二手房挂牌房源,是我们分析房地产价格分布和走势的重要参考依据。那么,我们应该如何爬取这些房源数据,并用于数据分析和可视化呢?今天我们以贝壳二手房为例,来介绍一下基本的步骤。
一、操作环境
1. 浏览器:safari浏览器(版本:17.31)
2. python版本:python3.12
3. 开发环境:pycharm 2023.3(community edition)
4. 操作系统:macos 14.3(sonoma)
二、网页解析
1. 打开某城市的房源界面(本文以“合肥市”为例)
合肥二手房_合肥二手房出售买卖信息网【合肥贝壳找房】 https://hf.ke.com/ershoufang/rs/
https://hf.ke.com/ershoufang/rs/
2. 观察网页布局:属于典型的“分页列表式”、“静态网页”。
这类网页的爬取策略,一般是:获取总页码数➡️爬取第1页的数据➡️循环爬取每页的数据
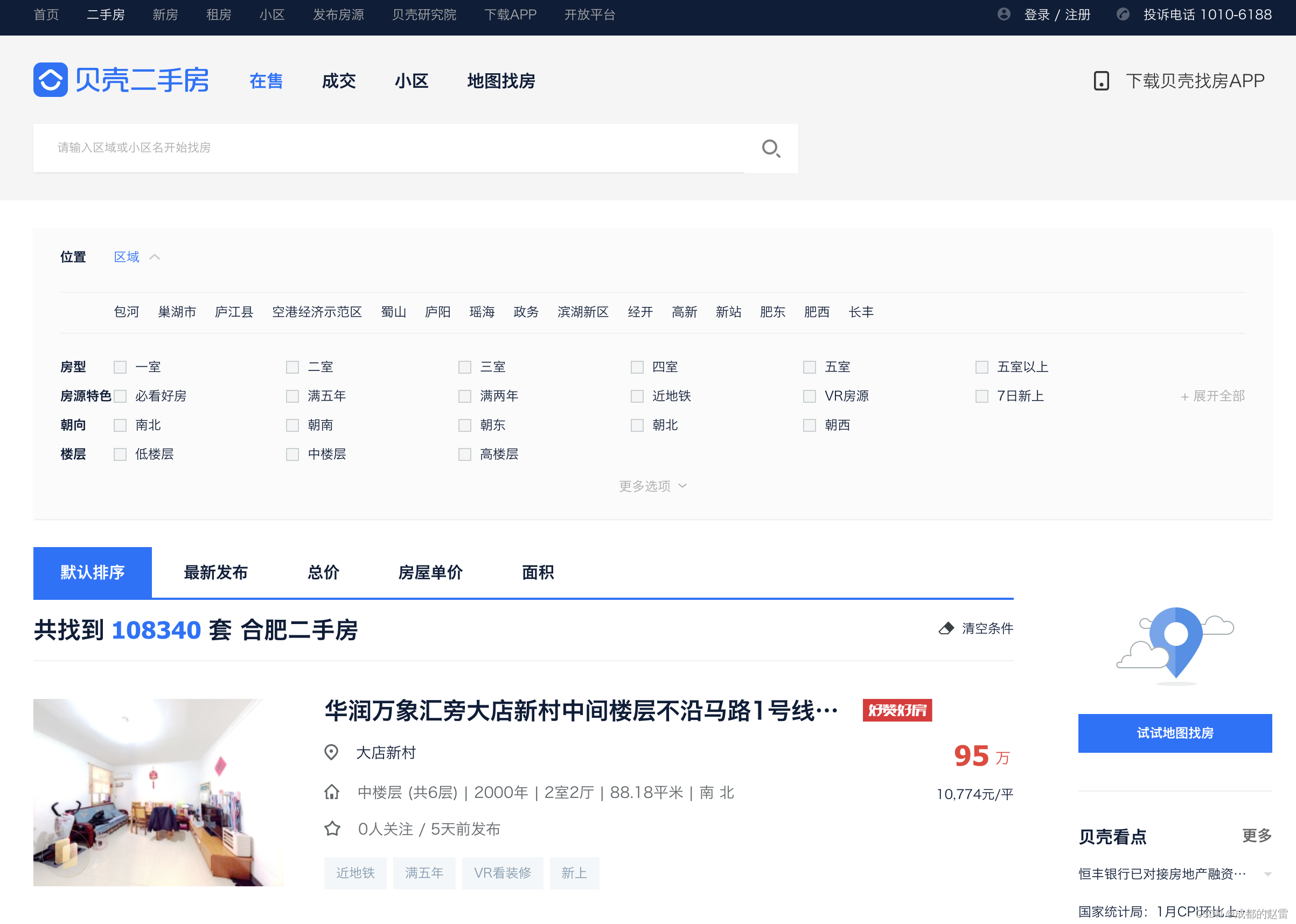
3. 寻找数据源:
页面空白处“点击右键”——“检查元素”,进入开发者工具。选择”网络“标签页,然后刷新网页,获取所有网页加载项。对列表中的所有加载项依次进行预览,寻找数据源地址。
在这里,我们很容易就发现,数据源网址为:https://hf.ke.com/ershoufang/pg100/
其实这就是该网页的网址。这意味着,房源数据就在网页html代码中。
这类网页数据的爬取策略,一般是:爬取网页html代码➡️定位并筛选出数据所在模块➡️循环筛选出每一行数据➡️对每行数据进行清洗、分类整理
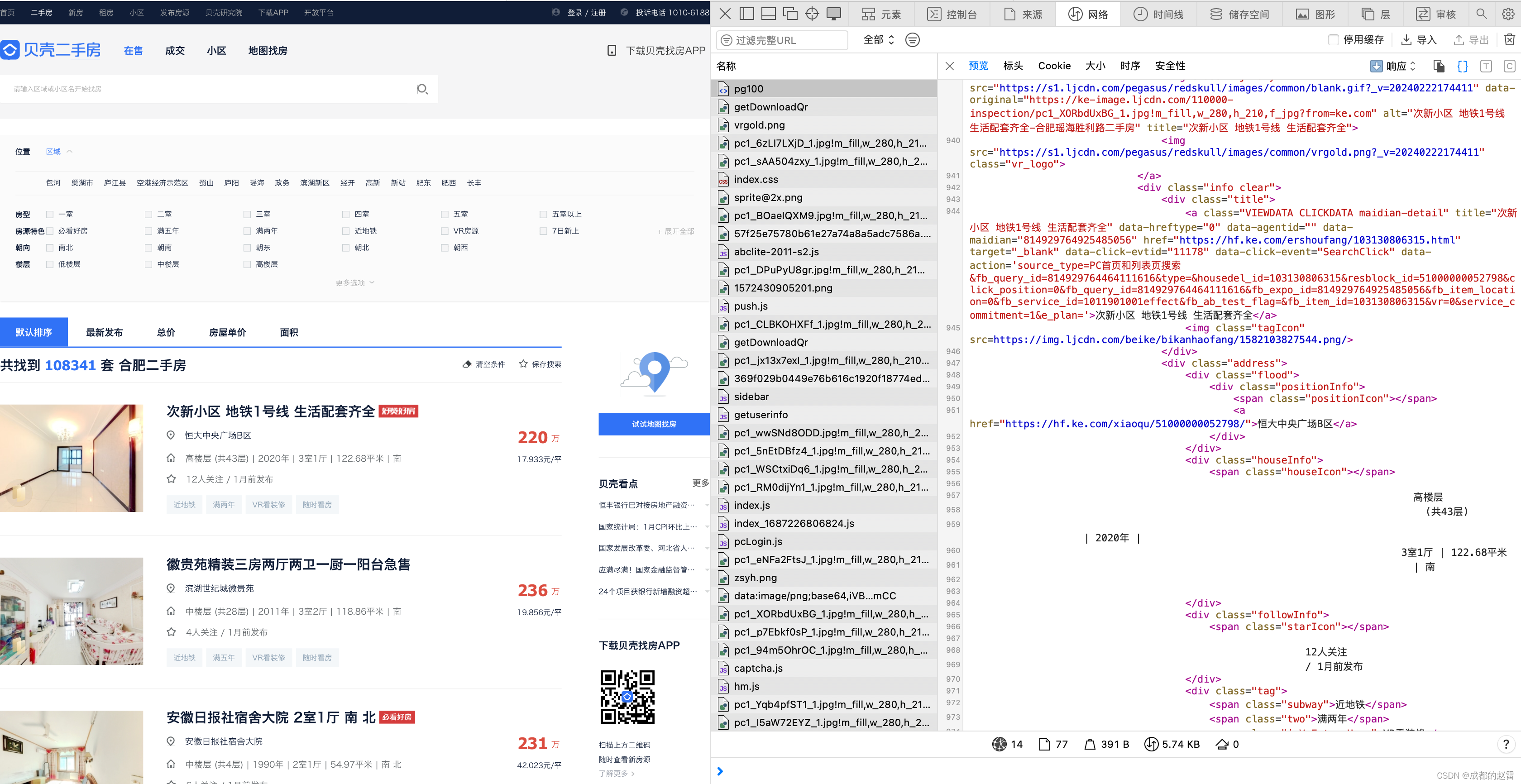
4. 估计可爬取的数据量:
(1)总数据量:108340条 (“共找到 1083410套合肥二手房” )
(2)单页数据量:30条
(3)总页码数:100页
(4)实际可爬取数据量:3000条
由此可见,网页端的“贝壳二手房源列表”,最多仅展示3000条数据。虽然这个数量与实际数量差距较大,但如果仅用于学习研究目的,这些样本完全足够。
三、数据爬取
(一)获取各城市二手房源列表的网址、总页码数
1. 进入贝壳二手房“城市选择”的界面
3. 导入工具包
# coding:utf-8
import pandas as pd
from lxml import etree
import requests
import numpy
import randoms
from bs4 import beautifulsoup4. 定义爬虫函数
def patch(url):
header = {'user-agent': 'mozilla/5.0 (macintosh; intel mac os x 10_15_7) applewebkit/605.1.15 (khtml, like gecko) version/17.3.1 safari/605.1.15'}
request=requests.get(url=url, headers=header)
request.encoding='utf8'
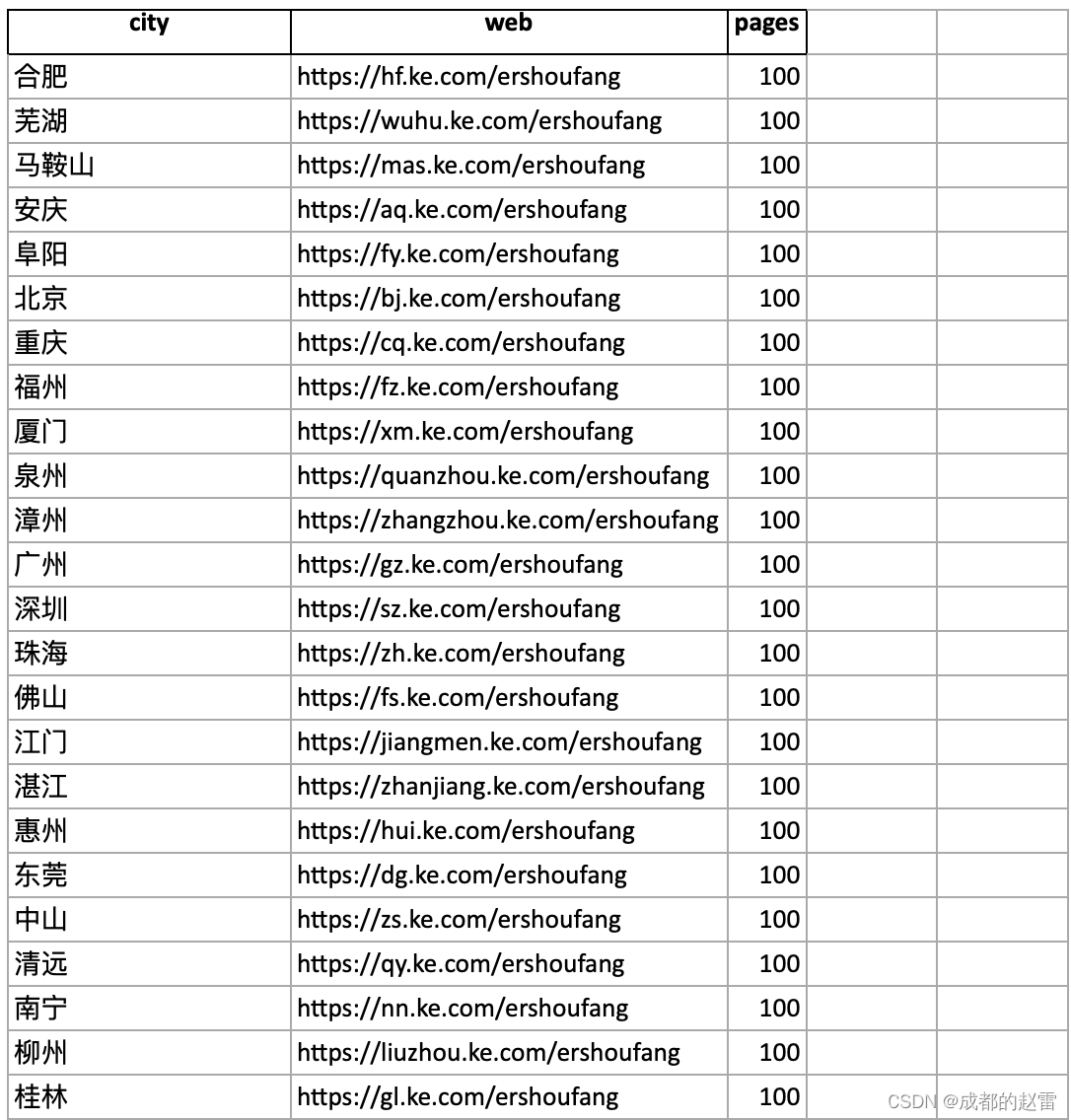
return request5. 获取各城市二手房列表的网址、总页码数,并导出为表格“xls.xlsx”。
k=0
website='https://www.ke.com/city/'
xls=pd.dataframe(columns=['city','web','pages'])
soup = beautifulsoup(patch(website).text, 'lxml')
list = soup.find_all(name='div', attrs={'class': 'city_list'})
for x in range(len(list)):
ls = list[x].find_all(name='li', attrs={'class': 'clickdata'})
for y in range(len(ls)):
city = ls[y].text
web = ls[y].find('a').get('href').replace('//', 'https://')+'/ershoufang'
soups = beautifulsoup(patch(web).text, 'lxml')
try:
page = soups.find(name='div', attrs={'class': 'page-box house-lst-page-box'}).get('page-data')
except attributeerror:
continue
pages=eval(page)['totalpage']
print(city,web,pages)
xls.loc[k]=[city,web,pages]
k=k+1
xls.to_excel('xls.xlsx',index=false)
6. 打开表格,查看是否成功爬取数据
(二)获取各城市二手房源数据
1. 导入工具包
# coding:utf-8
import datetime
import pandas as pd
from lxml import etree
import requests
import numpy
import randoms
from bs4 import beautifulsoup2. 定义爬虫函数
def patch(url):
header = {'user-agent': 'mozilla/5.0 (macintosh; intel mac os x 10_15_7) applewebkit/605.1.15 (khtml, like gecko) version/17.3.1 safari/605.1.15'}
request=requests.get(url=url, headers=header)
request.encoding='utf8'
return request3. 导入各城市房源网址、列表数,爬取数据并分城市保存为excel文件
k=0
df=pd.read_excel('xls.xlsx',engine='openpyxl')
for x,y,c in zip(df['web'],df['pages'],df['city']):
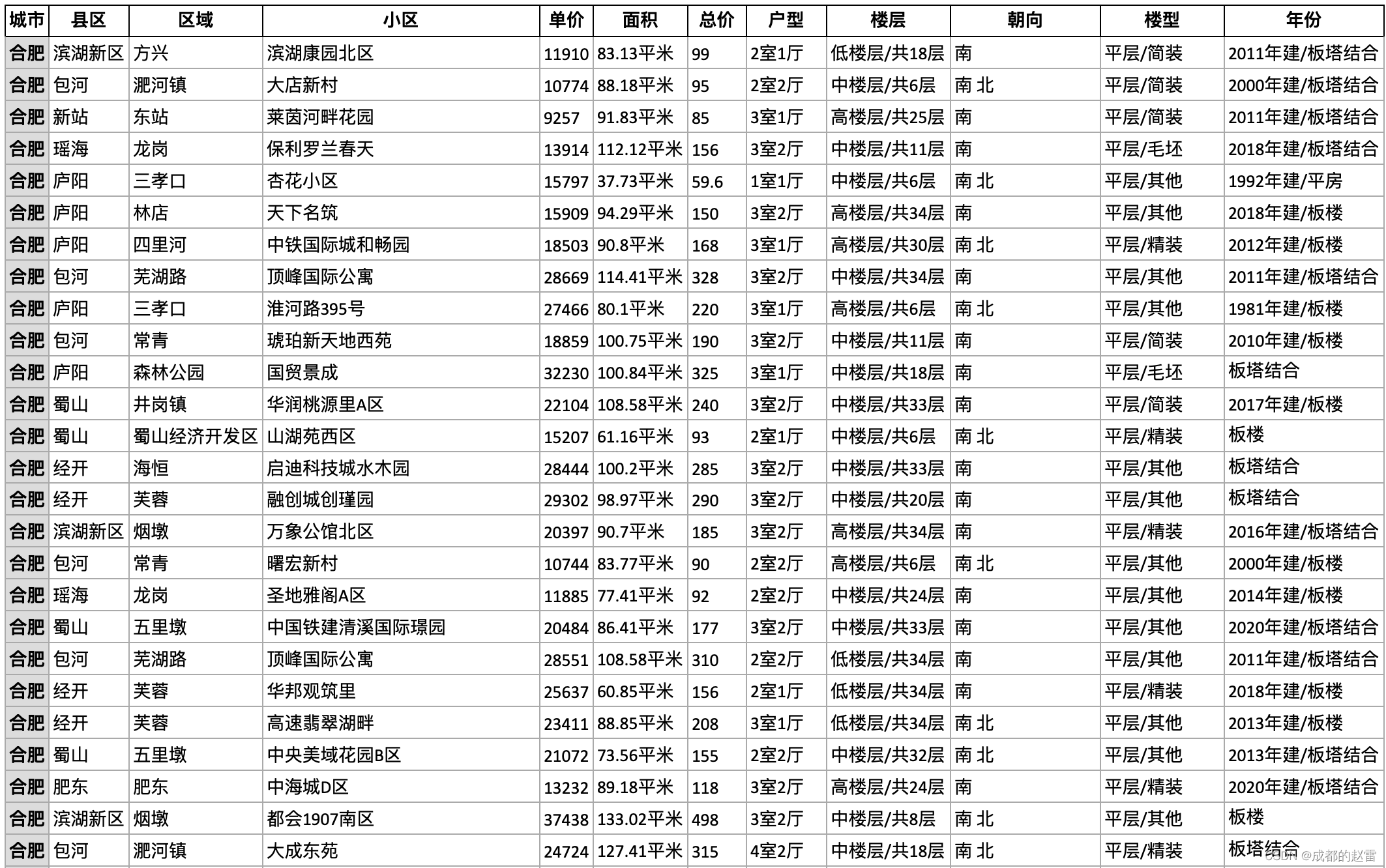
xls = pd.dataframe(columns=['城市', '县区', '区域', '小区', '单价', '面积', '总价', '户型', '楼层', '朝向', '楼型', '年份'])
print('开始获取:'+c)
before=datetime.datetime.now()
for z in range(1,y+1):
soup=beautifulsoup(patch(x+'/pg'+str(z)).text,'lxml')
list=soup.find_all(name='a',attrs={'class':'viewdata clickdata maidian-detail'})
for a in range(len(list)):
website=list[a].get('href')
sop=beautifulsoup(patch(website).text,'lxml')
prices=sop.find(name='div', attrs={'class': 'price'}).find(name='span', attrs={'class': 'total'}).text
unitprices = sop.find(name='div', attrs={'class': 'unitprice'}).find(name='span', attrs={'class': 'unitpricevalue'}).text
rooms=sop.find(name='div',attrs={'class':'room'}).find(name='div',attrs={'class':'maininfo'}).text
floors=sop.find(name='div',attrs={'class':'room'}).find(name='div',attrs={'class':'subinfo'}).text
navis=sop.find(name='div',attrs={'class':'type'}).find(name='div',attrs={'class':'maininfo'}).text
types=sop.find(name='div',attrs={'class':'type'}).find(name='div',attrs={'class':'subinfo'}).text
squares=sop.find(name='div',attrs={'class':'area'}).find(name='div',attrs={'class':'maininfo'}).text
years=sop.find(name='div',attrs={'class':'area'}).find(name='div',attrs={'class':'subinfo'}).text
communities=sop.find(name='div',attrs={'class':'communityname'}).find(name='a',attrs={'class':'info'}).text
county=sop.find(name='div',attrs={'class':'areaname'}).find_all(name='a')
for b in range(len(county)):
counties=county[0].text
areas=county[1].text
xls.loc[k]=[c,counties,areas,communities,unitprices,squares,prices,rooms,floors,navis,types,years]
k=k+1
print(c+':第'+str(z)+'页已完成')
xls.to_excel(excel_writer=str(c)+'.xlsx',index=false)
after=datetime.datetime.now()
print(c+':已完成'+',耗时'+str(after-before))四、运行结果
1. 运行代码时的效果如下:
(注意:数据爬取时间会比较长,请耐心等待)
2. 爬取的数据效果如图

发表评论