hadoop单机安装配置 图文保姆级教程—全网最全
文章目录
一、安装前需要
1.vmware安装配置:
个人博客:https://duanyx.blog.csdn.net/article/details/136539021
2.相关hadoop软件包下载
(1)jdk-8u162-linux-x64.tar
(2)hadoop-3.1.3.tar
已分享到百度网盘:
链接:https://pan.baidu.com/s/1090zbeq2afe3zefpuja6ig?pwd=0616
提取码:0616
3.ubuntu镜像下载
(1).使用国内镜像下载清华大学开源软件镜像站
(2).跳转到网址后下滑页面选择 >>> ubuntu-releases
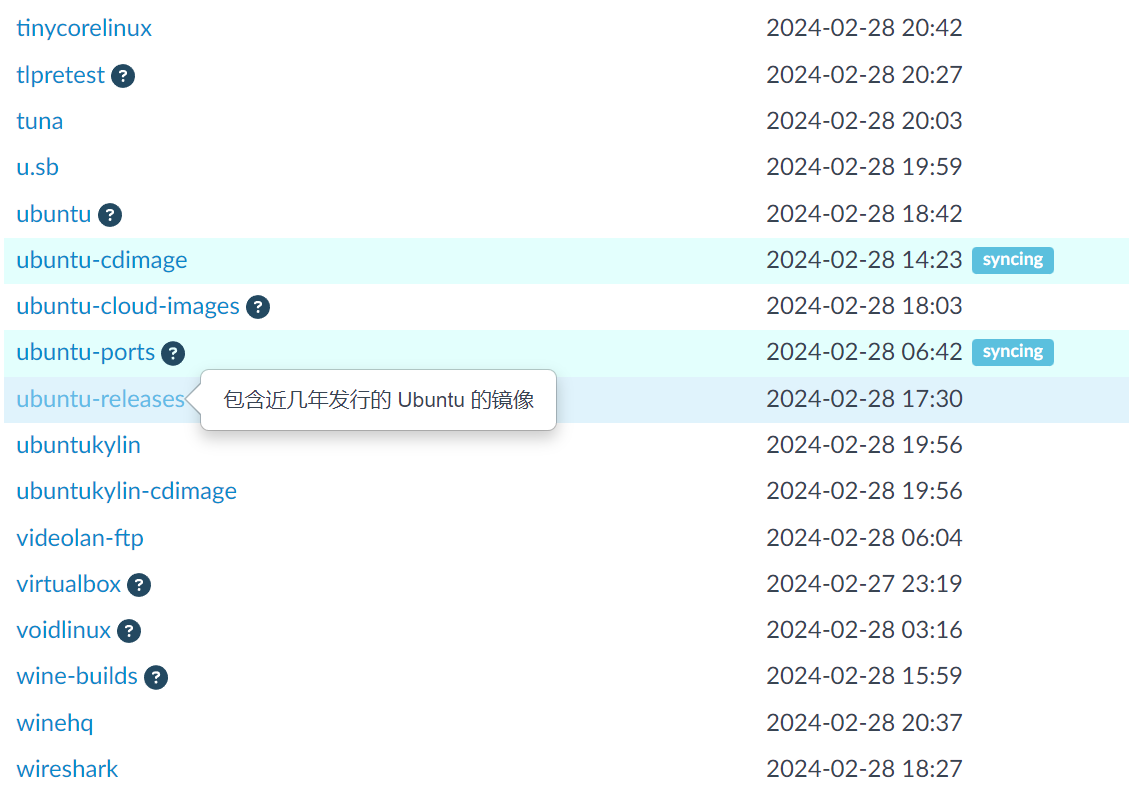
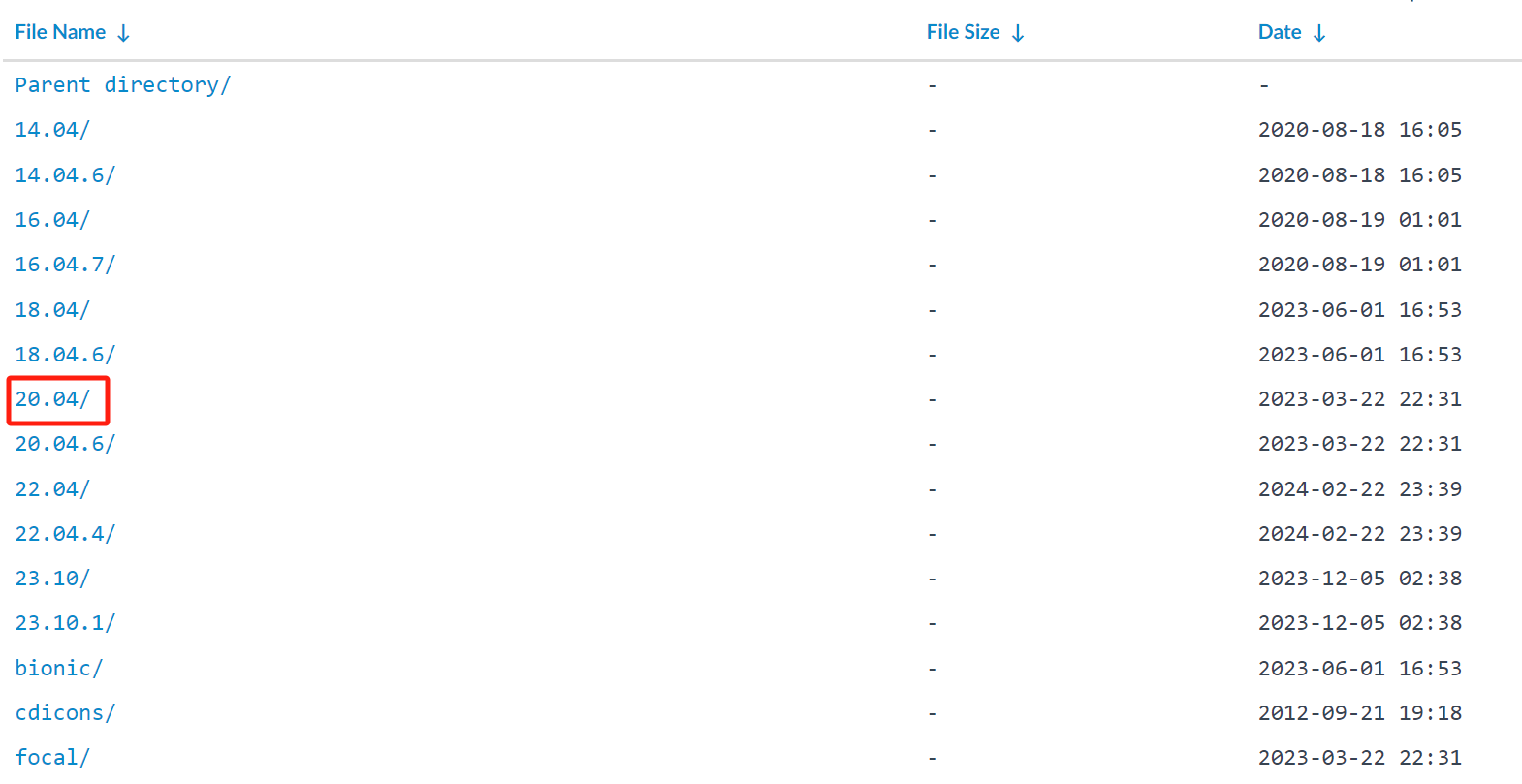
(3).根据个人体验,推荐选择20.04版本 >>> (点击)下图框住内容即可
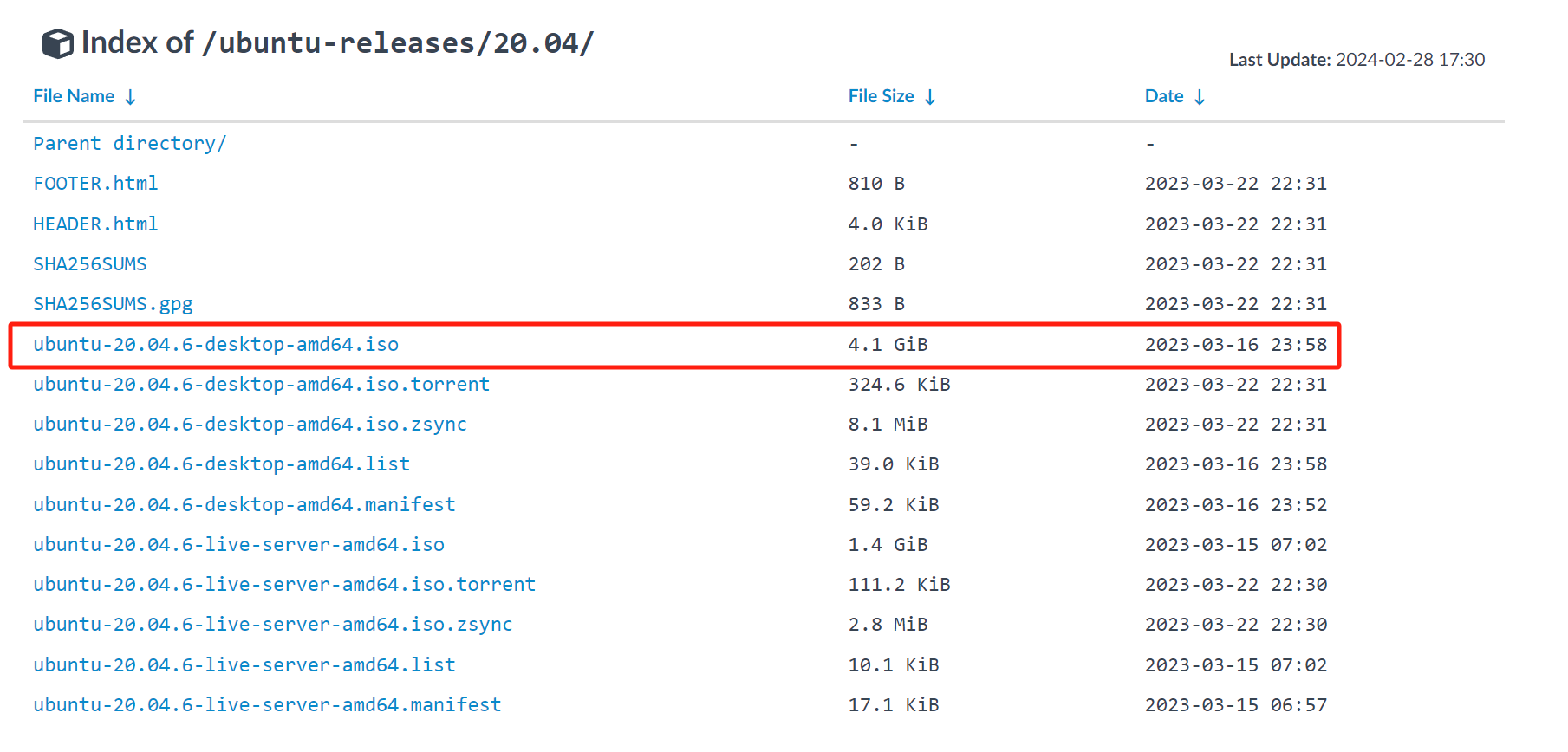
(4).选择“ubuntu-20.04.4-desktop-amd64.iso”进行下载 >>> (点击)下图框住内容即可
(5).下载后记得放置合适的位置,尽量不要放在c盘
到这里前期的准备工作就做好了,有的教程会让你安装一些远程传输工具,ubuntu系统中其实自带的
二、ubuntu系统安装
前提声明:已安装可忽略此步(但要有远程传输vmwaretools,和英文版的ubuntu)
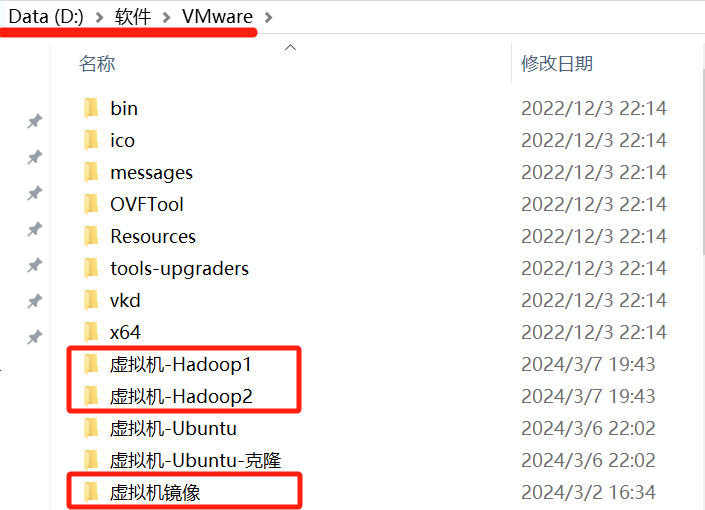
1.创建文件夹(此步为让大家安装方便,可忽略)
我在d盘放置了一个:软件,然后里面放置了一个:vmware,然后vmware中放置一个:虚拟机-hadoop1,虚拟机hadoop2,虚拟机镜像三个文件
不要管《虚拟机-ubuntu》那两个文件,是我之前安装好的,看红框框即可
2.文件操作
把下载好的镜像文件放置虚拟机镜像文件中
3.打开vmware
4.点击创建新的虚拟机

5.选择自定义

6.默认操作
7.稍后安装
8.选择linux,ubuntu64位
9.放置在d:\软件\vmware\虚拟机-hadoop1文件中
10.自定义下一步即可
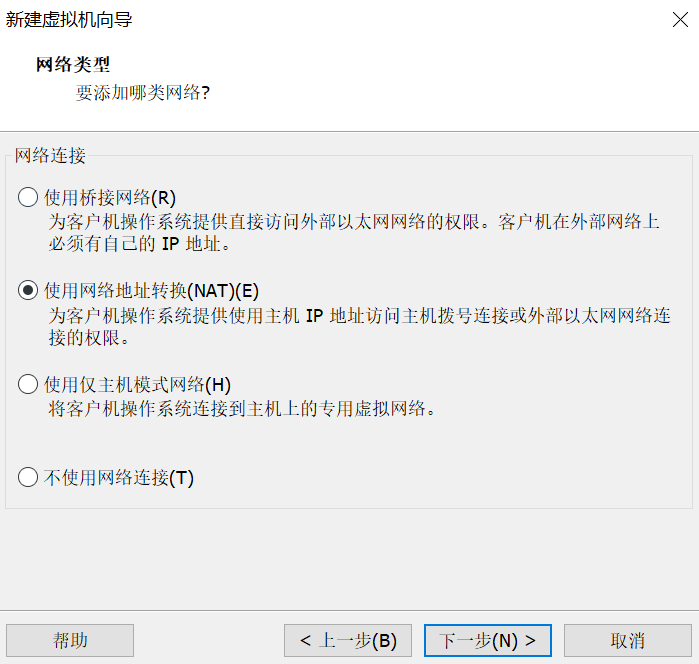
11.使用网络地址转换
12.默认推荐即可
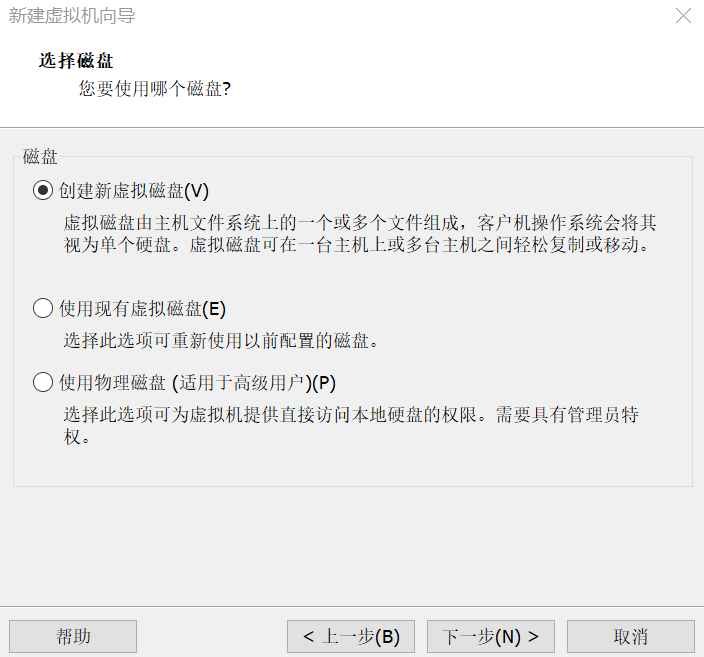
13.创建新虚拟磁盘
14.将虚拟机拆分成多个文件
此步中,有的教程是单文件,其实都可以,无伤大雅
15.下一步,默认选择即可
16.选择自定义硬件
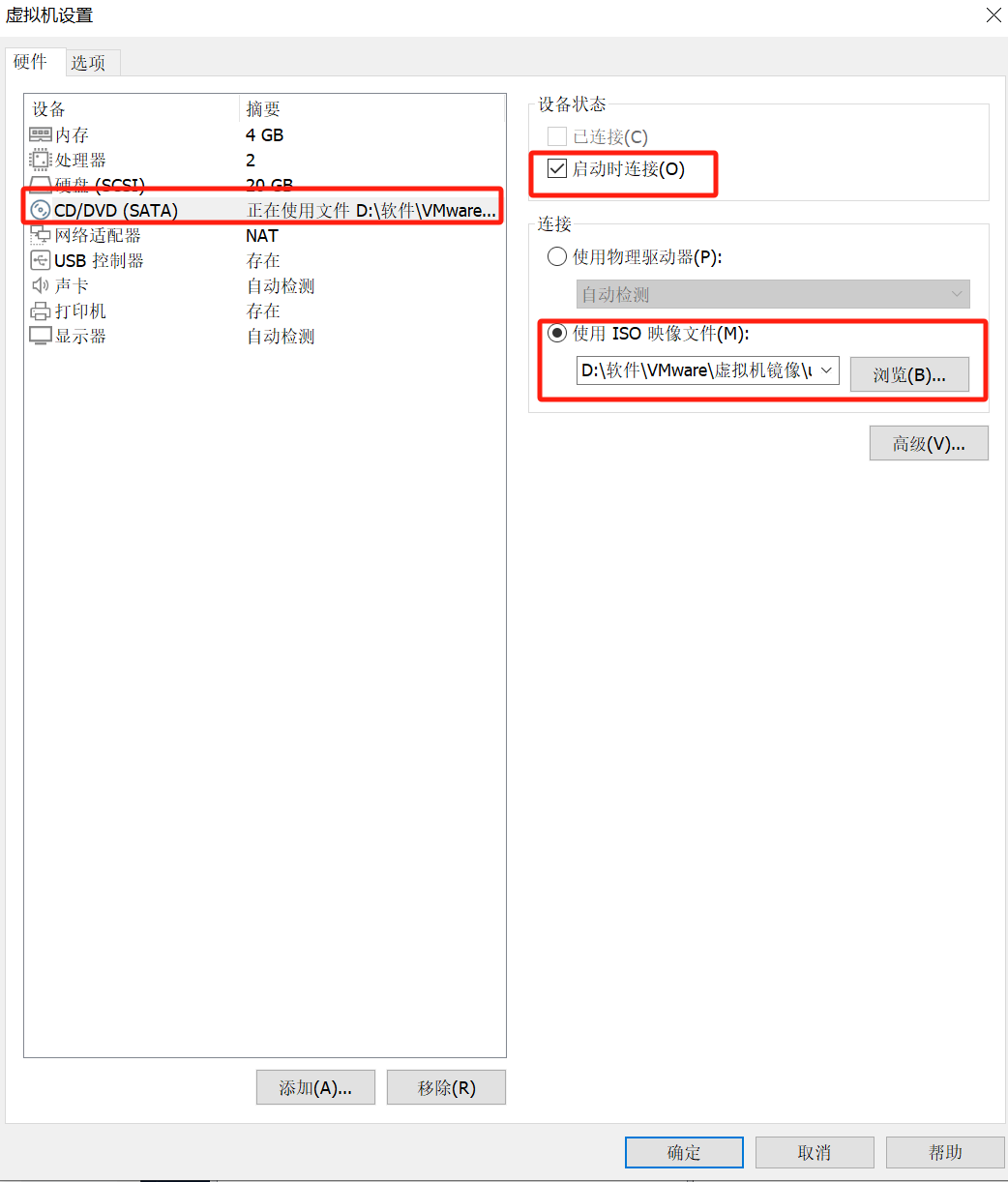
17.在cd/dvd中,使用iso映像文件,选择安装好的镜像地址,并选择启动时连接
如果不选择这一步,可能会导致虚拟机找不到镜像而无法启动
18.开启虚拟机,点击绿色小标箭头即可
18.等待启动
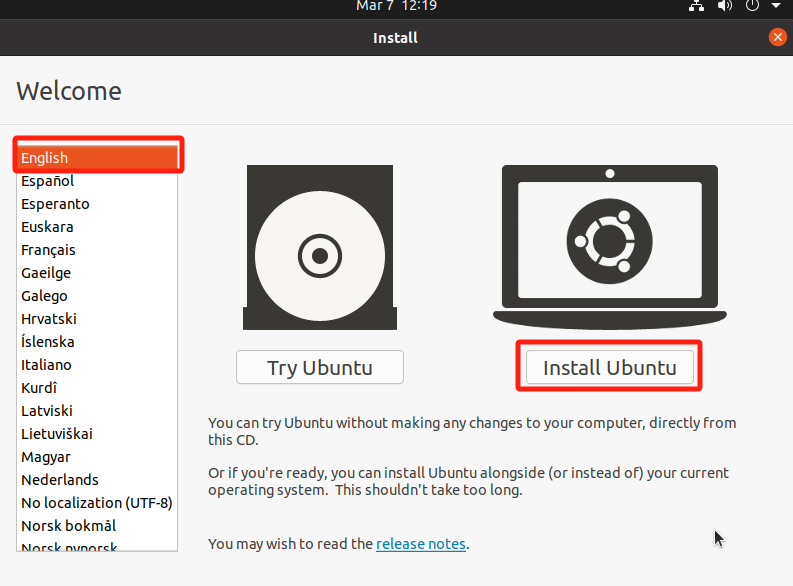
19.选择语言,默认english,就选择englis,然后点击install ubuntu
20.点击右下角continue
21.点击右下角continue
22.点击install now
23.点击continue
24.点击咋们国家的地图,显示:shanghai,然后点击continue
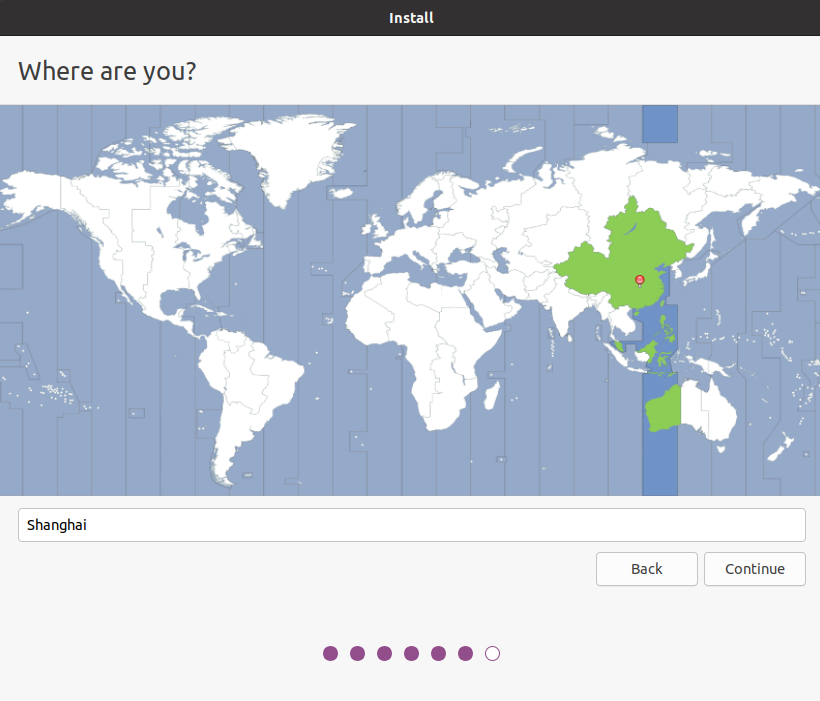
25.按照下图配置
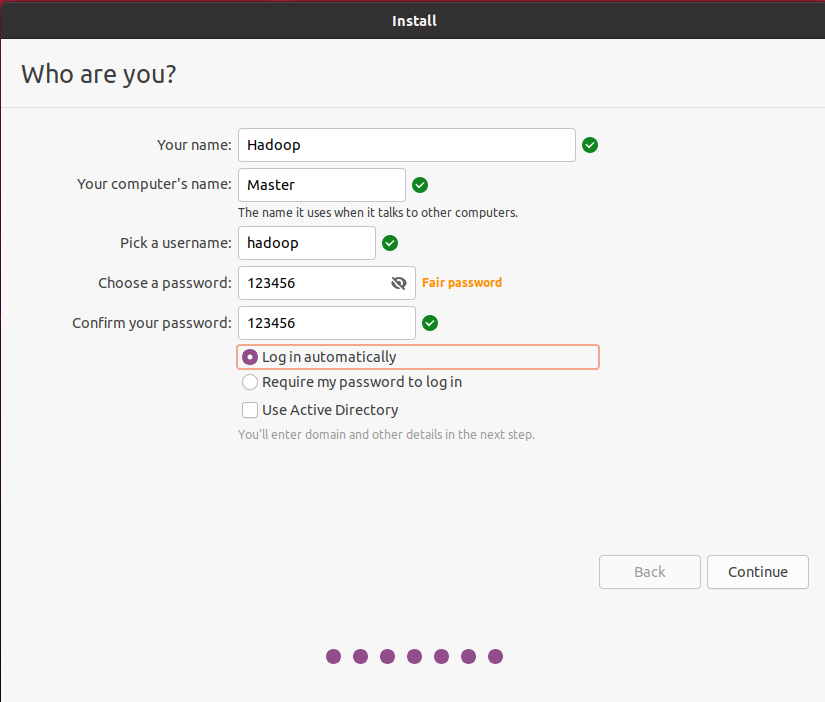
your name和your computer’s name,这里就按照我的来,因为大部分教程都是在你创建你自己的用户之后又重新创建名称为:hadoop的用户,并且把computer’s name改为了master,这里直接改,就避免多此一举了
最后选择log in automatically(自动登陆)
点击continue
26.等待install,这里会比较慢
27.选择重启:restart now
注:到了黑框框的界面的之后记得回车一下,这里没有截图上
28.重启后ubuntu系统就安装好了
到这里ubuntu系统就安装好了,下面是对hadoop集群的配置
三、hadoop单机+伪分布式配置
1.更新apt
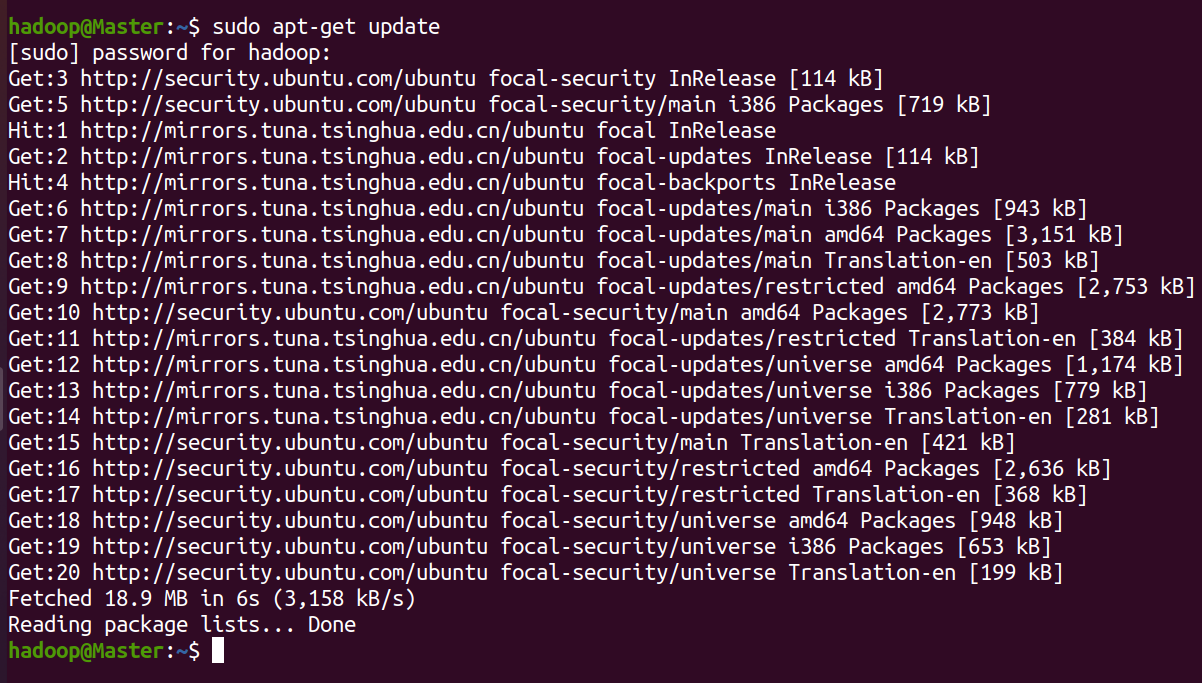
更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。
按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update
输入命令后输入用户密码即可执行操作
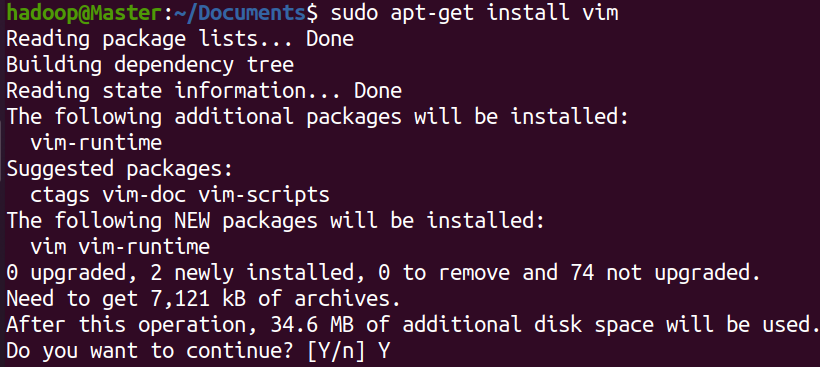
2.安装vim
vim是文本编辑器,用于对文件的操作
sudo apt-get install vim
输入命令后输入y确定即可
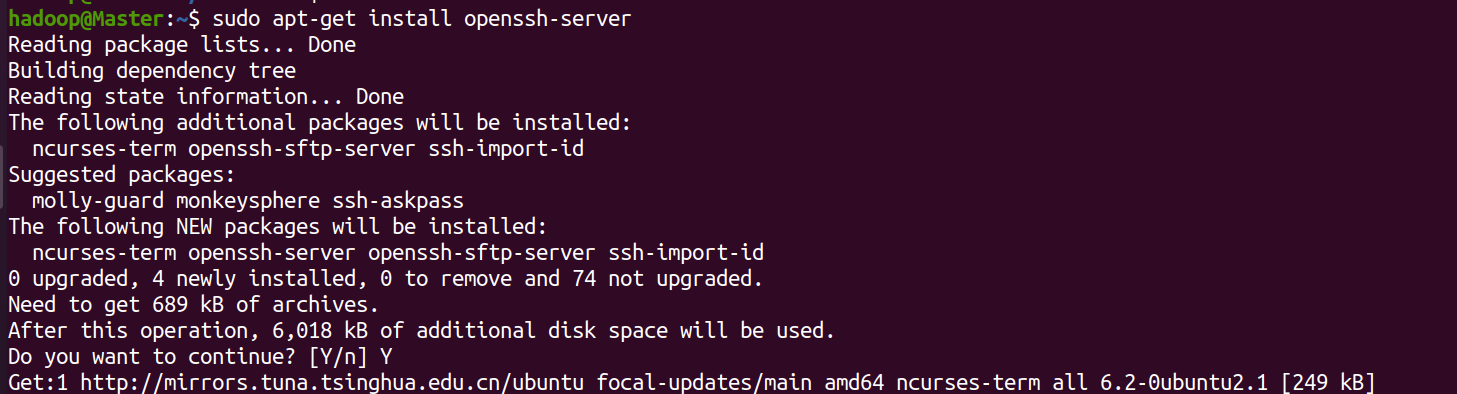
3.安装ssh
输入命令后,会提示输入:y
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
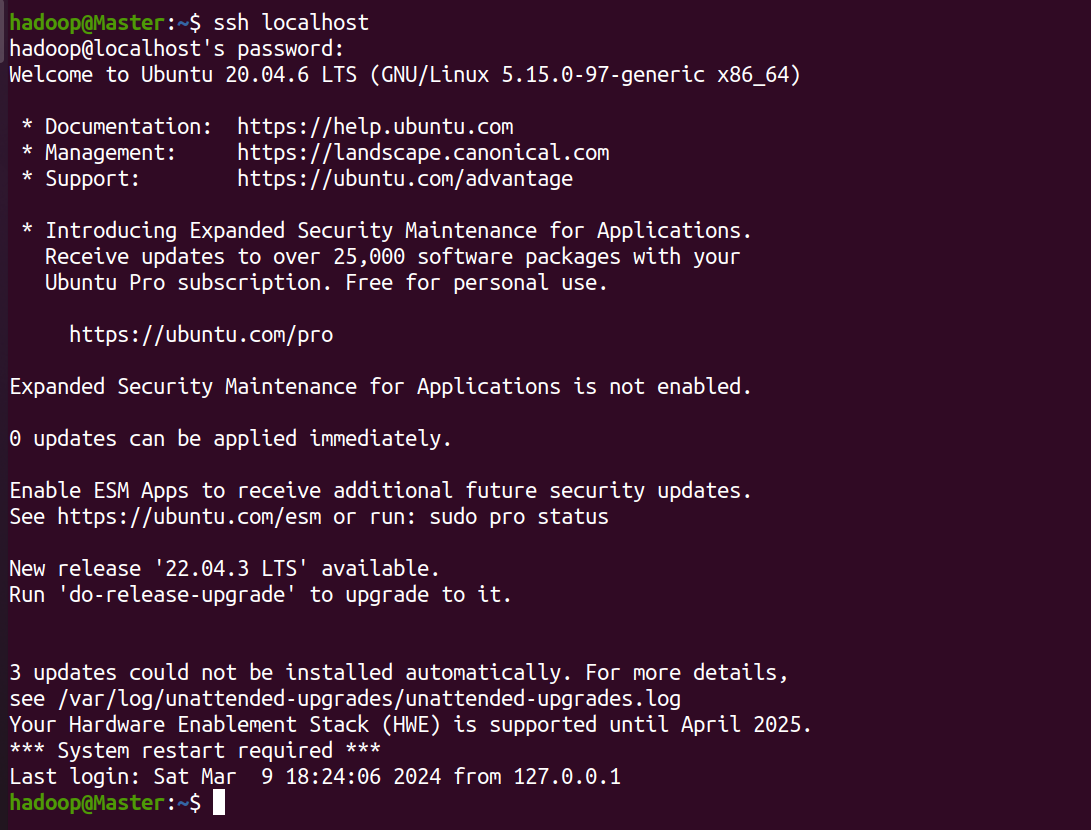
ssh localhost
此时会有如下提示(ssh首次登陆提示),输入 yes 。然后按提示输入密码 ,这样就登陆到本机了。
4.配置ssh无密码登陆
但这样登陆是需要每次输入密码的,我们需要配置成ssh无密码登陆比较方便。
退出刚才的 ssh
exit
回到我们原先的终端窗口
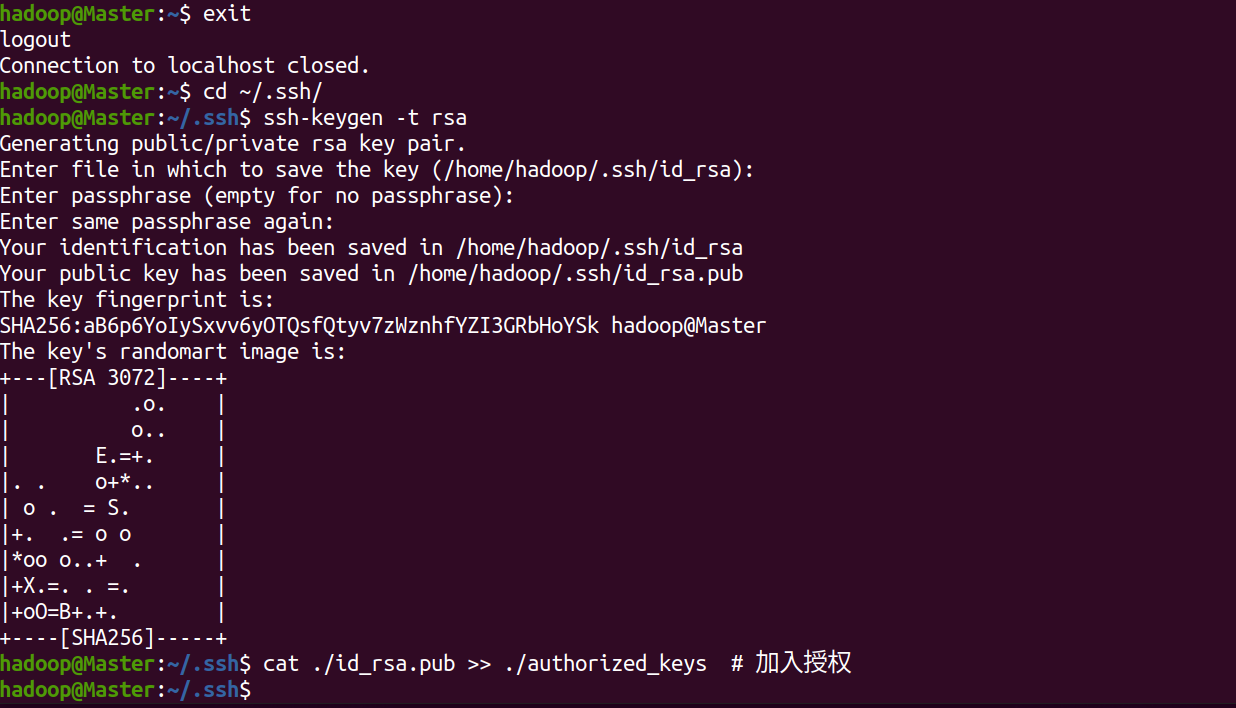
cd ~/.ssh/
利用 ssh-keygen 生成密钥,会有提示,都按回车就可(大概3个)
ssh-keygen -t rsa
并将密钥加入到授权中
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
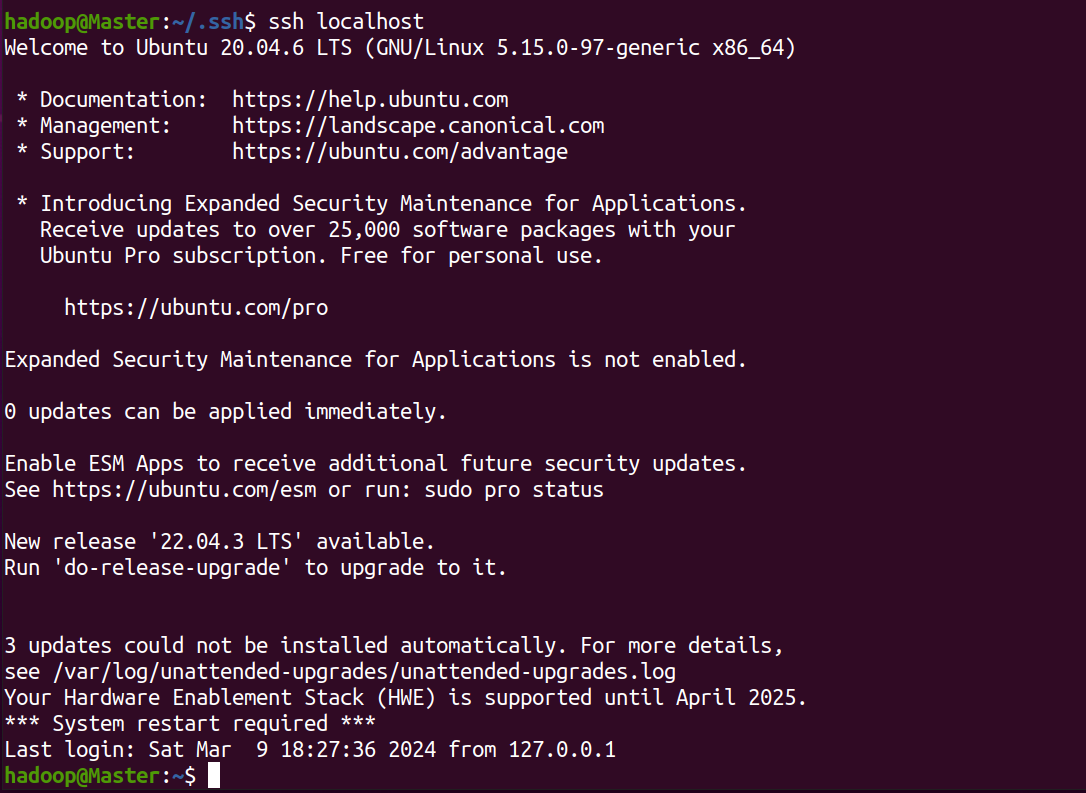
在使用ssh localhost即可无密码登陆
ssh localhost
5.安装java环境
在安装java和hadoop时都需要使用vmwaretools工具,跟着上述的ubuntu系统安装,vmwaretools是安装好的,这里直接使用
把下载好的jdk-8u371-linux-x64.tar.gz下载到本地电脑,保存在虚拟机的“/home/linziyu/downloads/”目录下。
点击桌面的hadoop文件

点击downloads文件
如图所示
直接把下载好的压缩包拖动到虚拟机的downloads文件夹内
为了下面hadoop安装的方便,也把下载好的hadoop的安装包拖动到downloads文件夹内
如图所示
cd /usr/lib
创建/usr/lib/jvm目录用来存放jdk文件
sudo mkdir jvm
进入hadoop用户的主目录
cd ~
进入到downloads目录下
cd downloads
把jdk文件解压到/usr/lib/jvm目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -c /usr/lib/jvm
jdk文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下
cd /usr/lib/jvm
ls

在/usr/lib/jvm目录下有个jdk1.8.0_162目录。下面继续执行如下命令,设置环境变量
cd ~
vim ~/.bashrc
上面命令使用vim编辑器打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容
(“i”,进入编辑)
(编辑完成后,先esc,然后输入:wq,回车)
export java_home=/usr/lib/jvm/jdk1.8.0_162
export jre_home=${java_home}/jre
export classpath=.:${java_home}/lib:${jre_home}/lib
export path=${java_home}/bin:$path
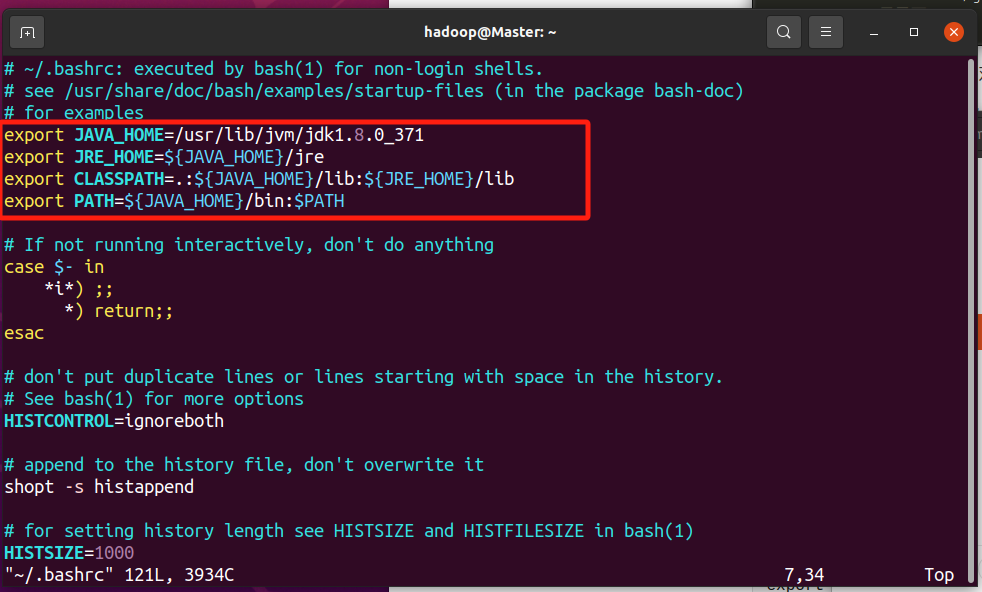
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功
java -version
如果能够在屏幕上返回如下信息,则说明安装成功

至此,就成功安装了java环境。下面就可以进入hadoop的安装。
6.安装hadoop
解压到/usr/local中
sudo tar -zxf ~/downloads/hadoop-3.1.3.tar.gz -c /usr/local
将文件夹名改为hadoop
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop
修改文件权限
sudo chown -r hadoop ./hadoop
hadoop 解压后即可使用。输入如下命令来检查 hadoop 是否可用,成功则会显示 hadoop 版本信息,如下图所示。
cd /usr/local/hadoop
./bin/hadoop version

7.单机配置(非分布式)
此步骤为单机hadoop的一个例子,可跳过此步骤
在此我们选择运行 grep 例子,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
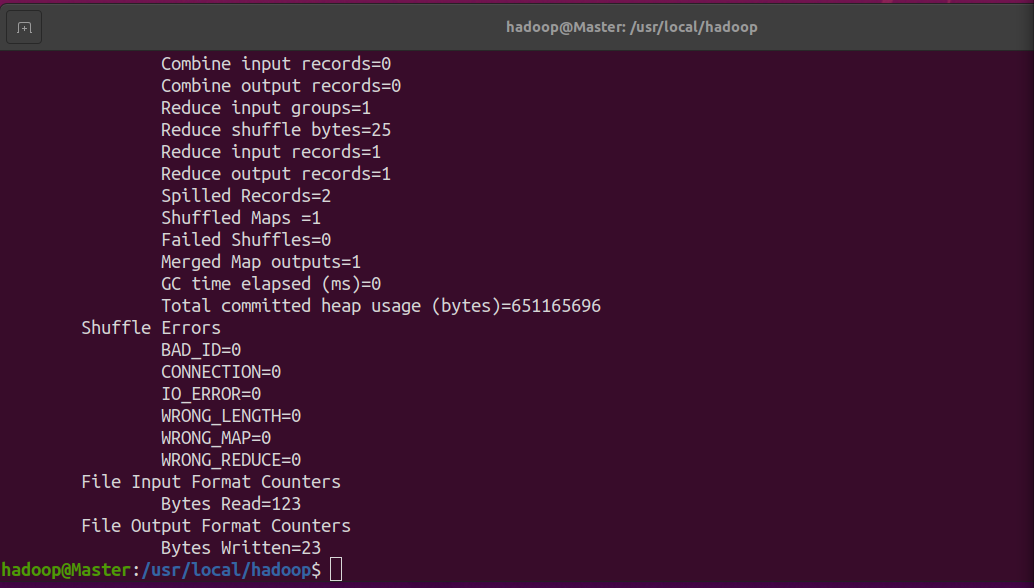
注意,hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除
rm -r ./output



发表评论