深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
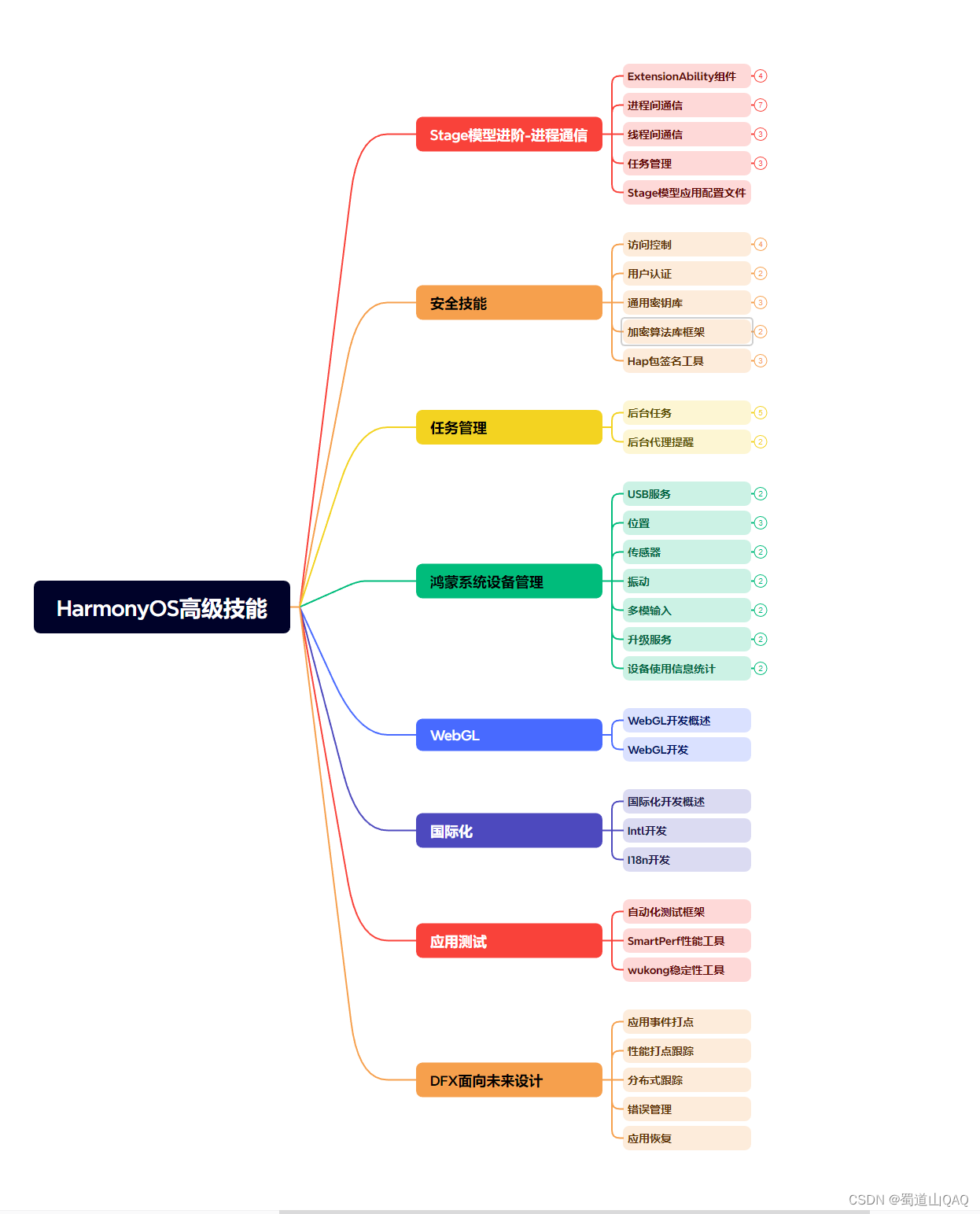

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
`from pil import image
from io import bytesio
import base64
# helper decoder
def decode_base64_image(image_string):
base64_image = base64.b64decode(image_string)
buffer = bytesio(base64_image)
return image.open(buffer)
#run prediction
response = predictor[sd_model].predict(data={
"prompt": [
"a cute panda is sitting on the sofa",
"a photograph of an astronaut riding a horse",
],
"height" : 512,
"width" : 512,
"num_images_per_prompt":1
}
)
#decode images
decoded_images = [decode_base64_image(image) for image in response["generated_images"]]
#visualize generation
for image in decoded_images:
display(image)`
如上,我们试着生成一张可爱的熊猫坐在沙发上面,一个宇航员在骑马,等待几秒钟后,推理完成,得到如下结果:


三、实验二:基于vue3 +aws cloud9搭建一款文本生成图像web应用
通过上面的实践,通过amazon sagemaker的强大算力加持,我们已经成功训练好了diffusion model模型并保存了推理入口,但是光光只能在代码中调用不够,下面我们通过vue3+flask通过调用模型来搭建一款简单的文本生成图像demo。
3.1、在 aws cloud9 创建后端 flask服务
亚马逊为我们提供了一种和vscode web版相同的基于云的集成开发环境 (ide):aws cloud9,我们首先在搜索栏搜索到cloud9,点击新建一个云环境:
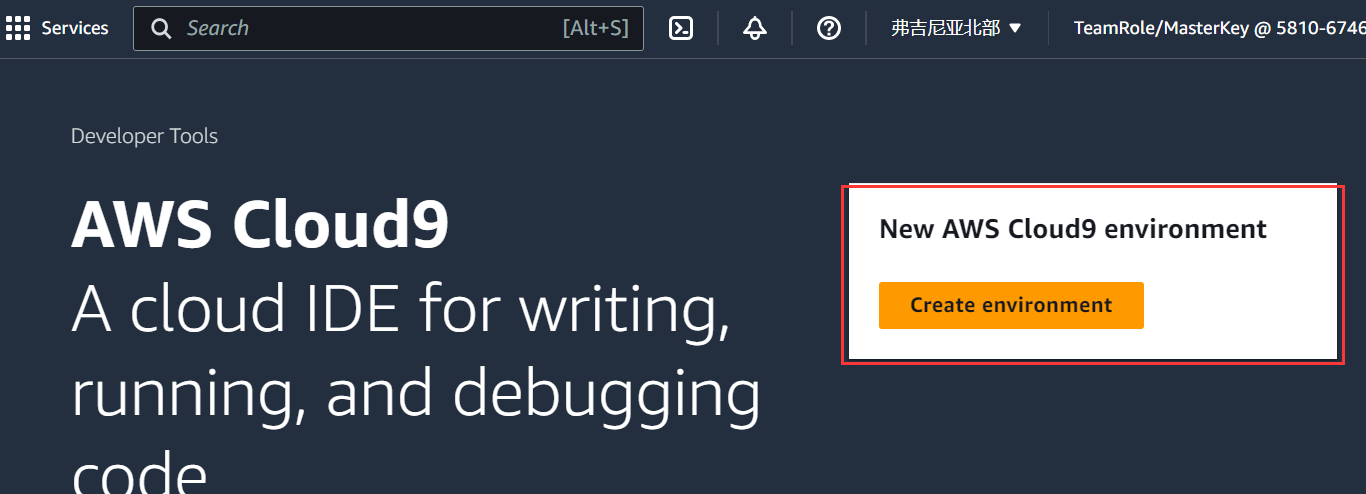
创建好之后,我们可以在environments中打开cloud9ide
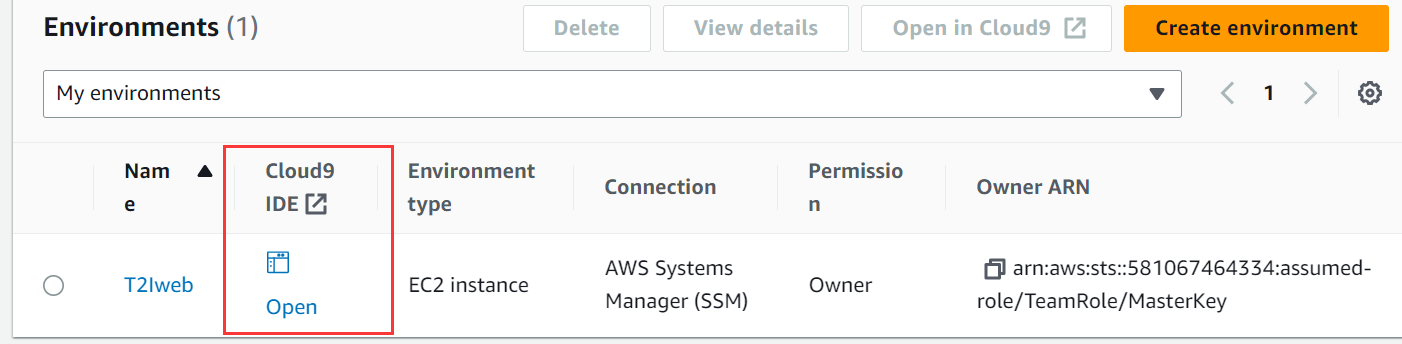
与vs code web类似,aws cloud9包括一个代码编辑器、调试程序和终端,并且预封装了适用于 javascript、python、php 等常见编程语言的基本工具,无需安装文件或配置开发计算机,即可开始新的项目。
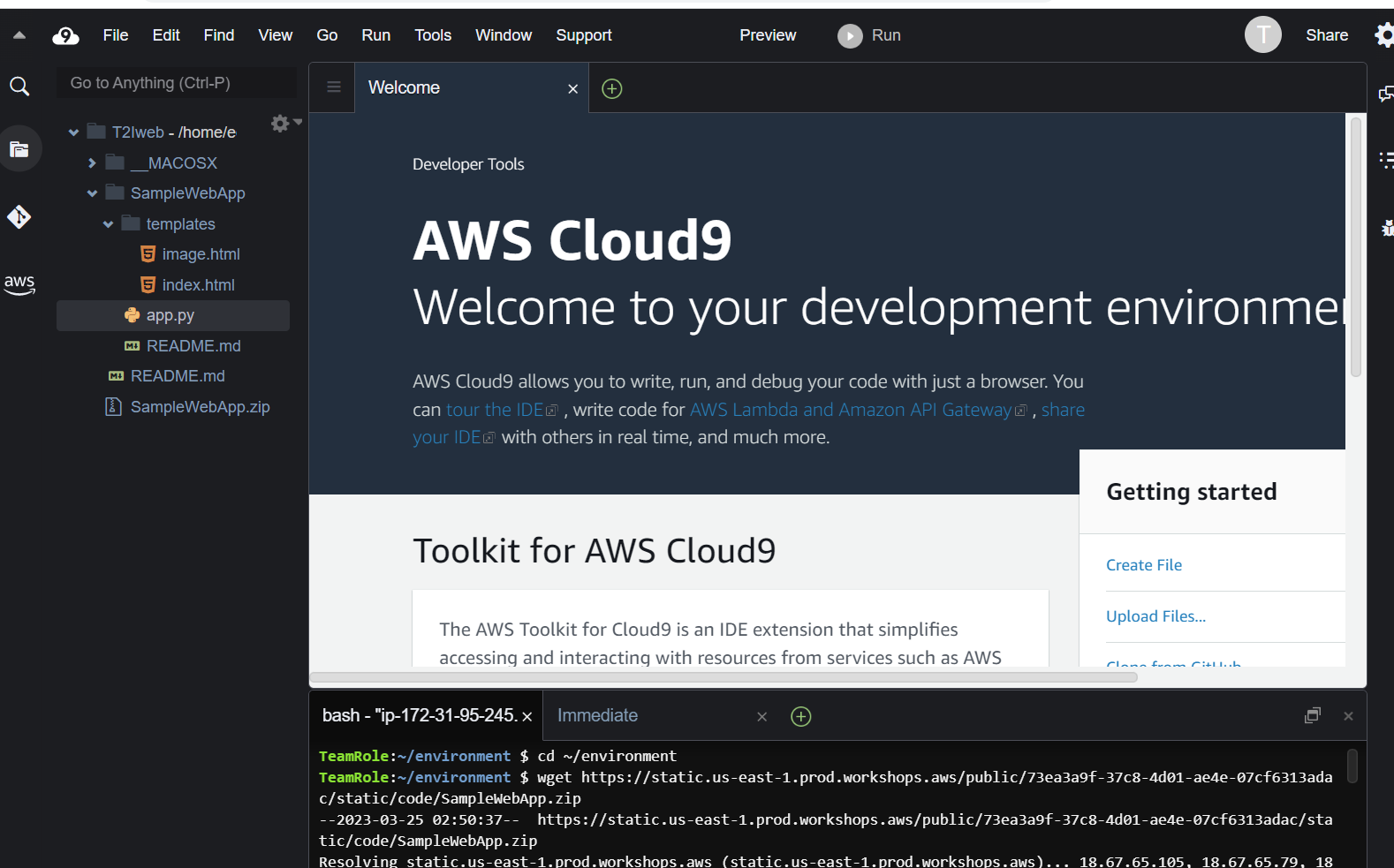
在下面的终端,我们输入以下代码,下载并解压samplewebapp文件夹
`cd ~/environment
wget https://static.us-east-1.prod.workshops.aws/public/73ea3a9f-37c8-4d01-ae4e-07cf6313adac/static/code/samplewebapp.zip
unzip samplewebapp.zip`
该文件夹包含以下内容:
-
后端代码 app.py:接收前端请求并调用 sagemaker endpoint 将文字生成图片。
-
两个前端html文件 image.html 和 index.html。
要运行此后端服务,首先需要安装相应环境,使用pip3安装flask和boto3环境:
`pip3 install flask
pip3 install boto3`
安装成功之后,点击左侧的app.py文件,点击 aws cloud9 上方的 run 按钮运行代码,这样代码就可以调用amazon simple storage service (amazon s3)中已经保存好的endpoint进行文本生成图像推理,运行如下:
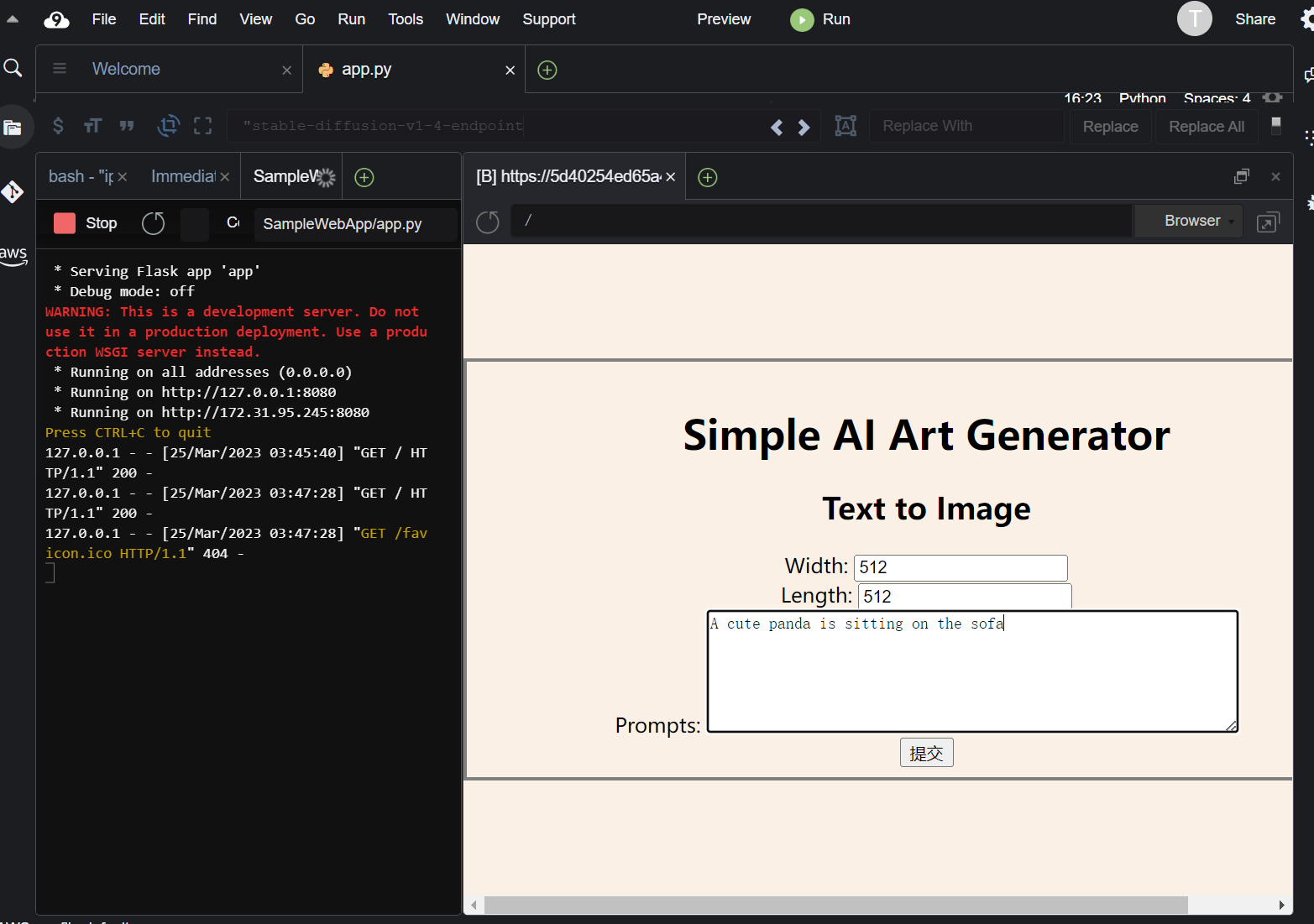
左侧可以看到后台为前端提供了8080端口,右侧前端页面提供了简单的demo,width和length代表输出图像的长宽,prompt为输入的文本,同样测试a cute panda is sitting on the sofa这条语句,成功输出:

3.2、在本机使用前端vue搭建web demo
光在服务器调用不过瘾,我们尝试在本机搭建一款vue demo,然后调用aws cloud9的flask服务。如果你不想从零开始搭建,可以使用git clone,克隆我上传的,然后直接跳到3.3继续实验流程。
`git clone https://github.com/heavenhjs/t2iweb-demo.git`
首先我们打开vscode,输入npm create vite@latest用vite初始化一款vue项目,分别选择vue、ts作为技术栈:
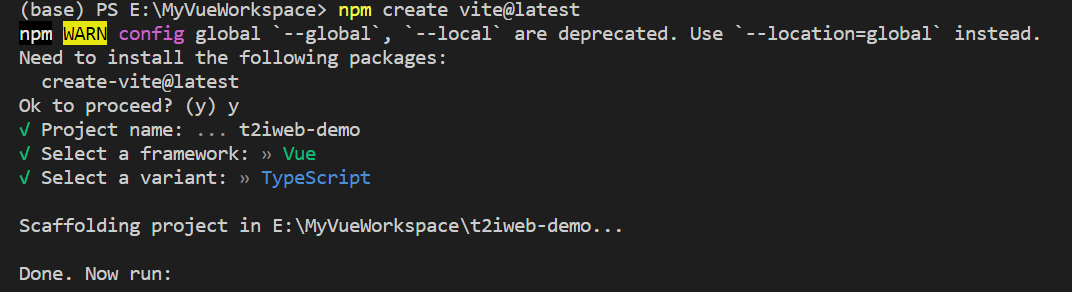
初始化好后,输入npm i安装相应依赖,然后输入npm install element-plus --save和npm install axios安装element-plus、axios依赖

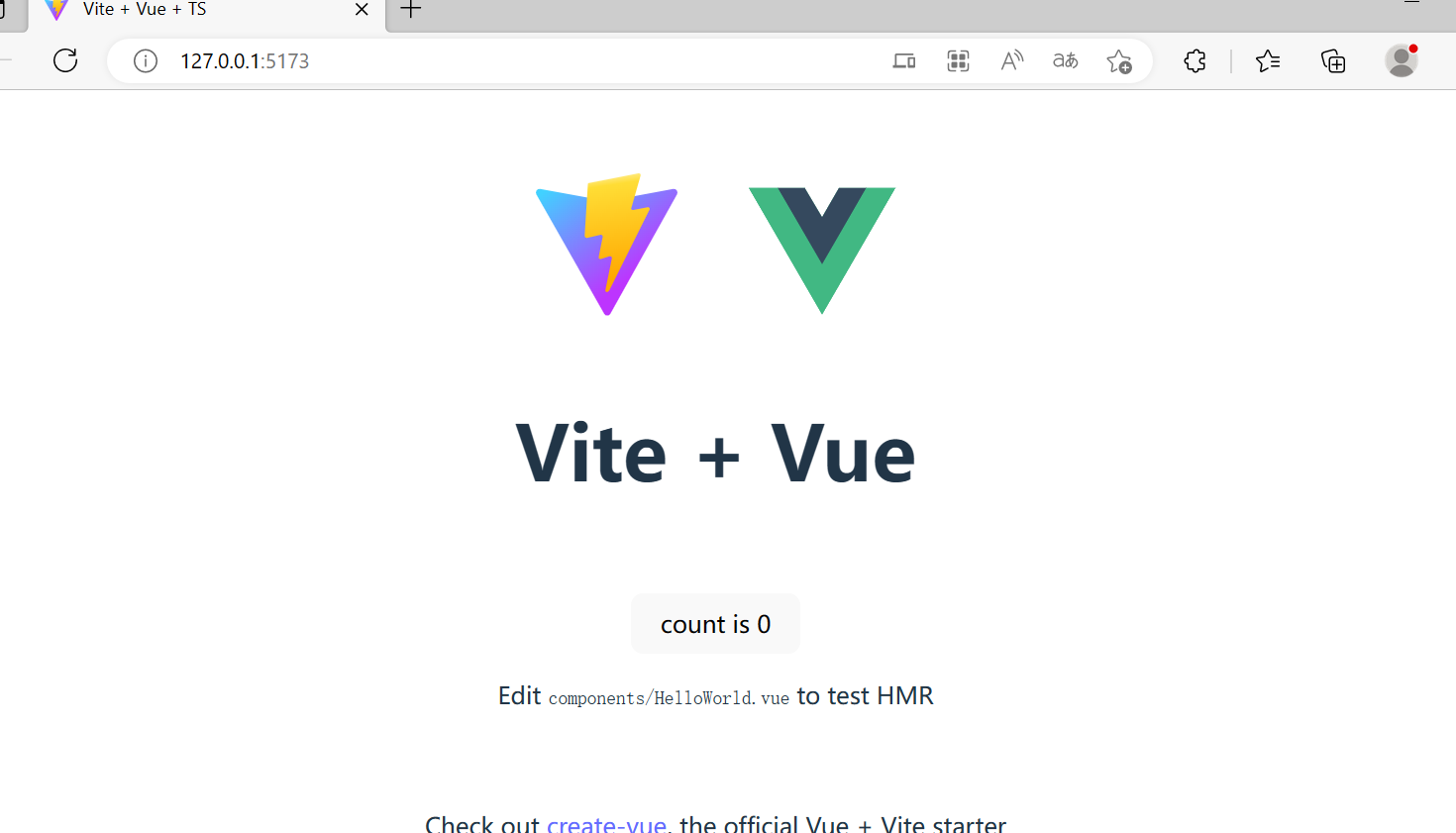
然后输入npm run dev启动项目,一个初始化项目就建好了:
接下来,我们把原始给的东西清理一下,然后开始写一个demo,需要设计一个表单,然后在表单下方设计一个值专门用于渲染后端传回来的html富文本,项目结构设计的比较简单如下所示,api放的是调用后台flask服务的接口,components里做了一个t2i的组件,utils里是封装的axios服务,另外还需要在vite.config.ts里配置跨域。
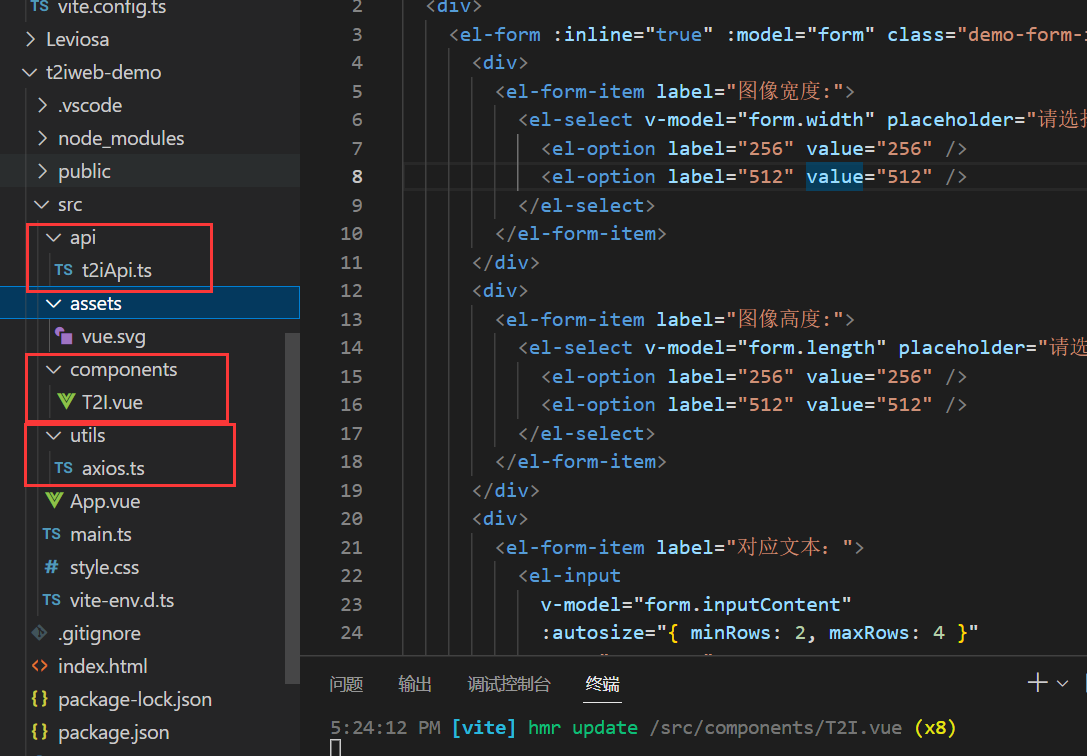
主要代码如下:
`// t2i.vue
<template>
<div>
<el-form :inline="true" :model="form" class="demo-form-inline">
<div>
<el-form-item label="图像宽度:">
<el-select v-model="form.width" placeholder="请选择">
<el-option label="256" value="256" />
<el-option label="512" value="512" />
</el-select>
</el-form-item>
</div>
<div>
<el-form-item label="图像高度:">
<el-select v-model="form.length" placeholder="请选择">
<el-option label="256" value="256" />
<el-option label="512" value="512" />
</el-select>
</el-form-item>
</div>
<div>
<el-form-item label="对应文本:">
<el-input
v-model="form.inputcontent"
:autosize="{ minrows: 2, maxrows: 4 }"
type="textarea"
placeholder="请输入想要生成的文本"
/>
</el-form-item>
</div>
<el-form-item>
<el-button type="primary" @click="onsubmit">生成</el-button>
<el-button type="primary" @click="onclean">清空</el-button>
</el-form-item>
</el-form>
</div>
<p v-html="image"></p>
</template>
<script setup lang="ts">
import { reactive, ref } from "vue";
import { t2i } from "../api/t2iapi";
const form = reactive({
inputcontent: "",
width: "",
length: "",
});
let image = ref("<p>请输入信息后,点击生成</p>");
const onsubmit = () => {
console.log("submit!");
t2i(form).then((res: any) => {
console.log(res.data);
image.value = res.data;
});
};
const onclean = () => {
form.inputcontent = "";
form.length = "";
form.width = "";
image.value = "<p>请输入信息后,点击生成</p>";
};
</script>
<style lang="less"></style>`
`// t2iapi.ts
import axios from "../utils/axios";
/**
* @name 用户管理模块
*/
// 获取用户列表
const port1 = "/api";
// t2i
export const t2i = (parms: any) => {
const form = new formdata();
form.append("inputcontent", parms.inputcontent);
form.append("width", parms.width);
form.append("length", parms.length);
return axios.post(port1 + `/predictor`, form);
};`
3.3、使用axios请求cloud9的文本生成图像服务
为了安全,aws cloud9 分配给环境的预览标签页中的 url,只能在当环境的 ide 处于打开状态并且应用程序正在同一个 web 浏览器中运行时才有用,所以我们要通过公网ip和端口号的方式暴露接口。
为此首先我们要为实例修改安全组,打开8080端口,允许其传输数据,这样才可以访问到后端写好的flask服务,具体步骤可以看手册这一章:
打开8080端口后,可以用postman测试一下,在body里面,加入form-data,并输入对应的key和value,点击send发送,显示200,下方栏返回html且img当中有值,则配置成功:
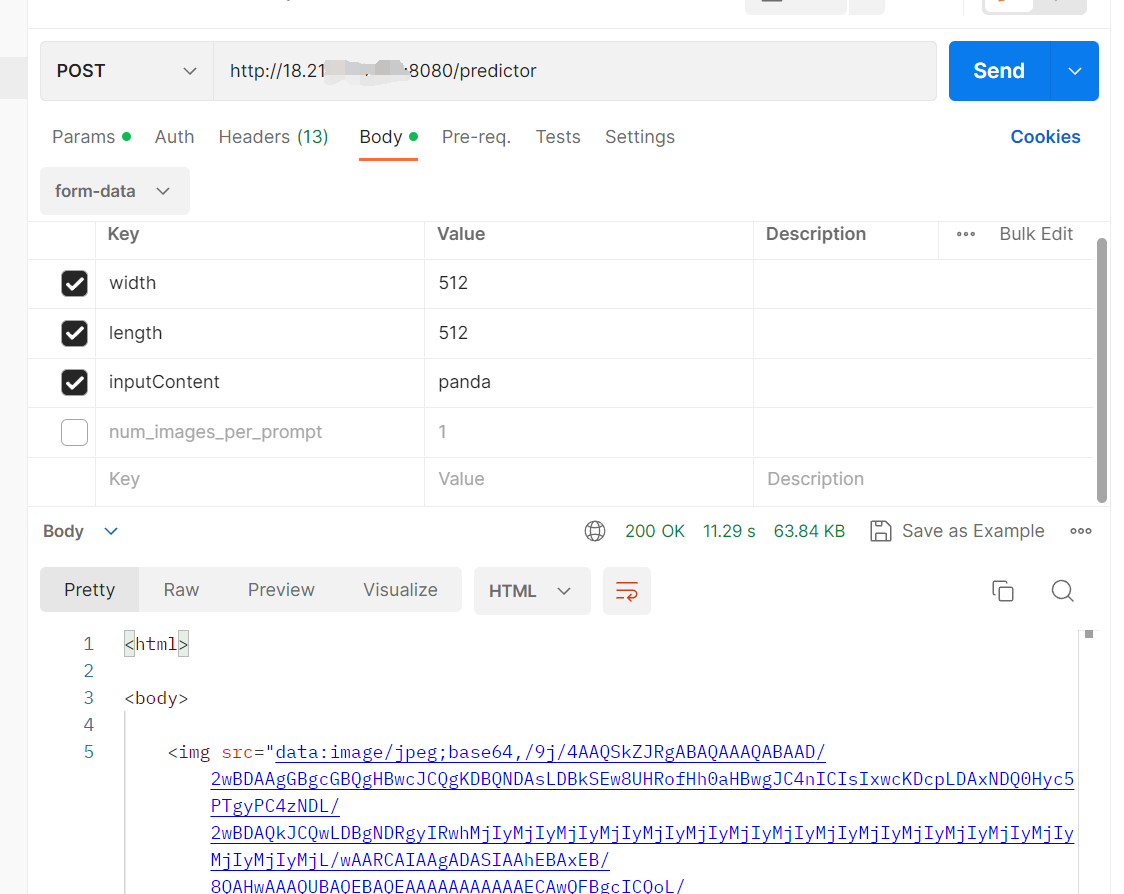
成功之后,我们就可以使用axios来请求cloud9的服务,这就需要在前端配置一下接口的ip,打开vite.config.ts,其中target 需要改为自己acl的公网ip+端口号,这样就可以在本机上调用到flask的服务啦!
`import { defineconfig } from "vite";
import vue from "@vitejs/plugin-vue";
// https://vitejs.dev/config/
export default defineconfig({
plugins: [vue()],
server: {
//服务器主机名
port: 8080,
open: true,
hmr: {
host: "127.0.0.1",
port: 5173,
},
// 代理跨域
proxy: {
"/api": {
target : "这里输入亚马逊网络对应acl的公网ip+端口号如:http://18.222.222.222:8080",
changeorigin: true,
// 将/api去掉
rewrite: (path: string) => path.replace(/^\/api/, ""),
},
},
},
});`
最后输入"npm run dev"运行项目,效果如下:
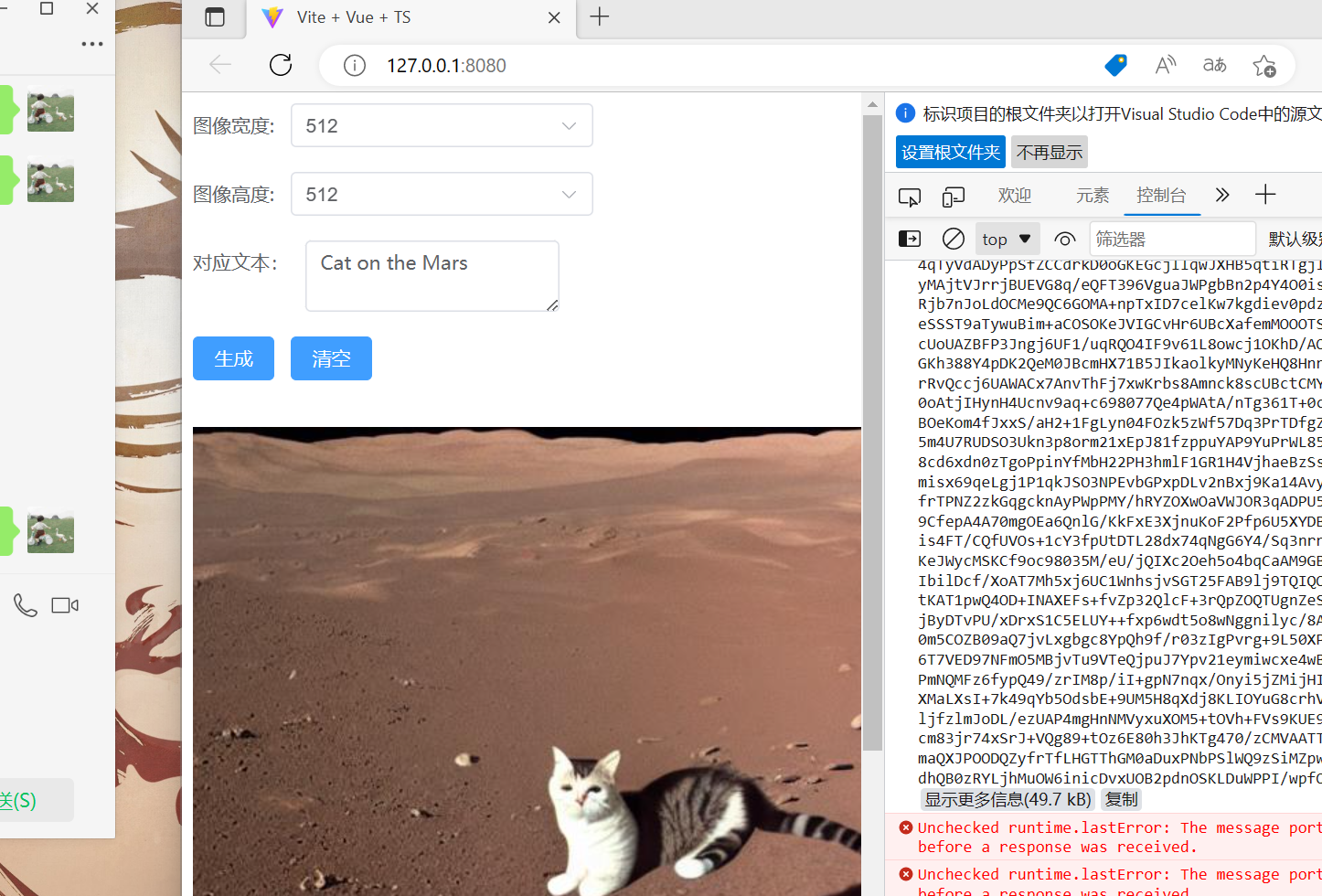
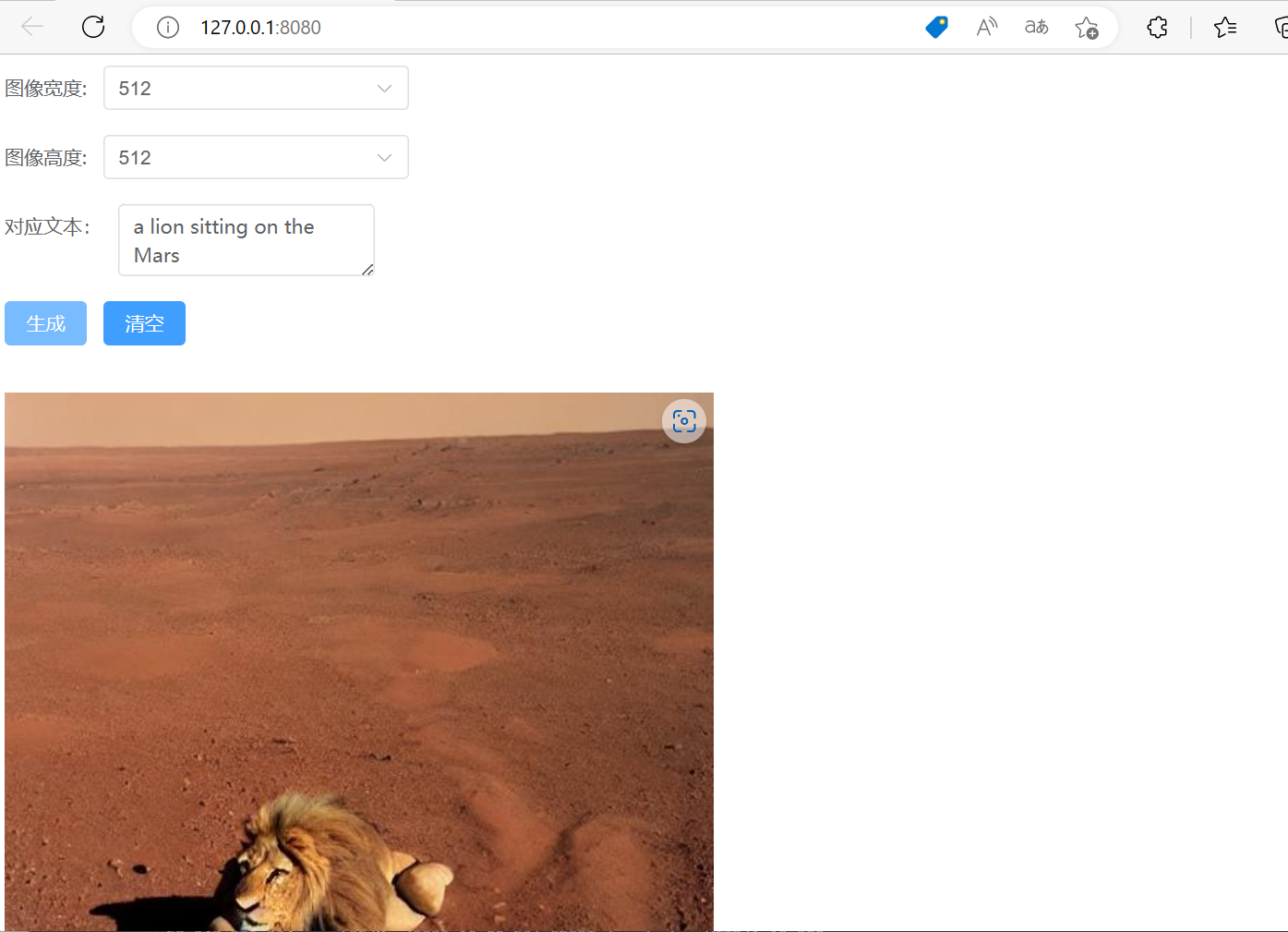
3.4、避坑指南——注意事项和经验总结
问题1:配额不足或者无法申请配额
您的请求有问题。请参阅以下详细信息。user: arn:aws:sts::581067464334:assumed-role/teamrole/masterkey is not authorized to perform: servicequotas:listawsdefaultservicequotas with an explicit deny in an identity-based policy
解决方案:更换地区为美国东部
点击链接进入配额列表,搜索:ml.g4dn.xlarge for endpoint usage,点击请求申请增加配额。

问题2:404错误
可能是公网ip和端口号不对,可能是安全组的准入规则没有设置对,认真看一下手册,打开8080端口或者更换其他端口。
问题3:500 bad request
request传入的参数不对,检查一下表单输入的值和传输过去的数据是否符合规范,也有可能是后端flask服务断联了,重启一下flask服务就好了。
其他问题可以参考实验手册:https://dev.amazoncloud.cn/activity/activitydetail?id=638ea0193b67dd77d6cdb221&catagoryname=buildon
四、 总结
4.1、stable diffusion模型的表现和局限性
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
38ea0193b67dd77d6cdb221&catagoryname=buildon
四、 总结
4.1、stable diffusion模型的表现和局限性
[外链图片转存中…(img-zze3y07w-1715902231984)]
[外链图片转存中…(img-grbwoptu-1715902231985)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!



发表评论