project2下
task 3 extendible hash table
1 总体介绍
通过申请读写页的方式来管理增删改查、申请新页来管理分裂桶、删除空页合并桶
2 代码详解
2.1头文件
2.1.1各种变量名含义
| 变量名 | 含义 |
|---|---|
| index_name_ | 不知道,没啥用,到时候赋个值就行 |
| bufferpoolmanager *bpm_ | 要使用的缓冲区池管理器 |
| kc cmp_ | 键的比较器 |
| hashfunction hash_fn_ | 哈希函数 |
| header_max_depth_ | 头部页面允许的最大深度 |
| directory_max_depth_ | 目录页面允许的最大深度 |
| bucket_max_size_ | 桶页面允许的最大深度 |
| header_page_id_ | 头目录pageid |
2.1.2方法列表
| 变量名 | 含义 |
|---|---|
| init | 初始化 |
| getvalue | 在哈希表中查找与给定键相关联的值 |
| insert | 插入值 |
| updatedirectorymapping | 更新目录索引 |
| spiltbucket | 分裂桶(自己定义的) |
| remove | 移除键值对 |
2.2 init
2.2.1 详解
初始化就是把该赋值的赋值,没啥说的
2.2.2 代码
diskextendiblehashtable<k, v, kc>::diskextendiblehashtable(const std::string &name, bufferpoolmanager *bpm,
const kc &cmp, const hashfunction<k> &hash_fn,
uint32_t header_max_depth, uint32_t directory_max_depth,
uint32_t bucket_max_size)
: bpm_(bpm),
cmp_(cmp),
hash_fn_(std::move(hash_fn)),
header_max_depth_(header_max_depth),
directory_max_depth_(directory_max_depth),
bucket_max_size_(bucket_max_size) {
this->index_name_ = name;
// 初始化header页
header_page_id_ = invalid_page_id;
auto header_guard = bpm->newpageguarded(&header_page_id_);
auto header_page = header_guard.asmut<extendiblehtableheaderpage>();
header_page->init(header_max_depth_);
}
2.3 getvalue
2.3.1 详解
看图
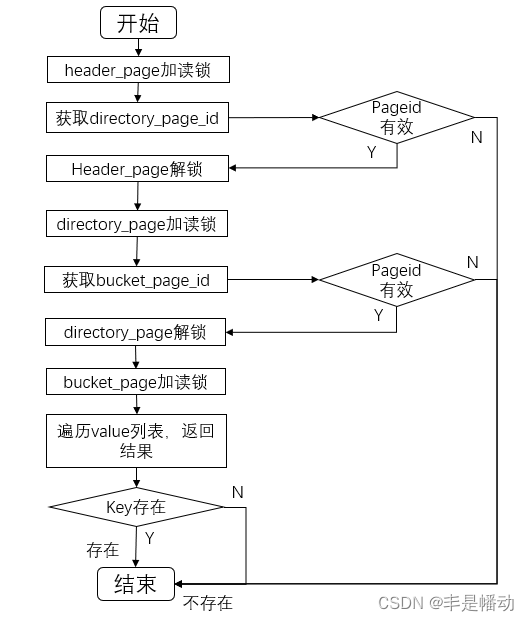
2.3.2 代码
// 在哈希表中查找与给定键相关联的值
// key:要查找的键;result:与给定键相关联的值; transaction 当前事务
auto diskextendiblehashtable<k, v, kc>::getvalue(const k &key, std::vector<v> *result, transaction *transaction) const
-> bool {
// 获取header page
readpageguard header_guard = bpm_->fetchpageread(header_page_id_);
auto header_page = header_guard.as<extendiblehtableheaderpage>();
// 通过hash值获取dir_page_id。若dir_page_id为非法id则未找到
auto hash = hash(key);
auto dirindex = header_page->hashtodirectoryindex(hash);
page_id_t directory_page_id = header_page->getdirectorypageid(dirindex);
if (directory_page_id == invalid_page_id) {
return false;
}
// 获取dir_page
header_guard.drop();
readpageguard directory_guard = bpm_->fetchpageread(directory_page_id);
auto directory_page = directory_guard.as<extendiblehtabledirectorypage>();
// 通过hash值获取bucket_page_id。若bucket_page_id为非法id则未找到
auto bucket_index = directory_page->hashtobucketindex(hash);
auto bucket_page_id = directory_page->getbucketpageid(bucket_index);
log_debug("要获得的bucket_page_id是:%d,哈系数是%d", bucket_page_id, hash);
if (bucket_page_id == invalid_page_id) {
return false;
}
readpageguard bucket_guard = bpm_->fetchpageread(bucket_page_id);
// 获取bucket_page
directory_guard.drop();
auto bucket_page = bucket_guard.as<extendiblehtablebucketpage<k, v, kc>>();
// 在bucket_page上查找
v value;
if (bucket_page->lookup(key, value, cmp_)) {
result->push_back(value);
return true;
}
return false;
}
2.4 insert
2.4.1 详解
看图就行,注意拆分桶这里,拆分一次不一定就拆好了,可能一个还是满的,一个空的,所以还要回到insert方法,接着判断满没满。
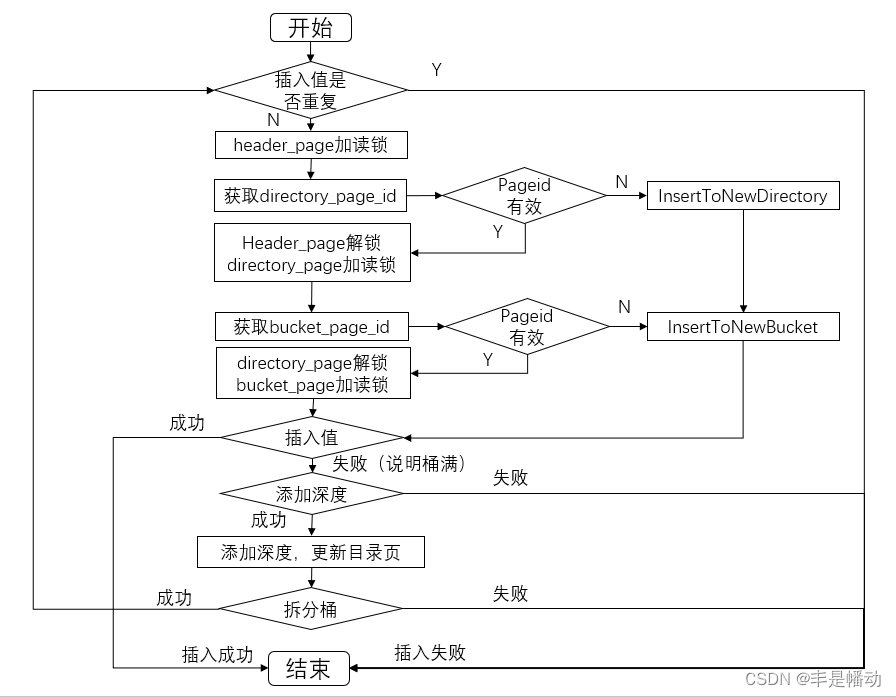
2.4.2 代码
template <typename k, typename v, typename kc>
auto diskextendiblehashtable<k, v, kc>::insert(const k &key, const v &value, transaction *transaction) -> bool {
std::vector<v> valuesfound;
bool keyexists = getvalue(key, &valuesfound, transaction);
if (keyexists) {
// 已存在直接返回false表示不插入重复键
return false;
}
auto hash_key = hash(key);
// 获取header page
writepageguard header_guard = bpm_->fetchpagewrite(header_page_id_);
auto header_page = header_guard.asmut<extendiblehtableheaderpage>();
// 使用header_page来获取目录索引
auto directory_index = header_page->hashtodirectoryindex(hash_key);
//用目录索引获取目录页,然后找到頁的目录id
page_id_t directory_page_id = header_page->getdirectorypageid(directory_index);
// 若dir_page_id为非法id则在新的dir_page添加
if (directory_page_id == invalid_page_id) {
return inserttonewdirectory(header_page, directory_index, hash_key, key, value);
}
// 对directory加锁
header_guard.drop();
writepageguard directory_guard = bpm_->fetchpagewrite(directory_page_id);
// 获取 dir page
auto directory_page = directory_guard.asmut<extendiblehtabledirectorypage>();
// 通过hash值获取bucket_page_id。若bucket_page_id为非法id则在新的bucket_page添加
auto bucket_index = directory_page->hashtobucketindex(hash_key);
auto bucket_page_id = directory_page->getbucketpageid(bucket_index);
if (bucket_page_id == invalid_page_id) {
return inserttonewbucket(directory_page, bucket_index, key, value);
}
// 对bucket加锁
writepageguard bucket_guard = bpm_->fetchpagewrite(bucket_page_id);
auto bucket_page = bucket_guard.asmut<extendiblehtablebucketpage<k, v, kc>>();
// log_debug("要插入的bucket是:%d,哈希数是%d",bucket_page_id,hash_key);
// 获取bucket_page插入元素,如果插入失败则代表该bucket_page满了
if (bucket_page->insert(key, value, cmp_)) {
log_debug("insert bucket %d success!", bucket_page_id);
return true;
}
auto h = 1u << directory_page->getglobaldepth();
// 判断是否能添加度,不能则返回
if (directory_page->getlocaldepth(bucket_index) == directory_page->getglobaldepth()) {
if (directory_page->getglobaldepth() >= directory_page->getmaxdepth()) {
return false;
}
directory_page->incrglobaldepth();
// 需要更新目录页
for (uint32_t i = h; i < (1u << directory_page->getglobaldepth()); ++i) {
auto new_bucket_page_id = directory_page->getbucketpageid(i - h);
auto new_local_depth = directory_page->getlocaldepth(i - h);
directory_page->setbucketpageid(i, new_bucket_page_id);
directory_page->setlocaldepth(i, new_local_depth);
}
}
directory_page->incrlocaldepth(bucket_index);
directory_page->incrlocaldepth(bucket_index + h);
// 拆份bucket
if (!splitbucket(directory_page, bucket_page, bucket_index)) {
return false;
}
bucket_guard.drop();
directory_guard.drop();
return insert(key, value, transaction);
}
template <typename k, typename v, typename kc>
auto diskextendiblehashtable<k, v, kc>::inserttonewdirectory(extendiblehtableheaderpage *header, uint32_t directory_idx,
uint32_t hash, const k &key, const v &value) -> bool {
page_id_t directory_page_id = invalid_page_id;
writepageguard directory_guard = bpm_->newpageguarded(&directory_page_id).upgradewrite();
auto directory_page = directory_guard.asmut<extendiblehtabledirectorypage>();
directory_page->init(directory_max_depth_);
header->setdirectorypageid(directory_idx, directory_page_id);
uint32_t bucket_idx = directory_page->hashtobucketindex(hash);
log_debug("inserttonewdirectory directory_page_id:%d", directory_page_id);
return inserttonewbucket(directory_page, bucket_idx, key, value);
}
template <typename k, typename v, typename kc>
auto diskextendiblehashtable<k, v, kc>::inserttonewbucket(extendiblehtabledirectorypage *directory, uint32_t bucket_idx,
const k &key, const v &value) -> bool {
page_id_t bucket_page_id = invalid_page_id;
writepageguard bucket_guard = bpm_->newpageguarded(&bucket_page_id).upgradewrite();
auto bucket_page = bucket_guard.asmut<extendiblehtablebucketpage<k, v, kc>>();
bucket_page->init(bucket_max_size_);
directory->setbucketpageid(bucket_idx, bucket_page_id);
log_debug("inserttonewbucket bucket_page_id:%d", bucket_page_id);
return bucket_page->insert(key, value, cmp_);
}
2.5 update
2.5.1 详解
更新的代码我抄的。大概就是更新了目录?insert更新目录的时候压根没用这个方法,自己写了个。remove的时候用了。
2.5.2 代码
void diskextendiblehashtable<k, v, kc>::updatedirectorymapping(extendiblehtabledirectorypage *directory,
uint32_t new_bucket_idx, page_id_t new_bucket_page_id,
uint32_t new_local_depth, uint32_t local_depth_mask) {
for (uint32_t i = 0; i < (1u << directory->getglobaldepth()); ++i) {
// 检查目录条目是否需要更新为指向新桶
// 如果目录项对应的是原桶
if (directory->getbucketpageid(i) == directory->getbucketpageid(new_bucket_idx)) {
if (i & local_depth_mask) {
// 如果这个目录项的在新局部深度位上的值为1,应该指向新桶
directory->setbucketpageid(i, new_bucket_page_id);
directory->setlocaldepth(i, new_local_depth);
} else {
// 否则,它仍然指向原桶,但其局部深度需要更新
directory->setlocaldepth(i, new_local_depth);
}
}
}
}
2.6 splitbucket
2.6.1 详解
具体逻辑在insert的图里已经说完了,这里只需要注意,把满桶里的内容放到容器里以后要把原本的满桶清空。
2.6.2 代码
template <typename k, typename v, typename kc>
auto diskextendiblehashtable<k, v, kc>::splitbucket(extendiblehtabledirectorypage *directory,
extendiblehtablebucketpage<k, v, kc> *bucket, uint32_t bucket_idx)
-> bool {
// 创建新bucket_page
page_id_t split_page_id;
writepageguard split_bucket_guard = bpm_->newpageguarded(&split_page_id).upgradewrite();
if (split_page_id == invalid_page_id) {
return false;
}
auto split_bucket = split_bucket_guard.asmut<extendiblehtablebucketpage<k, v, kc>>();
split_bucket->init(bucket_max_size_);
uint32_t split_idx = directory->getsplitimageindex(bucket_idx);
uint32_t local_depth = directory->getlocaldepth(bucket_idx);
directory->setbucketpageid(split_idx, split_page_id);
directory->setlocaldepth(split_idx, local_depth);
log_debug("spilt bucket_page_id:%d", split_page_id);
// 将原来满的bucket_page拆分到两个page页中
page_id_t bucket_page_id = directory->getbucketpageid(bucket_idx);
if (bucket_page_id == invalid_page_id) {
return false;
}
// 先将原来的数据取出,放置在entries容器中
int size = bucket->size();
std::list<std::pair<k, v>> entries;
for (int i = 0; i < size; i++) {
entries.emplace_back(bucket->entryat(i));
}
// 清空bucket:size_ = 0
bucket->clear();
// 分到两个bucket_page中
for (const auto &entry : entries) {
uint32_t target_idx = directory->hashtobucketindex(hash(entry.first));
page_id_t target_page_id = directory->getbucketpageid(target_idx);
if (target_page_id == bucket_page_id) {
bucket->insert(entry.first, entry.second, cmp_);
} else if (target_page_id == split_page_id) {
split_bucket->insert(entry.first, entry.second, cmp_);
}
}
return true;
}
2.7 remove
2.7.1 详解
图没画,先用个别人的顶上。和下面的代码不是对应的!!!但思路是一样的
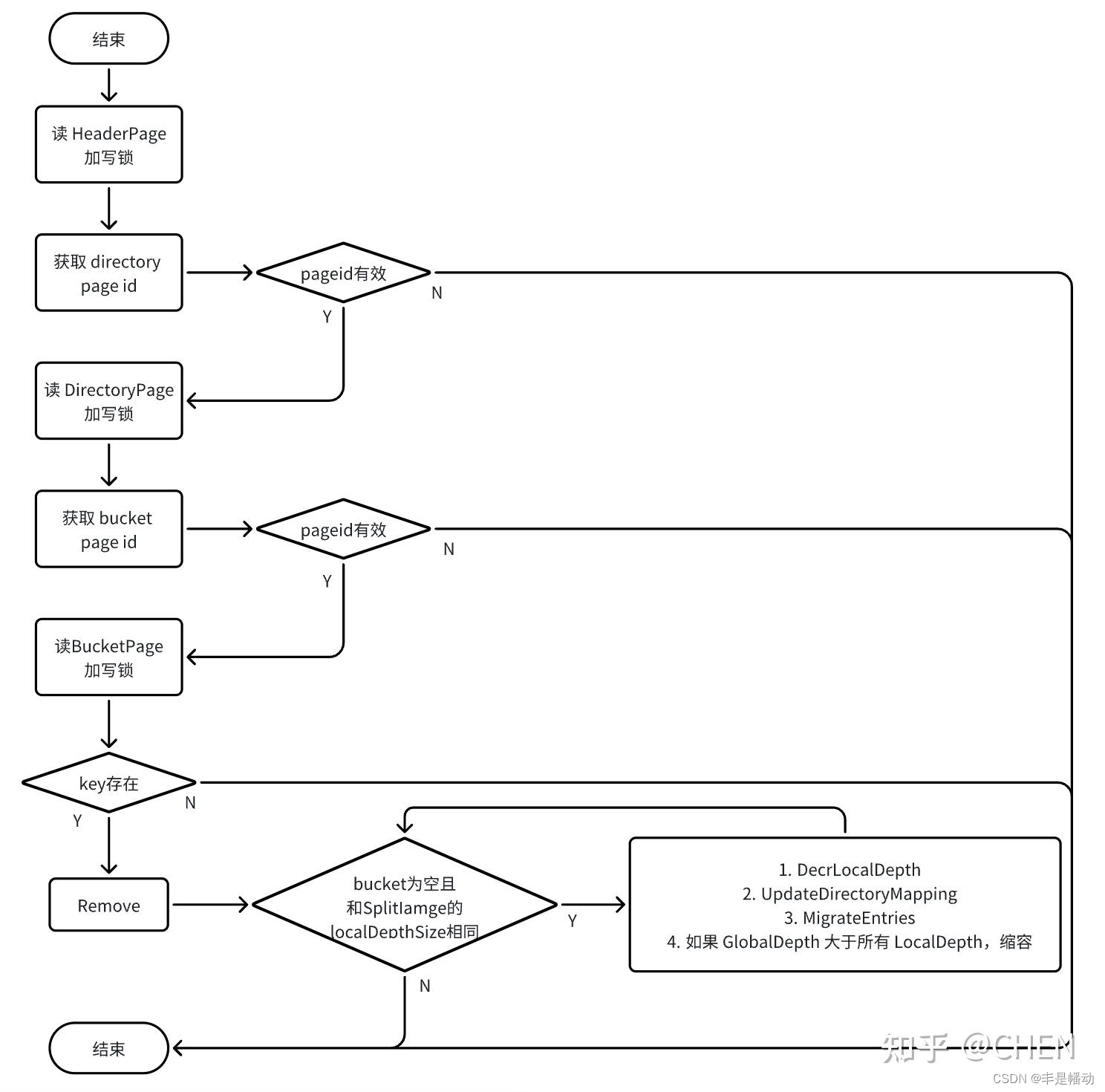
merge的情况,我们首先讲清楚什么情况下需要merge
这个bucket的local depth不为0,且大于0,对应的split bucket的local depth相同,并且两个bucket其中有一个为空即可。
因此,我们在merge的过程中,即使该bucket不为空,但是对应的split bukcet可能为空,因此每次都需要对两个bucket进行检查:
if (merge_local_depth != local_depth || (!check_bucket->isempty() && !merge_bucket->isempty())) { break; }
这个判断分支就是,如果两个bucket的depth不相等,或者是两个bucket的都不是空的,那么就中止
我们只要将两个bucket中其中非空的那个bucket的page拿来共用即可,将空的bucket的page进行drop和delete处理。
2.7.2 代码
template <typename k, typename v, typename kc>
auto diskextendiblehashtable<k, v, kc>::remove(const k &key, transaction *transaction) -> bool {
uint32_t hash = hash(key);
writepageguard header_guard = bpm_->fetchpagewrite(header_page_id_);
auto header_page = header_guard.asmut<extendiblehtableheaderpage>();
uint32_t directory_index = header_page->hashtodirectoryindex(hash);
page_id_t directory_page_id = header_page->getdirectorypageid(directory_index);
if (directory_page_id == invalid_page_id) {
return false;
}
header_guard.drop();
writepageguard directory_guard = bpm_->fetchpagewrite(directory_page_id);
auto directory_page = directory_guard.asmut<extendiblehtabledirectorypage>();
uint32_t bucket_index = directory_page->hashtobucketindex(hash);
page_id_t bucket_page_id = directory_page->getbucketpageid(bucket_index);
if (bucket_page_id == invalid_page_id) {
return false;
}
writepageguard bucket_guard = bpm_->fetchpagewrite(bucket_page_id);
auto bucket_page = bucket_guard.asmut<extendiblehtablebucketpage<k, v, kc>>();
bool res = bucket_page->remove(key, cmp_);
bucket_guard.drop();
if (!res) {
return false;
}
auto check_page_id = bucket_page_id;
readpageguard check_guard = bpm_->fetchpageread(check_page_id);
auto check_page = reinterpret_cast<const extendiblehtablebucketpage<k, v, kc> *>(check_guard.getdata());
uint32_t local_depth = directory_page->getlocaldepth(bucket_index);
uint32_t global_depth = directory_page->getglobaldepth();
while (local_depth > 0) {
// 获取要合并的桶的索引
uint32_t convert_mask = 1 << (local_depth - 1);
uint32_t merge_bucket_index = bucket_index ^ convert_mask;
uint32_t merge_local_depth = directory_page->getlocaldepth(merge_bucket_index);
page_id_t merge_page_id = directory_page->getbucketpageid(merge_bucket_index);
readpageguard merge_guard = bpm_->fetchpageread(merge_page_id);
auto merge_page = reinterpret_cast<const extendiblehtablebucketpage<k, v, kc> *>(merge_guard.getdata());
if (merge_local_depth != local_depth || (!check_page->isempty() && !merge_page->isempty())) {
break;
}
if (check_page->isempty()) {
bpm_->deletepage(check_page_id);
check_page = merge_page;
check_page_id = merge_page_id;
check_guard = std::move(merge_guard);
} else {
bpm_->deletepage(merge_page_id);
}
directory_page->decrlocaldepth(bucket_index);
local_depth = directory_page->getlocaldepth(bucket_index);
uint32_t local_depth_mask = directory_page->getlocaldepthmask(bucket_index);
uint32_t mask_idx = bucket_index & local_depth_mask;
uint32_t update_count = 1 << (global_depth - local_depth);
for (uint32_t i = 0; i < update_count; ++i) {
uint32_t tmp_idx = (i << local_depth) + mask_idx;
updatedirectorymapping(directory_page, tmp_idx, check_page_id, local_depth, 0);
}
}
while (directory_page->canshrink()) {
directory_page->decrglobaldepth();
}
return true;
}
task 4 concurrency control
使用readpageguard和writepageguard保证线程安全。task3 已经实现了,什么没改就过了。
需要注意的点:
growshrinktest:这个的缓冲池容量只有3,在 insert 和 remove 过程中,如果一个 pageguard 已经不需要再使用了,可以提前手动 drop 而不是等离开作用域再进行析构。我的建议是只要得到了directory_id就把header的解开。directory和bucket不急着解,运行不通过再加drop();如果提交有:page4 not exist那就是drop早了,如果是:0000000000xread memory就是drop晚了。
通过截图
这个代码调的我想死,网上代码基本没有,快写完了才找到个。之前主要都是复制别人的,也不用怎么调,看懂了稍微改改就行,这个project直接给我当头一拳。本地测试也不全,不想自己写只能强行把线上网站当调试器用,主要卡住的还是内存的加锁释放,光通过growshrinktest就差不多花了3天。改完了发现也不是很难,蒙着改肯定慢啊!另外代码写的极其粗糙,只能说是过了,性能是不存在的。改不动了,真的改不动了,等哪天变成大佬了再说吧。
参考文章
[1]https://blog.csdn.net/cpp_juruo/article/details/134859050?spm=1001.2014.3001.5506 (【cmu 15-445】proj2 hash index)
[2]https://blog.csdn.net/qq_58887972/article/details/137065392?spm=1001.2014.3001.5502(cmu15445 2023fall project2)
[3]https://blog.csdn.net/p942005405/article/details/84644069(c++ 之 std::move 原理实现与用法总结)
[4]https://zhuanlan.zhihu.com/p/679864158(cmu15-445 2023 fall project#2 - extensible hash index)
[5]https://zhuanlan.zhihu.com/p/622221722?utm_campaign=&utm_medium=social&utm_psn=1758461816148398080&utm_source=qq(cmu 15-445 p1 extendible hash table 可扩展哈希详细理解)
[6]https://blog.csdn.net/markssa/article/details/135646298?spm=1001.2014.3001.5502([15-445 fall 2023] p2代码解析)
[7]https://zhuanlan.zhihu.com/p/686889091(cmu 15445 2023fall project2)
[8]https://zhuanlan.zhihu.com/p/690666760(cmu 15-445 bustub 2023-fall project 2 extendible hash index 思路分享)
[9]https://zhuanlan.zhihu.com/p/664444839(cmu15-445(2023fall)-project#2: extendible hash index)



发表评论