
3、通用
spark 可以与 sql 、 streaming 及复杂的分析良好结合。 spark 还有一系列的高级工具,包括 spark sql 、 mllib (机器学习库)、 graphx (图计算)和 spark streaming (流计算),并且支持在一个应用中同时使用这些组件

4、随处运行
用户可以使用spark的独立集群模式运行spark,也可以在ec2(亚马逊弹性计算云)、hadoop yarn或者apache mesos上运行spark。并且可以从hdfs、cassandra、hbase、hive、tachyon和任何分布式文件系统读取数据。

5、代码简洁
三、spark 和mapreduce区别
spark是在mapreduce上发展而来,继承了其分布式并行计算的优点并改进了mapreduce明显的缺陷
1.提高了效率
spark把中间数据放到内存中,迭代运算效率高。mapreduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而spark支持dag图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率
2.容错性高
spark引进了弹性分布式数据集rdd (resilient distributed dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,需要进行重建。
相比来说spark更加通用,spark提供了更多的数据集操作类型,处理节点之间通信模型不是向hadoop只采用shuffle模式,而是采用用户可命名,控制中间结果的存储,分区。
3、生态系统
spark拥有更加丰富的生态系统,提供了许多高级库和工具,如spark sql、spark streaming、mllib和graphx等。这些工具使得spark在数据处理、机器学习和图计算等方面更加强大和便捷
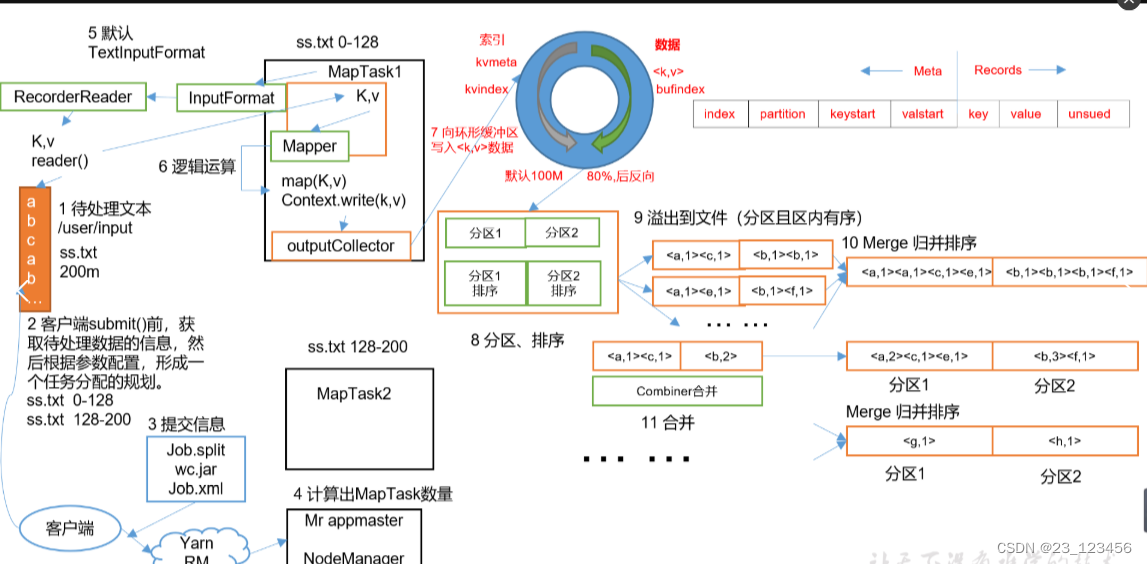
map task详细工作流程
1、copy阶段:reducetask从各个maptask上得到数据(一个reducetask会得到不同maptask中同一个分区的数据)
2、merge阶段:将从maptask上得到的数据进行归并排序,得到一个有序文件
3、reduce阶段:将合并后的有序文件读到reduce,并进行分组,通过用户编写的reduce()函数,得到新的key/value值。
4、write阶段:reducetask通过用户编写的recordwriter,将key/value值输出为目标文件。
四、spark的框架
spark 框架模块包含:spark core、 spark sql、 spark streaming、 spark graphx、 spark mllib,而后四项的能力都是建立在核心引擎之上。
【spark core】:spark的核心,spark核心功能均由spark core模块提供,是spark运行的基础。spark core以rdd为数据抽象,提供python、java、
scala、r语言的api,可以编程进行海量离线数据批处理计算。
【sparksql】:基于sparkcore之上,提供结构化数据的处理模块。sparksql支持以sql语言对数据进行处理,sparksql本身针对离线计算场景。同
时基于sparksql,spark提供了structuredstreaming模块,可以以sparksql为基础,进行数据的流式计算。
【sparkstreaming】:以sparkcore为基础,提供数据的流式计算功能。
mllib:以sparkcore为基础,进行机器学习计算,内置了大量的机器学习库和api算法等。方便用户以分布式计算的模式进行机器学习计算。
【graphx】:以sparkcore为基础,进行图计算,提供了大量的图计算api,方便用于以分布式计算模式进行图计算
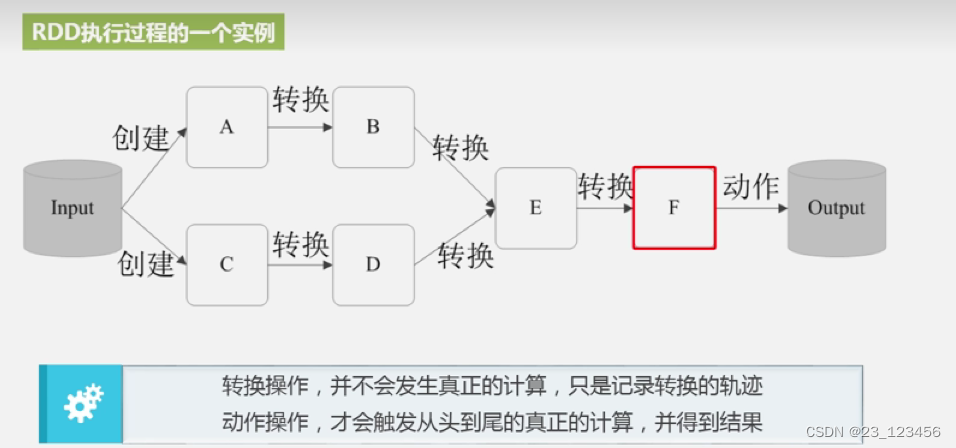
五、spark的核心数据集rdd
1 rdd定义
rdd(resilient distributed dataset)叫做弹性分布式数据集,是spark中最基本的数据抽象,
代表一个不可变类型、可分区、里面的元素可并行计算的集合。可以认为rdd是分布式的"列表list或数组array"(与其说是列表不如说是元组【其本身是不可变类型,只能通过血缘追踪】
六、rdd特性
1.高效的容错性
现有容错机制:数据复制或者记录日志rdd具有天生的容错性:血缘关系,重新计算丢失分区,无需回滚系统,重算过程在不同节点之间并行,只记录粗粒度的操作
2.中间结果持久化到内存,数据在内存中的多个rdd操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是java对象,避免了不必要的对象序列化和反序列化
七、rdd的依赖关系
父rdd的一个分区只被一个子rdd的一个分区所使用就是窄依赖,否则就是宽依赖
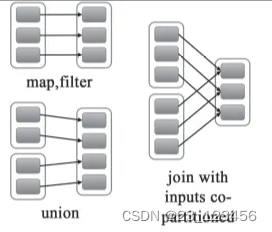
窄依赖是子rdd的一个分区只依赖与某个父rdd中的一个分区
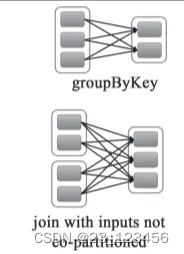
宽依赖是子rdd的每一个分区都依赖于某个父rdd中一个以上的分区
八、scala特性
1)面向对象
scala是一种纯粹的面向对象语言。一个 对象的类型和行为是由类和特征描述的。类通过子类化和灵活的混合类进行扩展,成为多重继承的可靠解决方案。
2)函数式编程
scala提供了轻量级语法来定义匿名函数,支持高阶函数,允许函数嵌套,并支持函数 柯里化。scala 的样例类与模式匹配支持函数式编程语言中的代数类型。scala 的单例对象 提供了方便的方法来组合不属于类的函数。用户还可以使用scala 的模式匹配,编写类似 正则表达式的代码处理可扩展标记语言( extensible markup language, xml )格式的数据。
3)静态类型
scala配备了表现型的系统,以静态的方式进行抽象,以安全和连贯的方式进行使用。系统支持将通用类、内部类、抽象类和复合类作为对象成员,也支持隐式参数、转换和多
4)可扩展
scala提供了许多独特的语言机制,可以以库的形式无缝添加新的语言结构
九、scala安装
1)上传并解压安装spark安装包
tar -zxvf / export/ software/ spark-3.0.3-bin-hadoop2.7.tgz
2)设置环境变量
vim /etc/profile
exportspark_home=/usr/local/soft/spark-3.0.3
export path=$path:${spark_home}/bin
export path=$path:${spark_home}/sbin
source一下是环境变量生效
source /etc/profile
3)修改配置文件
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、oppo等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加vx:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
讲解视频,并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加vx:vip204888 (备注大数据获取)
[外链图片转存中…(img-ewnmrbyg-1713026848881)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!



发表评论