数据结构之b树
数据结构之b树
一、b树的引入
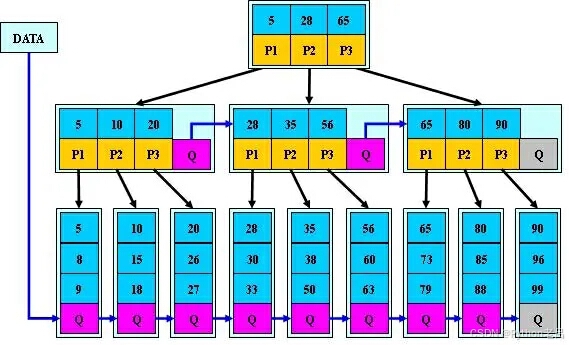
在计算机科学中,b树(b-tree)是一种特殊设计的自平衡树,尤其在数据库和文件系统的索引结构中占据重要位置。这种树结构之所以被设计出来,主要是为了解决在大量数据面前,如何既保持数据的稳定有序,又使得插入与修改操作具有较平均的复杂度。b树与二叉查找树的不同之处在于,b树的每个节点可以包含多个关键字和子节点,这使得它在处理大量数据时具有更高的效率。
二、b树的基本性质
b树的基本性质确保了其在数据操作中的稳定性和高效性:
- 每个节点至多有m-1个关键字(可以认为有m个子节点),这确保了节点的关键字数量不会过大,从而保证了树的平衡性。
- 根节点至少有两个子节点(除非树中只有一个节点),这确保了树的完整性和结构的合理性。
- 非根节点至少有⌈m/2⌉个子节点,这是b树自平衡性的关键之一,确保了树在插入或删除数据时都能保持较好的平衡。
- 所有叶子节点在同一层,且不带信息(可以看作是外部节点或查找失败的节点,实际上这些节点不存在于结构中,指向这些节点的指针都为空)。这一特性使得b树的查找操作更加高效。
- 每个非叶子节点(称为内部节点或索引节点)包含n个关键字信息(k1, k2, …, kn),并且关键字个数n满足:⌈m/2⌉ - 1 ≤ n ≤ m - 1。这一特性保证了节点的关键字数量在合理范围内。
- 对于节点内的关键字,从左到右是递增有序的,即ki < ki+1。这一特性使得b树的查找操作更加迅速。
- 关键字的左子树中所有节点的值都小于ki,右子树中所有节点的值都大于ki。这一特性确保了b树的有序性。
三、b树的操作
1. 插入操作
当需要向b树中插入一个关键字时,操作过程通常是这样的:
- 从根节点开始查找合适的位置进行插入。
- 如果当前节点关键字数小于m-1,那么直接插入即可。
- 如果当前节点已满(即关键字数等于m-1),那么就需要进行节点的分裂操作。将当前节点分裂为两个节点,并将中间的关键字上移到父节点。这个过程可能会一直向上传递到根节点。
- 如果根节点也满了,那么就需要创建一个新的根节点来容纳分裂出来的关键字。
2. 删除操作
b树的删除操作相对复杂一些,具体步骤如下:
- 首先,从b树中查找到需要删除的关键字所在的节点。
- 如果该节点是叶子节点,那么直接删除该关键字即可。
- 如果该节点不是叶子节点,那么需要找到该关键字在子树中的后继关键字(或者前驱关键字),然后将该后继关键字(或前驱关键字)替换到要删除的关键字的位置,并删除后继关键字(或前驱关键字)。
- 然后,从被替换关键字所在的子树继续执行删除操作。
- 如果删除关键字后节点关键字数过少(小于⌈m/2⌉-1),则需要从兄弟节点借调关键字,或者与兄弟节点合并。
3. 查找操作
b树的查找操作与二叉查找树类似,只是需要处理多个子节点的情况。从根节点开始,根据关键字的大小关系在子树中进行查找,直到找到关键字所在的叶子节点,或者确定树中不存在该关键字。
四、b树的优势
b树相较于其他数据结构,在特定场景下具有显著的优势:
- 磁盘读写特性:b树最初被设计用于磁盘存储系统,因为磁盘读写数据是以块为单位的。b树通过将多个关键字存储在一个节点中,可以一次性读取或写入多个关键字,从而减少磁盘i/o操作的次数,提高数据访问的效率。
- 树的高度:由于b树的每个节点可以包含多个关键字和子节点,因此b树通常具有比二叉查找树更低的高度。这意味着在查找、插入和删除数据时,b树需要遍历的节点数更少,从而提高了操作的效率。
- 自平衡性:b树在插入和删除数据时能够保持较好的平衡性,避免了树的高度过高导致的性能下降问题。这种自平衡性使得b树在处理大量数据时仍能保持稳定的性能。
五、b树的应用
b树,作为一种高效的自平衡树,在数据库和文件系统中扮演着至关重要的角色。下面,我们将更深入地探讨b树在这些领域中的具体应用。
1. 数据库索引
在数据库管理系统中,b树被广泛应用于索引结构。想象一下,当我们在数据库中查询某个记录时,如果没有索引,系统可能需要遍历整个表来找到满足条件的记录,这将非常耗时。但是,如果使用了b树作为索引结构,数据库系统就可以在短时间内迅速定位到表中的记录,大大提高了查询效率。例如,在一个包含大量用户信息的数据库中,通过b树索引,我们可以快速找到某个特定用户的所有信息。
2. 文件系统
在文件系统中,b树同样发挥着不可或缺的作用。它用于组织文件和目录的元数据信息,如文件名、文件大小、创建时间等。通过将这些元数据信息存储在b树中,文件系统可以快速定位文件和目录在磁盘上的位置,从而实现文件的快速访问和修改。例如,当我们在文件系统中打开一个文件时,文件系统会首先通过b树找到该文件在磁盘上的位置,然后读取该文件的内容。
3. 内存数据库
尽管b+树(b树的变种)在内存数据库中的应用更为广泛,但b树在某些内存数据库中仍然具有应用价值。虽然b树在内存中的性能表现略逊于b+树,但由于其实现简单且易于理解,因此在某些场景下仍然被采用。例如,在一些轻量级的内存数据库中,为了简化实现和提高性能,可能会选择使用b树作为索引结构。
六、b树与b+树的区别(b加树)
虽然b树在数据库和文件系统中有着广泛的应用,但在某些场景下,它的变种b+树更为常用。那么,b树与b+树之间究竟有哪些区别呢?
1. 叶子节点
b树的叶子节点不包含指向其他节点的指针,它们各自为政。而b+树的叶子节点则通过指针相互连接,形成了一个有序链表。这种链表结构使得b+树在范围查询时具有更高的效率。一旦找到范围的下界,就可以通过链表结构直接遍历得到范围内的所有元素,而不需要返回根节点重新搜索。
2. 非叶子节点的关键字信息
b树的非叶子节点包含了关键字信息,这些关键字用于指导搜索过程。然而,b+树的非叶子节点仅包含指向子节点的指针,不包含关键字信息。这使得b+树的非叶子节点可以相对更小,从而降低了树的存储开销。
3. 插入与删除操作
由于b+树的叶子节点通过指针相互连接,因此在插入和删除操作时,b+树需要维护这个链表结构。这可能导致b+树的插入和删除操作相对于b树来说稍微复杂一些。但是,这种复杂性在范围查询的高效率面前显得微不足道。
七、b树的实现与优化
在实际应用中,b树的实现需要考虑多种因素,如内存管理、磁盘i/o操作、并发控制等。下面,我们将介绍一些常见的b树实现与优化策略。
1. 内存管理
由于b树的节点可能包含大量的关键字和子节点指针,因此合理的内存管理对于提高b树的性能至关重要。一种常见的策略是使用内存池来管理b树节点的分配和释放。内存池可以预先分配一定数量的内存块,并将它们组织成一个链表。当需要创建新的b树节点时,可以从内存池中申请一个内存块;当b树节点不再需要时,可以将其释放回内存池。这种策略可以减少内存碎片并提高内存访问效率。
2. 磁盘i/o优化
b树最初被设计用于磁盘存储系统,因此优化磁盘i/o操作是提高b树性能的关键。一种常见的策略是尽量将节点大小设置为磁盘块大小的整数倍。这样可以确保每个节点都可以完整地存储在一个磁盘块中,从而减少磁盘i/o操作的次数。此外,还可以利用磁盘的预读机制来提高数据访问的效率。当系统从磁盘中读取一个数据时,它通常会预读一些相邻的数据到内存中。因此,我们可以将b树的节点按照磁盘块的顺序进行存储和访问,以充分利用磁盘的预读机制。
3. 并发控制
在多线程或多用户环境下,b树的并发访问和修改需要得到妥善的管理。一种常见的策略是使用锁来保护b树的节点或子树。当一个线程需要访问或修改b树的某个节点时,它需要先获取该节点的锁;在访问或修改完成后,再释放该节点的锁。这样可以确保在并发操作下的数据一致性和正确性。此外,还可以使用乐观并发控制等技术来提高并发操作的效率。乐观并发控制假设多个事务在并发执行时不会相互冲突,因此它们可以自由地执行自己的操作。只有当事务提交时,才会检查是否存在冲突;如果存在冲突,则回滚该事务并重新执行。这种策略可以减少锁的使用并提高系统的吞吐量。
八、总结
b树作为一种自平衡的树形数据结构,在数据库和文件系统中有着广泛的应用。它通过允许节点包含多个关键字和子节点来提高数据的访问效率,并通过维护节点的平衡性来保持稳定的性能。然而,在实际应用中,我们还需要根据具体的需求和场景来选择合适的数据结构,并采取相应的优化策略来提高性能。通过对b树的学习和实践,我们可以更好地理解树形数据结构的原理和应用,为实际问题的解决提供有力的支持。
发表评论