括错误分类和源/目标错误分类。错误分类的目标意味着对手只希望输出分类是错误的,而不关心新的分类是什么。源/目标错误分类意味着对手想要更改原来属于特定源类的图像,以便将其归类为特定目标类。在这种情况下,fgsm 攻击是以错误分类为目标的白盒攻击。有了这些背景信息,我们现在可以详细讨论这次攻击了。
快速梯度
原理简述
快速梯度符号攻击(fgsa),是通过基于相同的反向传播梯度来调整输入数据使损失最大化,简言之,共计使用了丢失的梯度值w.r.t输入数据,然后调整输入使数据丢失最大化。下图是实现的例子:
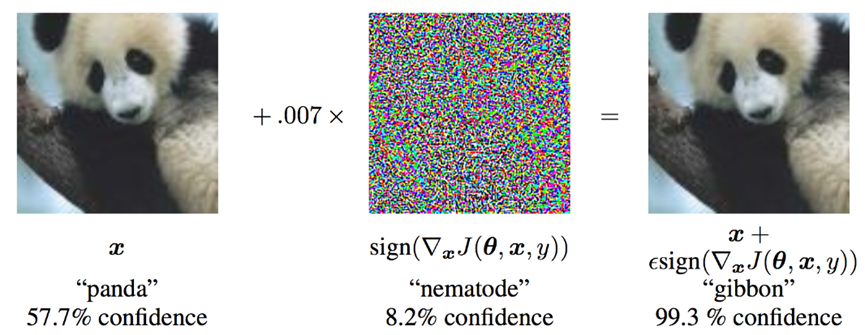
可以看出x是正常“熊猫”的原始输入图像,y是真实的图片输入,
θ表示模型参数,j(θ,x,y)是损失函数,∇xj(θ,x,y)是攻击将梯度反向传播回要计算的输入数据。然后,它通过一个小步骤调整输入数据,如0.007倍的sign(∇xj(θ,x,y))添加到里面会最大化损失函数。然后得到扰动图像x’,然后被目标网络错误地归类为“长臂猿”,而它显然仍然是一只“熊猫”。
b) 实现过程
1.输入
只有三个输入
- epsilons-运行时使用的 epsilon 值列表。在列表中保留0很重要,因为它表示原始测试集上的模型性能。此外,直观地,我们期望更大的 ε,更明显的扰动,但更有效的攻击方面的退化模型的准确性。因为这里的数据范围是 [ 0 , 1 ] [0,1] ,ε 值不应超过1。
- pretrain _ model-path加载预训练的模型
- use _ cuda-boolean 标志来使用 cuda,如果需要的话。
epsilons = [0, .05, .1, .15, .2, .25, .3]
pretrained_model = "mnist_cnn.pt"
use_cuda=true
2.模型建立
a)训练模型
我們用了一層 convolution layer 和 pooling layer 來擷取 image 的 feature,之後要把這些 feature map 成 10 個 node 的 output(因為有 10 個 class 要 predict),所以用 flatten 把 feature 集中成 vector 後,再用 fully-connected layer map 到 output layer。b 是 batch size,一次 train 幾張 image。
class net(nn.module):
def __init__(self):
super(net, self).__init__()
self.conv = nn.conv2d(1, 32, 3)
self.dropout = nn.dropout2d(0.25)
self.fc = nn.linear(5408, 10)
def forward(self, x):
x = self.conv(x)
x = f.relu(x)
x = f.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc(x)
output = f.log_softmax(x, dim=1)
return output
b)训练函数
def train(model, train_loader, optimizer, epochs, log_interval):
model.train()
for epoch in range(1, epochs + 1):
for batch_idx, (data, target) in enumerate(train_loader):
# clear gradient
optimizer.zero_grad()
# forward propagation
output = model(data)
# negative log likelihood loss
loss = f.nll_loss(output, target)
# back propagation
loss.backward()
# parameter update
optimizer.step()
# log training info
if batch_idx % log_interval == 0:
print('train epoch: {} [{}/{} ({:.0f}%)]\tloss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
c)训练中的测试
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad(): # disable gradient calculation for efficiency
for data, target in test_loader:
# prediction
output = model(data)
# compute loss & accuracy
test_loss += f.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=true)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
# log testing info
print('\ntest set: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
d)训练的主函数(把模型保存)
def main():
# training settings
batch_size = 64
epochs = 2
log_interval = 10
# define image transform
transform=transforms.compose([
transforms.totensor(),
transforms.normalize((0.1307,), (0.3081,)) # mean and std for the mnist training set
])
# load dataset
train_dataset = datasets.mnist('./data', train=true, download=true,
transform=transform)
test_dataset = datasets.mnist('./data', train=false,
transform=transform)
train_loader = torch.utils.data.dataloader(train_dataset, batch_size=batch_size)
test_loader = torch.utils.data.dataloader(test_dataset, batch_size=batch_size)
# create network & optimizer
model = net()
optimizer = optim.adam(model.parameters())
# train
train(model, train_loader, optimizer, epochs, log_interval)
# save and load model
torch.save(model.state_dict(), "mnist_cnn.pt")
model = net()
model.load_state_dict(torch.load("mnist_cnn.pt"))
# test
test(model, test_loader)
训练参数储存

e)训练结果

3.fgsm攻击
a)模型加载
加载模型
# mnist test dataset and dataloader declaration
transform = transforms.compose([
transforms.totensor(),
])
train_dataset = datasets.mnist('./data', train=true, download=true,
transform=transform)
test_loader = torch.utils.data.dataloader(train_dataset,batch_size=1, shuffle=true)
# define what device we are using
print("cuda available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
# initialize the network
model = net().to(device)
# load the pretrained model
model.load_state_dict(torch.load("mnist_cnn.pt", map_location='cpu'))
# set the model in evaluation mode. in this case this is for the dropout layers
model.eval()
b)攻击函数创建
现在,我们可以通过扰动原始输入来定义创建对抗性示例的函数。fgsm 攻击函数有三个输入,图像是原始清晰图像(xx) ,ε 是像素级扰动量(εε) ,data _ grad 是损失的梯度,输入图像(∇xj(θ,x,y))。然后,该函数创建扰动图像
p
e
r
t
u
r
b
e
d
i
m
a
g
e
=
i
m
a
g
e
+
e
p
s
i
l
o
n
∗
s
i
g
n
(
d
a
t
a
g
r
a
d
)
=
x
+
ϵ
∗
s
i
g
n
(
∇
x
j
(
θ
,
x
,
y
)
)
perturbed_image=image+epsilon∗sign(data_grad)=x+ϵ∗sign(∇ x j(θ,x,y))
perturbedimage=image+epsilon∗sign(datagrad)=x+ϵ∗sign(∇xj(θ,x,y))
# fgsm attack code
def fgsm_attack(image, epsilon, data_grad):
# collect the element-wise sign of the data gradient
sign_data_grad = data_grad.sign()
# create the perturbed image by adjusting each pixel of the input image
perturbed_image = image + epsilon*sign_data_grad
# adding clipping to maintain [0,1] range
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# return the perturbed image
return perturbed_image
c)开始攻击
accuracies = []
examples = []
# run test for each epsilon
for eps in epsilons:
acc, ex = test(model, device, test_loader, eps)
accuracies.append(acc)
examples.append(ex)
d) 实验结果截图
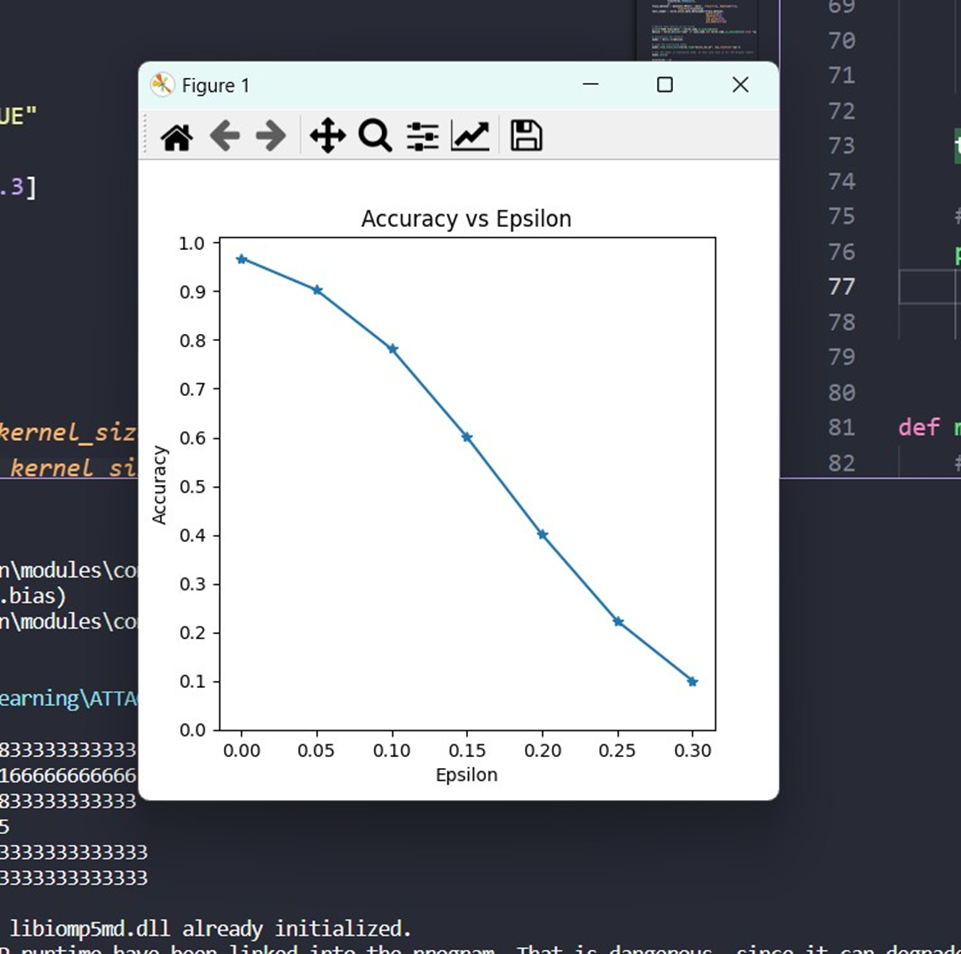
第一个结果是精度对 ε 图。正如前面提到的,随着 ε 的增加,我们预计测试的准确性会降低。这是因为更大的 ε 意味着我们在将损失最大化的方向上迈出了更大的一步。注意曲线中的趋势不是线性的,即使 ε 值是线性间隔的。例如,ε = 0.05 ε = 0.05的准确性仅比 ε = 0ε = 0低约4% ,但是 ε = 0.2 ε = 0.2的准确性比 ε = 0.15 ε = 0.15低25% 。另外,请注意模型的精度在 ε = 0.25 ε = 0.25和 ε = 0.3 ε = 0.3之间的随机精度。
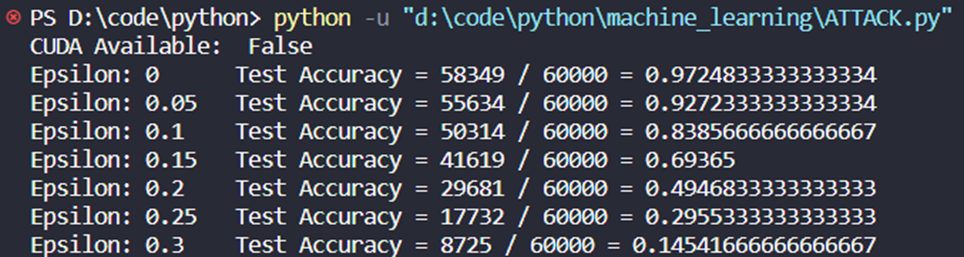
打印上述数据
# plot several examples of adversarial samples at each epsilon
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons),len(examples[0]),cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("eps: {}".format(epsilons[i]), fontsize=14)
orig,adv,ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()
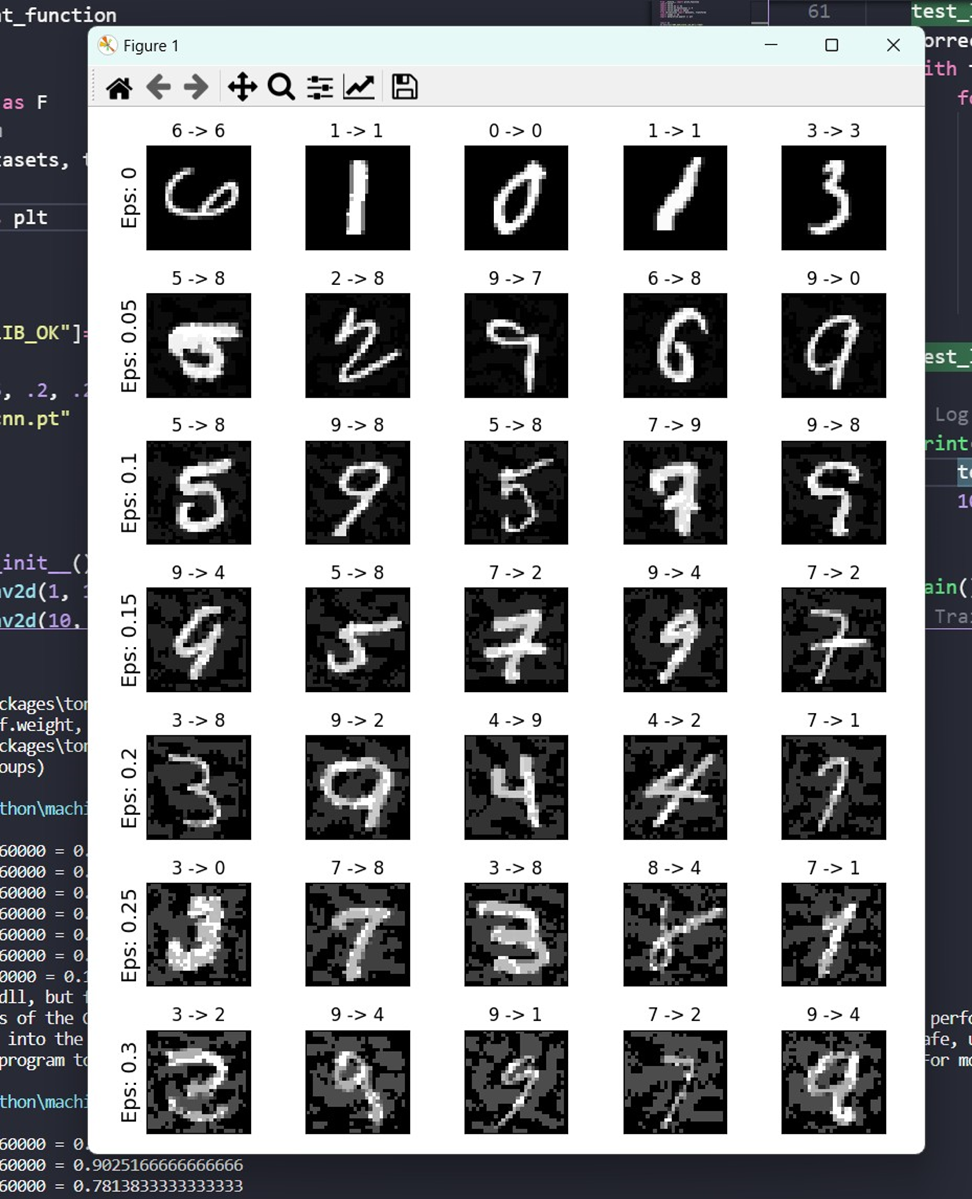
打印几个代表性的例子
三、实验结果分析
分析
从结果来看,随着 ε 的增加,测试精度下降,但扰动变得更容易察觉。实际上,在攻击者必须考虑的精确度下降和可感知性之间存在权衡。在这里,我们展示了一些成功的对抗例子在每个 ε 值。图的每一行显示不同的 ε 值。第一行是 ε = 0 ε = 0的例子,它表示原始的“干净”图像,没有扰动。每张图片的标题都显示了“原始分类-> 敌对分类”注意,当 ε = 0.15 ε = 0.15时,扰动开始变得明显,当 ε = 0.3 ε = 0.3时,扰动非常明显。然而,在所有情况下,人们仍然能够识别正确的类别,尽管增加了噪音。
1406)]
三、实验结果分析
分析
从结果来看,随着 ε 的增加,测试精度下降,但扰动变得更容易察觉。实际上,在攻击者必须考虑的精确度下降和可感知性之间存在权衡。在这里,我们展示了一些成功的对抗例子在每个 ε 值。图的每一行显示不同的 ε 值。第一行是 ε = 0 ε = 0的例子,它表示原始的“干净”图像,没有扰动。每张图片的标题都显示了“原始分类-> 敌对分类”注意,当 ε = 0.15 ε = 0.15时,扰动开始变得明显,当 ε = 0.3 ε = 0.3时,扰动非常明显。然而,在所有情况下,人们仍然能够识别正确的类别,尽管增加了噪音。

发表评论