
1 前言
上一篇文章,我们介绍了哈希表的基本概念:
哈希表(hash table)是一种数据结构,它通过哈希函数将键映射到表中的一个位置来访问记录,支持快速的插入和查找操作。
我们可以通过对key值的处理快速找到目标。如果多个key出现相同的映射位置,此时就发生了哈希冲突,就要进行特殊处理:闭散列和开散列。
- 闭散列:也叫做开放定址法,其核心是出现哈希冲突,就从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
- 开散列:又叫链地址法(开链法),其核心是每个位置是以链表结构储存,遇到哈希冲突就将数据进行头插。

我们已经实现了闭散列版本的哈希表,今天我们来实现开散列版本的哈希表(哈希桶)!
2 开散列版本的实现
我们先来分析一下,我们要实现哈希桶需要做些什么工作。开散列本质上是一个数组,每个位置对于了一个映射地址。开散列解决哈希冲突的本质是将多个元素以链表进行链接,方便我们进行寻找。既然使用到了链表我们可以直接使用list,但是list底层是双向循环链表,对于我们这样简单的情景大可不必这么复杂,使用简单的单向不循环链表即可,并且可以节省一半的空间!
2.1 节点设计
因为我们要实现单链表结构,肯定要来先设计一下节点:
//节点设计
template<class k, class v>
struct hashnode
{
//储存的数据
pair<k, v> _kv;
//下一个节点的指针
hashnode<k, v>* _next;
//构造函数
hashnode(pair<k, v> kv)
:_kv(kv),
_next(nullptr)
{}
};
节点里面使用pair来储存数据,并储存一个指向下一个节点的指针。这样就能实现链表结构
2.2 框架搭建
设计好了节点,就要进行整体框架的搭建,哈希桶的底层是一个指针数组,还需要一个变量来记录有效个数,方便检测何时扩容。我们简单实现最基本的工作:插入 , 删除和查找就可以。
需要注意的是,我们需要通过对应的哈希函数来将不同类型的数据转换为size_t类型,这样才能映射到数组中
//仿函数!
template<class k>
struct hashfunc
{
//可以进行显示类型转换的直接转换!!!
size_t operator()(const k& k)
{
return (size_t)k;
}
};
//string不能进行直接转换,需要特化
template<>
struct hashfunc<string>
{
//可以进行显示类型转换的直接转换!!!
size_t operator()(const string& k)
{
size_t key = 0;
for (auto s : k)
{
key *= 131;
key += s;
}
return key;
}
};
//开散列的哈希表
// key value 仿函数(转换为size_t)
template<class k, class v, class hash = hashfunc<k>>
class hashtable
{
public:
typedef hashnode<k, v> node;
//构造函数
hashtable()
{
_table.resize(10, nullptr);
_n = 0;
}
//插入数据
bool insert(const pair<k, v> kv)
{
}
//删除
bool erase(const k& key)
{
}
//查找
node* find(const k& key)
{
}
private:
//底层是一个指针数组
vector<node*> _table;
//有效数量
size_t _n;
//仿函数
hash hs;
};
2.3 插入函数
实现插入函数,需要进行以下步骤:
- 检查当前key是否存在,不存在才插入
- 根据负载因子检查是否需要扩容
- key 通过仿函数得到
hashi,找到映射位置 - 创建一个新节点,并将其头插到映射位置的链表中
扩容的逻辑需要注意一下:最容易想到的是遍历一遍原先的哈希表,将数据重新插入到新的哈希表中,然后释放原先的节点,这样顺畅就可以做到,但是这样其实做了多余的动作,我们不需要将原本的节点释放,直接将原本节点移动到新的哈希表中即可!
//插入数据
bool insert(const pair<k, v> kv)
{
if ( find(kv.first) ) return false;
//扩容
if (_n == _table.size() * 0.7)
{
//直接把原本的节点移动到新的table中即可
vector<node*> newtable(2 * _table.size());
//遍历整个数组
for (int i = 0; i < _table.size(); i++)
{
if (_table[i])
{
node* cur = _table[i];
while (cur)
{
//获取数据
node* next = cur->_next;
//计算新的映射
int hashi = hs(cur->_kv.first) % newtable.size();
//进行头插
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
}
}
_table.swap(newtable);
}
//首先寻找到合适下标
int hashi = hs(kv.first) % _table.size();
//进行头插
node* newnode = new node(kv);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
++_n;
return true;
}
2.4 删除函数
删除的逻辑是根据key值找到对应的位置,在该位置的链表中检索是否有相等的数值。如果有就进行删除,否则返回false
//删除
bool erase(const k& key)
{
//根据key找到对应位置
int hashi = hs(key) % _table.size();
//在当前位置的链表中寻找目标
node* cur = _table[hashi];
node* prev = nullptr;
while (cur)
{
if (cur->_kv.first == key)
{
//找到该位置
//分类讨论情况
--_n;
//如果删除的是第一个
if (prev == nullptr)
{
_table[hashi] = cur->_next;
}
//其他情况
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
这样简单的删除就写好了!其实就是链表操作加上一步检索的操作。
2.5 查找操作
查找的逻辑和删除类似,根据key值找到映射位置,再在该链表中进行检索,找到返回节点指针,反之返回空指针。
node* find(const k& key)
{
//根据key找到对应位置
int hashi = hs(key) % _table.size();
//在当前位置的链表中寻找目标
node* cur = _table[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
2.6 测试
我写好了插入,删除和查找。接下来就来测试一下:
实践是检验真理的唯一标准!
//测试
void test_ht1()
{
vector<int> arr = { 0 , 1 , 1 , 11 , 111 , 2 , 22 , 21 , 32 , 51 };
hashtable<int, int> ht;
for (int i = 0; i < arr.size(); i++)
{
ht.insert(make_pair(arr[i], arr[i]));
}
for (int i = 0; i < arr.size(); i++)
{
ht.erase(arr[i]);
}
}
void test_ht2()
{
vector<int> arr = { 0 , 1 , 1 , 11 , 111 , 2 , 22 , 21 , 32 , 51 };
hashtable<int, int> ht;
for (int i = 0; i < arr.size(); i++)
{
ht.insert(make_pair(arr[i], arr[i]));
}
if (ht.find(1))
{
std::cout << ht.find(1)->_kv.first << ':' << ht.find(1)->_kv.second << endl;
}
}
void test_ht3()
{
vector<string> arr = { "sort" , "hello" , "jlx" , "hi" };
hashtable<string, string> ht;
for (int i = 0; i < arr.size(); i++)
{
ht.insert(make_pair(arr[i], arr[i]));
}
if (ht.find("sort"))
{
std::cout << ht.find("sort")->_kv.first << ':' << ht.find("sort")->_kv.second << endl;
}
}
}
这里我们分别测试插入删除,插入寻找,字符串的处理:
我进入调试来看看是否正常:
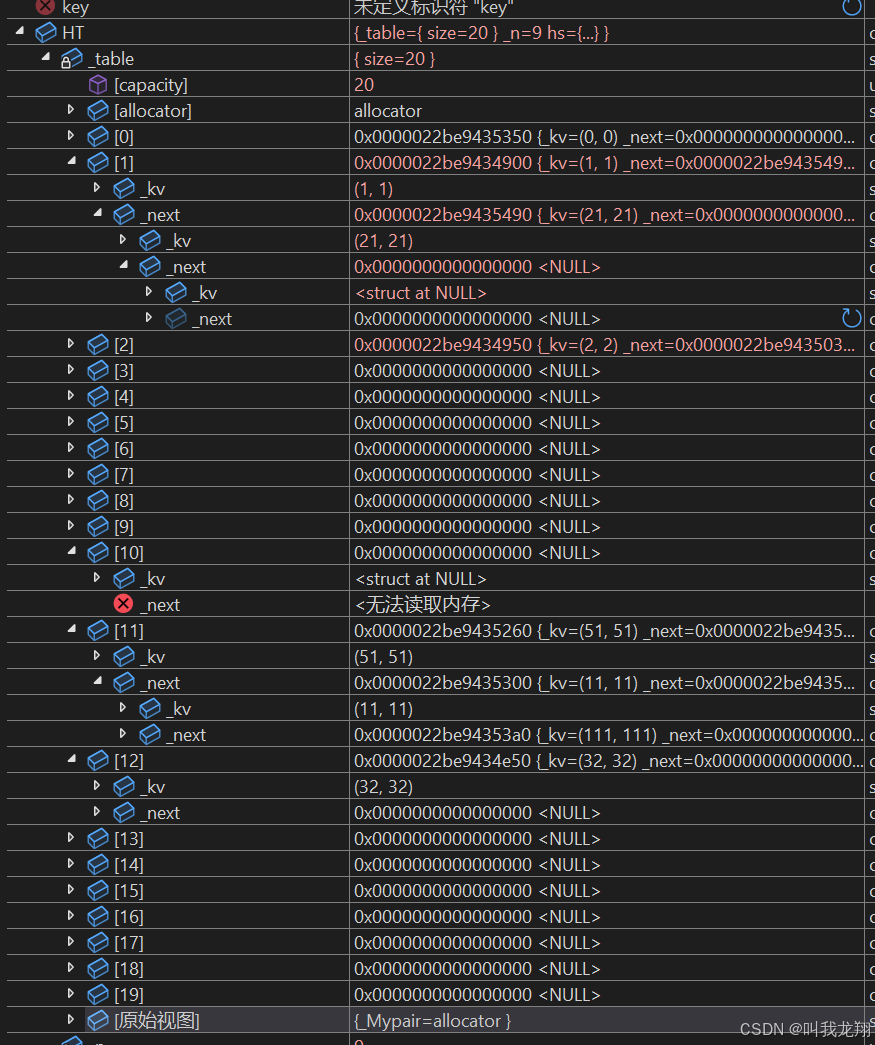
通过对监视窗口的查看,我们可以验证我们的代码正常运行的!






发表评论