大数据开发之Hive案例篇12:HDFS rebalance 一例
公司的离线数仓是CDH集群,19个节点,HDFS存储空间大约400TB左右,使用量在200TB左右。由于历史遗留的问题,数据仓库需要重构,新旧数仓在一段时间内需要并存,此时HDFS空间救不够了。Kafka出了问题,选主过程受到ZK的影响,导致生产者写的时候找不到主节点,进而导致数据丢失。于是申请增加6个节点,每个节点挂20T的存储,累积给HDFS增加120TB左右空间。(这还是HDFS rebalance执行了一天多的时候的截图)新增加节点与旧节点之间数据分布不均匀。
一. 问题描述
公司的离线数仓是cdh集群,19个节点,hdfs存储空间大约400tb左右,使用量在200tb左右。
由于历史遗留的问题,数据仓库需要重构,新旧数仓在一段时间内需要并存,此时hdfs空间救不够了。
于是申请增加6个节点,每个节点挂20t的存储,累积给hdfs增加120tb左右空间。
二. 解决方案
2.1 增加节点
通过cloudera manager 将新增加的6台机器加入到集群。
增加完节点后
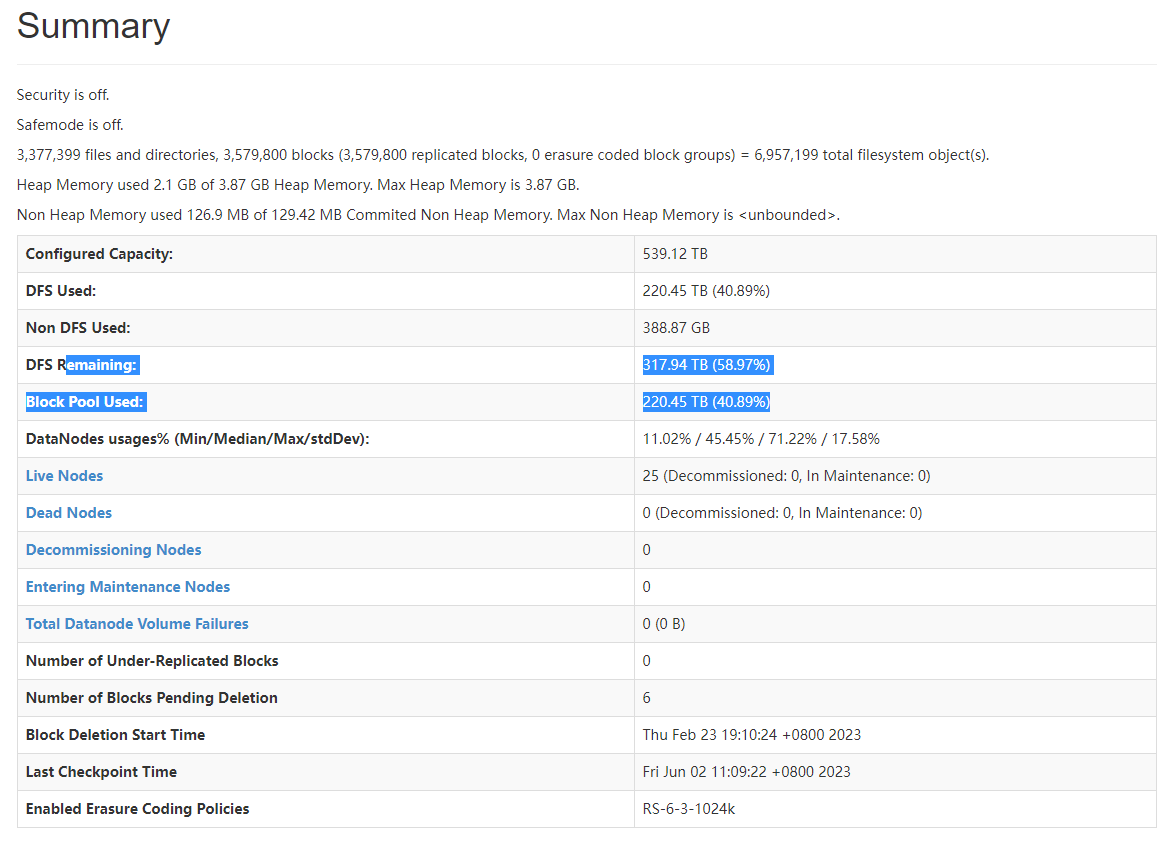
2.2 rebalance
节点间数据分布不均匀:
新增加节点与旧节点之间数据分布不均匀
(这还是hdfs rebalance执行了一天多的时候的截图)

rebalance耗时:

rebalance后节点数据分布情况:

2.3 rebalance引发的问题
rebalance引发的问题:
retrying (13 attempts left). error: <class 'kafka.errors.notleaderforpartitionerror'>
kafka出了问题,选主过程受到zk的影响,导致生产者写的时候找不到主节点,进而导致数据丢失

相关文章:
-
在Windows中如何刷新和清除DNS缓存?这里提供了几个方法。…
-
-
Yum是一个Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包。更换yum源是为了使用y…
-
如果想修改 core 文件保存路径,可通过修改内核参数:echo "/tmp/corefile-%e-%p-%t" > /proc/sys/kernel/…
-
-
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。


发表评论