目录
1. hadoop
1.1 hadoop简介
hadoop现在已经是大数据领域事实上的标准,基本提到大数据,大家首先想到的就是hadoop。
在本文中,笔者会结合自己的实际使用经验,力求以简单易懂的语言讲清楚hadoop及其衍生生态下各个组件产生的背景,以及它们之间的关系,除了简述它们的作用之外,还会介绍它们各自的缺点,这个世上没有万金油,每项技术都有它适用的场景,也有它们的局限性。
1.2 大数据产生的时代背景
在21世纪初互联网技术井喷式发展,人类进入互联网时代,各类电商网站、博客、微博、新闻门户层出不穷,大家似乎无时无刻都在产生数据,数据开始野蛮增长,随之而来就是如此体量的数据如何存储和计算的问题,这也是大数据技术诞生的背景。
其实以hadoop为代表的大数据技术主要解决了以下2个问题:
1.3 hadoop产生的背景
hadoop诞生于nutch项目,项目目标是构建一个大型的全网搜索引擎,随着抓取的数据量越来越多,nutch项目遇到了严重的可扩展性问题,几乎与此同时,google发表了著名的3篇论文,为nutch提供了解决思路。
google的3篇论文发表于2003 ~ 2006年间,内容分别对应googlefilesystem、mapreduce和bigtable,前2项分别对应hadoop中的hdfs和mapreduce,在最初的hadoop设计中并没有bigtable的实现(这篇论文发布较晚),bigtable后面由hbase实现,并捐献给了apache社区。
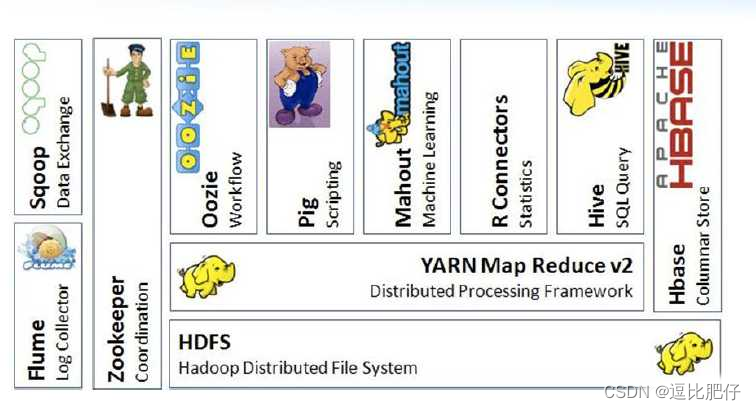
1.4 hadoop的核心组件
1.5 hadoop存在的问题
其实hadoop核心的3个组件中,hdfs和yarn仍在大规模使用,存在问题较大还是mapreduce:
2. spark
2.1 简介
正是由于mapreduce存在种种问题,所以才出现了spark,spark是一款用于处理大规模数据集的通用计算引擎,我们通常用它来替代hadoop中mapreduce,spark专注于的领域是计算,通用计算引擎的含义是它不依赖任何存储,既可以对hdfs上数据进行计算,也可以对关系型数据库、kafka、s3中的数据进行运算。

2.2 spark解决了什么问题
相比于mapreduce,我觉得spark主要有如下优点:
2.3 spark在hadoop生态中的作用
spark通常用于替代mapreduce,作为集群的计算引擎存在。
2.4 spark的缺点
虽然spark已经非常强大了,基本可以满足大数据场景下的计算需求,但是它还是有很多不足的地方:
3. hive
2.1 简介
前面已经提到mapreduce有开发难度较大,复杂任务编排困难的问题,hive就是为了解决这些问题而诞生的。
hive是一款数据仓库管理工具,也可以把它当成一种数据统计工具,hive以数据库形式管理hdfs上的目录和文件,hive可以将结构化数据映射成数据表,并使用类似sql的脚本语言(hiveql)操作数据,hive会将这些sql翻译为一连串的mapreduce任务运行。
虽然hive跟传统数据库很像,但它确实不是数据库,它仅仅是一个工具,如果以mysql的4层架构(连接层/服务层/引擎层/存储层)作为对比,那么hive也仅仅是实现到了服务层,hive本身不具备任何计算能力和存储能力,hive依赖mapreduce或spark作为其计算引擎,而hive处理的绝大部分数据都是hdfs上的文件。

2.2 hive的优点
2.3 hive在hadoop生态中的作用
在hadoop生态中,hive通常作为sql执行引擎存在,后续出现的sparksql也兼容hive语法规范。
hive常用于构建数据仓库,所以hive也可以作为集群数据文件的管理工具。
2.4 hive的缺点
2.5 hive和sparksql对比
2.6 hive和spark该如何选择
其实在实际生产过程中,hive和spark使用都比较多,它们各自有自己适用的场景。
2.7 pig
前文提到mapreduce存在种种问题,其实早在hive出现之前,pig就尝试解决这些问题,pig采用一种类似sql的piglatin语言来编排mapreduce任务,相比于直接编写mapreduce任务,pig已经可以节省很多人力。
但是apache pig却没有大规模使用起来,主要是后来者hive和spark比它更为优秀。piglatin相较于sql还是具有一定的学习成本,hiveql接近于mysql方言,只要会使用sql的人员都可以快速上手。与spark相比,pig更加不具备任何优势,spark书写更加简单,且代码可读性更强,不论是简单的查询还是复杂的分析任务,spark都可以轻松搞定,在执行效率方面,spark更是明显快于pig。
无论从哪种方面来看,apache pig都像是上个时代的产物,该项目已经很久没有更新了。

3. hbase
3.1 简介
hbase是hadoop database的缩写,意为hadoop数据库,是google经典3篇论文中bigtable的开源实现,它是一个功能完整的k-v数据库,主要用于存储海量的结构化和半结构化数据。
hbase将数据存储在hdfs上,hdfs保证了hbase数据的安全性和扩展性,理论上hdfs上能存多少数据,hbase就能存下多少数据,其实hbase的真正瓶颈在于rootregion的大小(存储元数据信息的region),只要元数据信息能存下,hbase中的数据量就可以无限增长。
在计算方面,hbase使用自己regionserver实现计算,并不依赖其它组件。关于hbase的知识恐怕几篇文章都介绍不完,这里不再深入介绍,大家只需简单了解hbase是个什么即可,后续有时间单独开篇博客介绍。

3.2 hbase的适用场景
其实在笔者的工作过程中,hbase使用的频率远远不如hive和spark,只有少量需要实时检索的场景才会用到hbase。
3.3 hbase的缺点
3.4 hbase的sql方案
3.4.1 phoenix
phoenix是hbase的sql引擎插件,使得用户可以以sql方式操作hbase,phoenix支持多表查询,并提供了多种二级索引方案。

phoenix的优点:
phoenix的缺点:
3.4.2 hbasestoragehandler
hbasestoragehandler是hive提供的用于查询hbase的处理器,通过这个处理器,就可以在hive中以sql形式查询hbase表。
hbasestoragehandler的优点:
hbasestoragehandler的缺点:
3.5 在生产环境中使用hbase
如果是按照row_key检索更新的场景,通常会直接hbase api。
如果是统计分析的场景,更多的还是使用spark和hive查询hbase,简单查询会用phoenix,如果需要频繁扫描hbase表,建议将数据导出至hdfs,减轻hbase服务压力。
如果是在数仓中使用,还是hive查询hbase较多。
4. zookeeper
4.1 简介
zookeeper一款分布式的应用程序协调程序,解决数据一致性问题,它的作用主要有2个:

4.2 zookeeper在hadoop生态中的作用
zookeeper在hadoop中主要作为统一协调中心和统一配置中心存在,说它是整个集群的大管家也毫不为过。
4.3 zookeeper在各个组件中的作用
4.3 zookeeper的缺点
zookeeper采用选举机制选举leader,其它节点作为follower或observer存在,当leader挂掉之后,会重新选举leader,但选举的过程需要时间,对于hadoop这样的计算性集群而言可能不算什么,但对于电商系统这样高速运算的系统而言,集群停摆几秒就可能导致非常严重的后果,所以之前dubbo这样的中间件使用zookeepr作为注册中心就具有一定的风险,只要leader停摆,集群就需要一直等,等待新的leader上线。
5. kafka
5.1 简介
kafka是一款数据流平台,通过kafka数据在各个组件之间流转,kafka也可以作为消息中间件,用于各业务系统之间的解耦。

5.2 kafka的作用
6. elasticsearch
6.1 简介
elasticsearch是一款基于lucene的分布式检索引擎,可以完成复杂的实时检索,稳定可靠、可扩展。
6.2 elasticsearch的作用
elasticsearch的作用就是做大数据实时检索,通过elasticsearch提供restful api可以完成各种复杂的数据检索,甚至可以跨索引检索。
需要注意的是elasticsearch专注的领域是数据检索,如果有统计分析的场景,还是建议使用spark或hive,而且elasticsearch也不属于hadoop生态,需要将数据导入到elasticsearch中。
7. ooize
基于hadoop的分布式调度系统,可以将我们写的mapreduce或spark打包上传,由ooize负责定时执行。
在我们实际生产过程中,还是有很多需要定时执行的spark任务的,这时ooize就排上用场了。
8. sqoop && flume
为什么最后介绍这两个组件,是因为它们和apache pig一样,存在感确实很低。
sqoop是一款将关系型数据库中的数据导入到hadoop平台的etl工具,但几乎没有哪家厂商愿意使用它,要么自己开发etl工具,要么使用kettle、datax等开源的etl工具。
flume是一个高可用的、高可靠的分布式的海量日志采集、聚合和传输的系统。
9. 结语
这是最好的时代,也是最坏的时代。hadoop从诞生至今已不知不觉走过了20多年的时间,英雄迟暮,志在千里!但时代总要继续向前发展,希望大家在拥抱hadoop的同时,也积极去拥抱clickhouse,拥抱doris。


发表评论