hadoop大数据技术
hadoop背景
hadoop生态圈
hadoop生态圈:
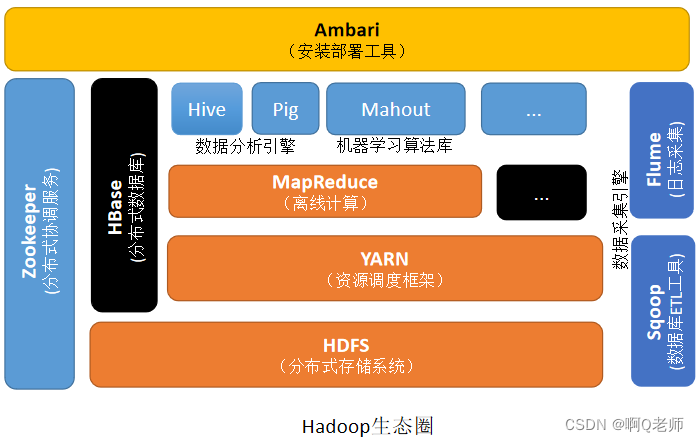
hadoop生态圈组件说明:

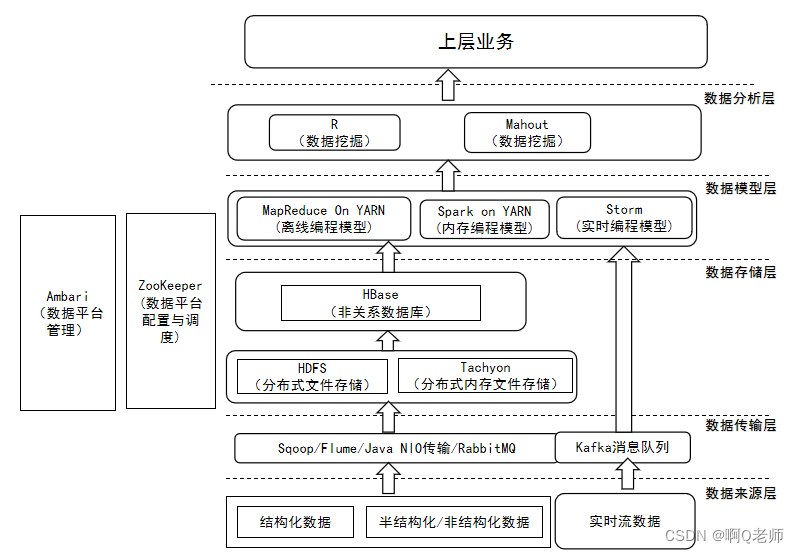
hadoop典型应用架构:
hadoop模式
- 单机模式:hadoop默认模式,在单机上按默认配置以非分布式模式运行的一个独立java进程,没有分布式文件系统hdfs,直接在本地操作的文件系统读写,一般仅用于本地mapreduce程序的调试。
- 伪分布式模式:单机上模拟一个分布式的环境,具备hadoop的主要功能,常用于调试程序。
- 完全分布式模式:也叫集群模式,hadoop的守护进程运行在由多台主机搭建的集群上,是真正的分布式环境,是用于实际的生产环境。
hdfs

概述
优点
- 高容错性,以数据复制多份并存储在集群的不同节点来实现数据容错。
- 高扩展性,hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高吞吐率,延时较低,可存储非常大的文件。
- 低成本,可构建在廉价机器上。
- 采用流式的数据访问方式,即一次写入,多次读取,保证数据一致性。
- 适合批处理
- 适合大数据处理
缺点
- 不适合低延迟数据访问:hadoop优化了高数据吞吐量,牺牲了获取数据的延迟,从而hadoop不适合低延迟数据访问,而hbase更适合低延迟访问需求。
- 不适合大量的小文件存储:namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。
- 不适合并发写入、文件随机修改
基本组成
namenode
其中:
edits 文件:记录操作日志,元数据的每一次变更操作都会被记录到edits中。
fsimage 文件:hdfs的元信息,namenode节点的元数据运行在内存中,为防止宕机数据丢失,每隔一段时间会将元数据持久化到磁盘中。
secondary namenode
datanode
yarn

yarn中应用(application)运行机制(流程):
yarn中任务进度监控:


发表评论