dalle2
论文题目:《hierarchical text-conditional image generation with clip latents》(使用clip特征的 层次文本条件图像生成)
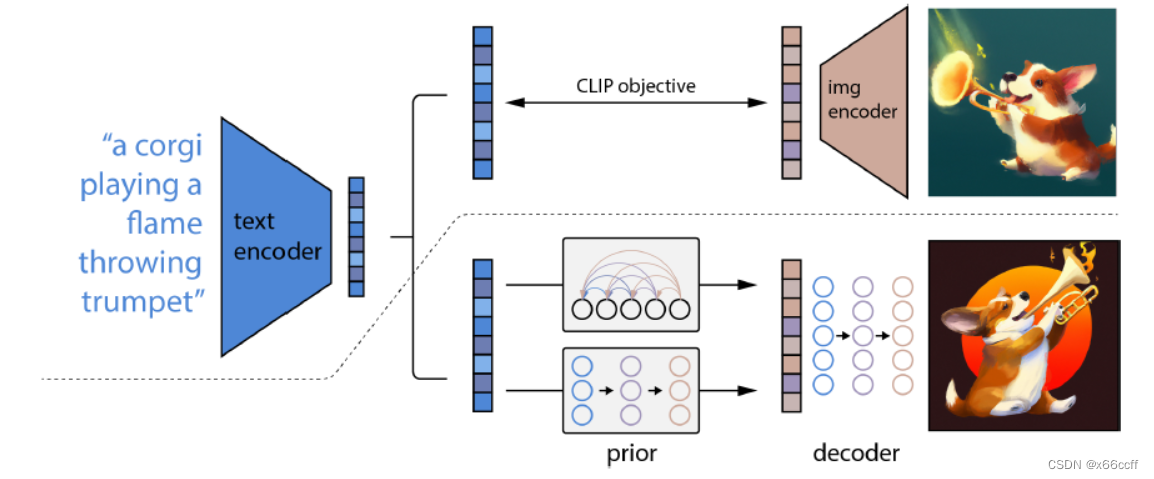
dall·e 2 模型结构
首先训练一个 clip 模型,进行图片-文本对的对比学习,训练得到一个 text encoder 和一个 img encoder,然后将 text encoder 固定住,拿来进行 dall·e 2 的训练。
先经过一个 prior 扩散模型,从文本特征得到图像特征,然后再通过图像特征decode 得到完整的图片。
文本 -> 文本特征 ->[prior模型] -> 图像特征 ->[decoder模型]-> 图像
这段解读来自博文
https://blog.csdn.net/u012193416/article/details/126162618
图像生成模型的研究背景
gan的缺点:保真度高,但是多样性不好。而扩散模型在刚刚提出(数年前)的时候,保真度不及 gan,但是多样性很好。人们为了提高 gan 的生成多样性,从 ae(auto-encoder)中改进得到了 vae(variational auto-encoder),vae 的改进是将 ae 的 bottleneck 从预测一个低维特征图改为了预测是从一个正态分布的哪个位置采样得到的,这样,训练完成之后,就可以将 encoder 部分扔掉,让正态分布随机采样,从而生成不同的图片了。在 vae 之后,又提出了 vq-vae,vq-vae-2 模型,随后出现的就是现在所说的 dalle 模型的第一代(使用 vq-vae 的改进版),然后是dalle 2(使用扩散模型的版本,并使用了很多其他技巧),至此,扩散模型完全打败了gan。
dall·e 2 的解码器
这个 decoder解码器,实际上是一个扩散模型 ddpm (denoising diffusion probabilistic models,去噪声扩散概率模型)
扩散模型的原理:
给定一个图像 x 0 x_0 x0 ,每一次加一点点高斯噪声,变成 x t x_t xt 直到加到 x t x_t xt 变成一个完全是高斯噪声的图像,然后训练一个模型让模型根据 x t x_t xt 图像,预测 x t − 1 x_{t-1} xt−1 图像的情况(实际上,是预测残差图 ϵ \epsilon ϵ ,也就是预测在哪些位置加了噪声,有点 resnet的感觉了,这样训练起来更方便,效果更好),模型因为输入输出是一样的尺寸,所以一般使用 u-net 进行生成,原来用 t t t 步生成图片,就用 t t t 步循环 forward 这个 u-net 网络来进行图片的还原,这样就可以做到从高斯模型还原回一副真实的图片,训练的时候,用( x t − 1 x_{t-1} xt−1 , x t x_{t} xt)构建数据集 ground truth,进行训练,生成的时候,让模型从高斯噪声图片一步步还原(生成)图片。此外,还通过某种方式往这个 u-net 中加入当前的时间信息(目前预测到 t t t 步),来提醒模型当前是需要增加低频(轮廓,色彩)信息还是高频(细节)信息。
训练技巧
dall·e 2的训练过程中还使用到一些训练技巧:
classifier guidance
在从 x t x_{t} xt 生成 x t − 1 x_{t-1} xt−1 的过程中,为了使得生成的图片更加逼真,引入了一个在加了噪声的 imagenet 图像数据集上预训练好的分类器 f f f ,来对 x t x_{t} xt 生成的图片进行分类,看是否和文本特征匹配,并反传梯度给 u-net 模型,让模型在不匹配的地方重点进行生成



发表评论