zookeeper:分布式系统的心脏
引言
在当今的分布式计算环境中,协调和管理服务是一项关键任务。zookeeper,作为一个开源的分布式协调服务,已经成为许多分布式系统中的核心组件。本文将带你深入了解zookeeper的功能、架构以及它在分布式系统中的作用。
什么是zookeeper?
zookeeper是一个分布式服务框架,由雅虎开源,现在由apache软件基金会维护。它提供了一系列简单的原语,用于构建分布式应用,并确保这些应用在大规模分布式系统中的协调一致性。
zookeeper的核心功能
1. 数据模型和层次命名空间
zookeeper有一个类似于文件系统的数据模型,以树形结构组织数据。这棵树中的每个节点被称为“znode”,每个znode可以存储数据,并且有子节点。
2. 状态同步
zookeeper确保所有客户端看到的服务视图是一致的。当发生任何变化(如节点创建、删除或数据更新)时,zookeeper会同步这些变化到所有客户端。
3. 原子操作
zookeeper支持一系列原子操作,如创建节点、删除节点、设置数据等。这些操作确保了在并发环境中的数据一致性。
4. 顺序访问
zookeeper为每个更新操作分配一个全局唯一的递增编号,这允许客户端通过这个编号来顺序访问数据。
5. 高可用性
zookeeper设计为高可用性系统。它可以在集群中运行,即使部分服务器发生故障,整个系统仍然可以继续工作。
zookeeper的架构
zookeeper运行在服务器集群上,这些服务器被称为“zookeeper集群”。集群中的服务器分为以下几种角色:
1. leader
leader负责处理所有写操作请求。它还负责同步集群中所有服务器的状态。
2. follower
follower负责处理读操作请求,并在写操作时转发给leader。它们还参与leader选举过程。
3. observer
observer是可选的角色,它们只处理读操作请求,不参与写操作的同步过程,也不参与leader选举。它们用于扩展集群的读能力。
zookeeper命令行操作
服务端常用命令
-
启动 zookeeper 服务:
./zkserver.sh start -
查看 zookeeper 服务状态:
./zkserver.sh status -
停止 zookeeper 服务:
./zkserver.sh stop -
重启 zookeeper 服务:
./zkserver.sh restart
zookeeper客户端常用命令
-
连接zookeeper服务端:
./zkcli.sh –server ip:port -
断开连接:
quit -
显示指定目录下节点
ls 目录 -
创建持久化节点:
create /节点path # 创建持久化节点但不设置值 create /节点path value # 创建持久化节点并且设置值 -
获取节点值:
get /节点path -
设置节点值:
set /节点path value -
删除单个节点:
delete /节点path -
删除包含子节点的节点:
deleteall /节点path -
创建临时节点:
create -e /节点path value -
创建顺序节点:
create -s /节点path value -
查询节点详细信息:
ls -s /节点path
hbase:面向列的分布式数据库
引言
在当今的大数据时代,处理海量数据的需求日益增长。hbase,作为一个开源的、面向列的分布式数据库,已经成为大数据存储和处理的重要工具。本文将带你深入了解hbase的特点、架构以及它在实际应用中的作用。
什么是hbase?
hbase是基于google的bigtable模型构建的,是apache hadoop生态系统的一部分。它是一个分布式、可扩展、支持列存储的数据库,适用于非结构化和半结构化数据的大规模存储。
hbase的核心特点
1. 面向列的存储
与传统的行存储数据库不同,hbase采用面向列的存储方式。这意味着每个列族(column family)都存储在不同的文件中,可以独立访问,提高了读取效率。
2. 可扩展性
hbase可以轻松地水平扩展,只需添加更多的服务器到集群中即可。这使得hbase能够处理pb级别的数据。
3. 稳定性和可靠性
hbase构建在hadoop和hdfs之上,继承了hadoop的高可用性和可靠性。
4. 实时读写
hbase支持实时读写操作,适用于需要快速响应的应用场景。
5. 灵活的数据模型
hbase的数据模型非常灵活,可以存储任意类型的数据,包括结构化、半结构化和非结构化数据。
hbase的架构
hbase架构主要包括以下几个组件:
1. hmaster
hmaster负责管理集群中的regionserver,如分配region、负载均衡、元数据管理等。
2. regionserver
regionserver负责处理客户端的读写请求,并管理一组region。每个region包含一个表的一部分数据。
3. region
region是hbase表的水平分区,每个region包含一个起始行键和一个终止行键之间的所有数据。
4. hdfs
hbase使用hadoop分布式文件系统(hdfs)作为其底层存储系统,确保了数据的可靠性和高可用性。
hbase组件角色:
- hmaster
功能:
1.监控 regionserver
2.处理 regionserver 故障转移
3.处理元数据的变更
4.处理region 的分配或移除
5.在空闲时间进行数据的负载均衡
6.通过 zookeeper 发布自己的位置给客户端
- hregionserver
功能:
1.负责存储 hbase 的实际数据
2.处理分配给它的 region
3.刷新缓存到 hdfs
4.维护wal
5.执行压缩
6.负责处理 region 分片
-
hfile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
-
store
hfile 存储在 store 中,一个 store 对应 hbase 表中的一个column family列族(列簇)。
-
memstore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 wal中之后,regsionserver 会在内存中存储键值对。
hbase部署与启动
(1)下载、解压缩,在/etc/profile全局配置文件中添加
export hbase_home=/export/servers/hbase-2.4.5
export path=$path:$hbase_home/bin
(2)配置hbase-env.sh
export java_home=/export/servers/jdk1.8.0_161
export hbase_manages_zk=false # 使用外部的zookeeper
(3)配置hbase-site.xml
<configuration>
<!-- hbase数据存放的目录,若用本地目录,必须带上file://,否则hbase启动不起来 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://my2308-host:9000/hbase</value>
</property>
<!-- zk的位置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
<description>my2308-host:2181</description>
</property>
<!--hbase.cluster.distributed表示是否分布式部署,指定为true-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- hbase主节点的位置 -->
<property>
<name>hbase.master</name>
<value>my2308-host:60000</value>
</property>
</configuration>
(3)拷贝zookeeper的conf/zoo.cfg到hbase的conf/下
(4)启动hbase
执行start-hbase.sh脚本
注意:为了方便启动,可在/etc/profile中添加环境变量
export hbase_home=/export/servers/hbase-2.4.5
export path=$path:$hbase_home/bin
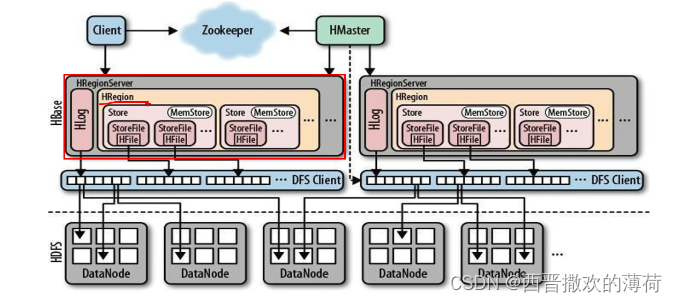
hbase对zookeeper的依赖
hbase依赖于zookeeper来实现其高可用性和分布式特性。没有zookeeper,hbase将无法有效地管理其分布式环境中的各种操作和状态变化。
总结
简而言之,zookeeper对于hbase来说是一个关键组件,它提供了分布式环境中的协调服务,确保了hbase集群的稳定性和一致性。两者共同工作,使得hbase成为一个可靠、可扩展的分布式数据库系统。


发表评论